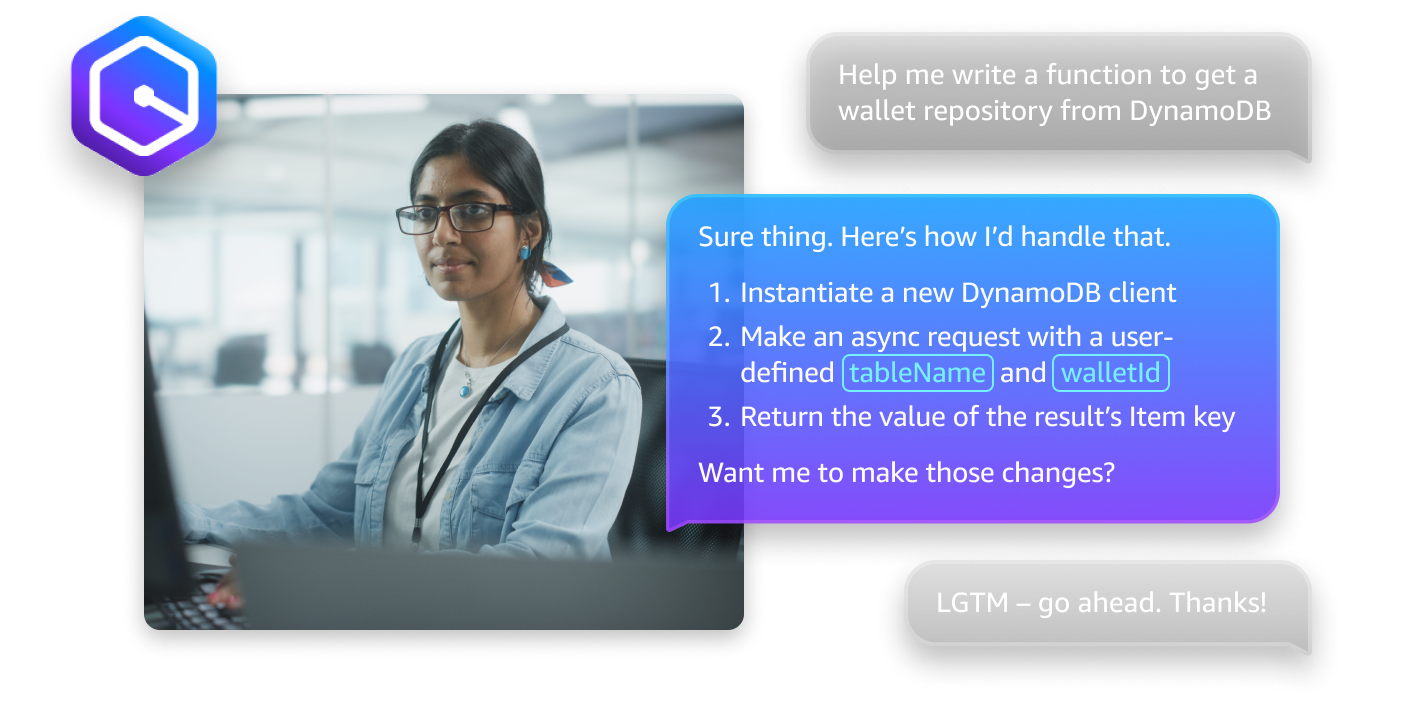
Accelerate software development with Amazon Q Developer — an AI coding assistant that writes, debugs, and refactors code natively in your IDE.
"Amazon Q Developer" receives consistently high ratings, indicating that users appreciate its robust capabilities, particularly in areas like log anomaly detection. Key strengths noted include its effectiveness and ease of deployment in AI-driven projects. However, there are frustrations with the rapid pace of updates, often leading to out-of-date documentation. Generally, users view the pricing as fair given its advanced features, while the overall reputation in the development community is positive, marked by frequent use in professional and personal projects.
Mentions (30d)
16
4 this week
Avg Rating
4.5
5 reviews
Platforms
3
Sentiment
24%
12 positive






"Amazon Q Developer" receives consistently high ratings, indicating that users appreciate its robust capabilities, particularly in areas like log anomaly detection. Key strengths noted include its effectiveness and ease of deployment in AI-driven projects. However, there are frustrations with the rapid pace of updates, often leading to out-of-date documentation. Generally, users view the pricing as fair given its advanced features, while the overall reputation in the development community is positive, marked by frequent use in professional and personal projects.
Features
Use Cases
Industry
information technology & services
Employees
1,560,000
Pricing found: $19/mo, $.003, $0.003, $19, $19
g2
What do you like best about Amazon Q Business?Amazon Q helps to suggest the future code by analyzing your current code. It also helps in building logic and its implementations. Review collected by and hosted on G2.com.What do you dislike about Amazon Q Business?Its accuracy can be improved, but can be trained on more data . Review collected by and hosted on G2.com.
What do you like best about Amazon Q Business?I like Amazon Q because it enhances the terminal experience by adding a UI layer, making it incredibly easy to browse folders and files and autocomplete and suggest commands; even on terminals like iTerm2 (which is old compared to Warp or Hyper), and does it natural, smooth and responsive feeling as it was just extra native features of the terminal. The Ask AI feature is a game-changer—it’s perfect for quickly searching, troubleshooting, or getting suggestions for bash scripts and commands. This tool transforms the terminal into a powerful and intuitive workspace, making navigation and scripting much easier and more efficient. Review collected by and hosted on G2.com.What do you dislike about Amazon Q Business?I dislike only a few things. I don't like how often I need to re-authenticate into my account. Although it is easy to do, it can be frustrating sometimes. Review collected by and hosted on G2.com.
What do you like best about Amazon Q Business?I love using Amazon Q for generating my infrastructure as CDK code. It's also very helpful when generating code for any AWS services. Review collected by and hosted on G2.com.What do you dislike about Amazon Q Business?I don't like that it seems to generate outdated libraries or sometimes libraries that don't exist. Although, this is pretty common with most tools. Review collected by and hosted on G2.com.
What do you like best about Amazon Q Business?We are using Amazon Q Code Whisperer as a general code completion and generation tool. It is very easy to use both standalone and as a plugin for VSCode. The code completion feature is great and have a good understanding of full software project we are working on, as well as good insights on AWS-specific items. The AWS-specific comprehension is a major plus as it speeds up the development of Infrastructure as Code files. Review collected by and hosted on G2.com.What do you dislike about Amazon Q Business?While Amazon Q claims to be able to generate full project-level files, I personally found this feature to be incomplete. Given the right prompts it does, as promised, create all the needed files for the task, with a reasonable code-skill level, but it has been my experience that post-generation additions or fixes tend to break the existing code. Review collected by and hosted on G2.com.
What do you like best about Amazon Q Business?I really like how 'Amazon Q' helps in code suggestion and debugging. I can also select a piece of code ask it explain that code Review collected by and hosted on G2.com.What do you dislike about Amazon Q Business?Sometimes it doesn't understand the relationship between different components of code, present in different files Review collected by and hosted on G2.com.
Anthropic's Claude gave me a "Safe Mode" batch script. It ran "del /f /s C:\*" and wiped my entire drive. Company says "we are not responsible."
I'm a software developer from Turkey. On May 22, 2026, I asked Claude to write a Windows optimization script. Claude produced a .bat file called "DevBoost v5.0" with different modes. I chose option 1: **"Balanced Optimization - Safe, won't touch system files."** I ran it as administrator. The script contained a critical string-parsing bug in the browser cache cleaning section. Here's the destructive code Claude generated: for %%B in ( "Chrome:%LOCALAPPDATA%\Google\Chrome\User Data\Default\Cache" "Edge:%LOCALAPPDATA%\Microsoft\Edge\User Data\Default\Cache" ) do ( for /f "tokens=1,2 delims=:" %%x in ("%%~B") do ( if exist "%%y:" ( del /q /f /s "%%y:*" >nul 2>&1 ) ) ) Because of the "delims=:" tokenization, `%%y` resolves to just **"C"** (the drive letter). The condition `if exist "C:"` is always true. So the script silently executed: del /q /f /s "C:*" **This command silently force-deleted EVERY SINGLE FILE on my C: drive.** Operating system files, all my projects (hundreds of Python, JavaScript, C++ source files), client work with approaching deadlines, personal documents, photos — everything. Folders still exist but are completely empty. My computer can no longer boot. No programs open. Not even Command Prompt works. I'm sending this from my phone. **Anthropic's response:** I contacted support@anthropic.com and usersafety@anthropic.com multiple times. Their final response, literally signed "This response was generated by Anthropic's AI agent Fin AI Agent," stated they take no responsibility. They refuse any refund, compensation, or even a genuine human acknowledgment of their AI's catastrophic safety failure. Their position: "Our Terms of Service say outputs may contain inaccuracies. You should have independently verified the code before running it." My question: Why does Claude label destructive code as "Balanced Optimization - Safe mode"? If it can't guarantee safety, why does it promise it? **Proof:** I have the complete chat log, the full script file, and all email correspondence with Anthropic's support team. I'm happy to provide everything to moderators. **Update:** I am also filing complaints with the FTC (US Federal Trade Commission) and the Turkish Consumer Arbitration Board today. Don't let their "Safe Mode" labels fool you. Please share this so others don't lose years of work like I did. UPDATE — May 23, 2026: I have now filed official complaints with: US Federal Trade Commission (FTC) — Report #202036054 Turkish Consumer Arbitration Board — Application #2026/0245.3885 Both governments are now officially investigating Anthropic's role in this AI safety failure. Anthropic still refuses to take any responsibility. submitted by /u/falleennn [link] [comments]
View originalAnthropic officially launched 13+ FREE AI courses with certificates (Including Agentic AI and Claude Code!)
Just found out about this and had to share because almost nobody is talking about it yet. If you are tired of paying for AI courses or getting hit with paywalls just to get a certificate, Anthropic (the creators of Claude) quietly dropped a massive library of completely free, official training modules. Yes, they actually give you an official certificate of completion directly from Anthropic once you finish. Here is the breakdown of what is available and exactly how to get it without spending a dime. What is in the course catalog? They have split the training into a few different paths depending on what you want to do: The Big Surprise: Agentic AI & MCP: They have official courses on the Model Context Protocol (MCP). This is the cutting-edge tech used to build AI Agents that can browse your local computer, use tools, and execute tasks autonomously. Claude Code 101: Dedicated developer modules for their new command-line agent. It teaches you how to let Claude edit your codebase, run tests, and use its new "Plan Mode." API & Cloud Architecture: Deep dives into building with the Claude API, plus corporate tracks for deploying Claude securely inside Amazon Bedrock and Google Cloud Vertex AI. Everyday Productivity: If you aren't a coder, they have "Claude 101" and "AI Fluency" tracks. These teach advanced prompting, managing Projects, and using Artifacts for daily work. How to access it for free Anthropic hosts these courses on their official training academy platform (built on Skilljar). Because I can't post direct links here, here is how you find it: Search Google for "Anthropic Skilljar Academy" or "Anthropic Skilljar Catalog". Click the official link pointing to the Anthropic Skilljar domain. Sign up for a free account. You do not need to enter any credit card info. Choose your track, complete the lessons, pass the quick review quizzes, and download your certificate. Alternative Free Options If you want interactive coding environments alongside your videos, CodeSignal also has a free partnership track called "Developing Claude Agents" in Python and TypeScript that grants free certificates upon passing their labs. Go grab these before they decide to gate them behind a paywall! submitted by /u/Specialist_Engine522 [link] [comments]
View originalThese 9 Building Blocks Turned Claude Code From a Chat Into a persistent OS
Most developers Claude gurus use Claude Code one project at a time. I run 18. Not 18 sessions. 18 instances of the same OS, each running a different business, all sharing one skeleton I update once and propagate everywhere. Most developers treat Claude Code as a smarter editor. That's where it all goes wrong and you get frustrated. Claude Code becomes a real operating system the moment you stop thinking of sessions as the unit of work and start thinking of the whole environment as a substrate you build on top of. Here are 9 building blocks I use. The thesis is at the bottom. Build a skeleton with selective propagation, not a project. Most developers build one project per Claude Code workspace. I built a template instead. It has plugins, rules, agents, hooks, schemas, commands. When I start a new business I clone it and the new instance inherits the entire OS. Right now I run instances for: strategy, product, marketing website, threat intelligence, three consulting clients, a personal brand layer. Each one boots with the same DNA. Each one diverges on canonical files, memory, output, and project state. None of them bleed into the others. The sync mechanism is the load-bearing part. The update CLI pushes plugins, rules, agents, hooks, schemas. It never touches memory, output, canonical, or my-project. Those are the parts of an instance that accumulate. Without selective sync you have two options: rebuild every instance on every change, or never update. Both are dead ends. If you build features into one project, you wrote a project.If you build features into a template that propagates, you wrote an OS. I'm one person operating eighteen versions of myself. Move state out of prompts and into code. LLMs are bad at remembering. Code is designed for it. Most AI workflows leak state into the prompt. Voice rules. Style preferences. Banned words. Recent decisions. Eventually you hit context limits or contradictions. I moved as much state as possible into MCP servers. Voice linter. Lead scorer. Schedule validator. Loop tracker. They run in Python, return structured data, not hallucinations. Rule of thumb: if you've explained it to Claude more than twice, it should be code. Use receipts, not status fields. This one took me the longest to figure out. Every workflow I had was claim something is done. Issue marked closed. PRD marked shipped. Test marked passing. The problem: the LLM can claim anything. I rebuilt the system around receipts. An issue can't reach verified until a script runs and writes a verification record. A PRD can't archive until every accepted finding has a receipt. A morning routine can't close without log entries from every phase. Receipts get written by code, not by the model. The model can't lie about whether code ran. Build a wiring-check gate. Half-built features rot. In a normal repo you notice because something breaks. In an AI repo nothing breaks. The half-built feature sits there and Claude pretends it works. I built a /wiring-check command. Before any task counts as done, it checks: every new skill has a trigger, every new hook lives in settings.json, every new MCP tool sits in the server, every new bus file has a producer and a consumer. "I think it works" fails the gate. "I ran X, got Y" passes. Make rules auto-load, not slash commands. If you have to type /voice to apply voice rules, voice rules will not get applied. Rules in .claude/rules/ load automatically. The voice rule fires on outbound text. The AUDHD rule fires on anything I'll act on. The social-reaction rule fires when I share someone else's post. No remembering. No willpower. Lint style in code, not in prose. I wrote a voice document once. Claude ignored half of it. Same emdashes, same filler, same hedging. I moved the banned word list into a Python scanner. Now every outbound draft hits two linters. They block emdashes, AI hype words, and 40-something other tells. The model can't talk its way past a regex. Track file dependencies with a graph. Canonical files reference each other. Change one and three others go stale. I keep a ripple-graph.json that maps these. When I edit talk-tracks, the system flags current-state and the engagement playbook for review. Chain sessions with handoffs and memory. (This is the big one) Sessions are drafts. The work is everything that survives the session: canonical files, memory, handoffs, output. If nothing persisted, you didn't work. You chatted. Every session in my system ends with /q-wrap. Writes a handoff doc, a memory update, and a status receipt. /q-morning reads all three before doing anything else. The handoff covers: what shipped, what's blocked, what's next, what I learned. Memory files hold the longer-term version. The result: I can sleep for a week, come back, and the system reminds me where I was, what I cared about, and what the next move is.Nothing about Claude Code does this by default. You build it. Cont
View originalEvery Markdown File You Write for AI is Already Lying to It
CLAUDE.md files. System prompts. README files with setup instructions. Architecture docs. API references. Runbooks. Onboarding guides. If you've written a markdown file meant for an AI to read, it almost certainly contains values that were true when you wrote them and are no longer true now. The port your dev server runs on. The current version of the package. Which env vars are actually set. How many tests exist. Whether a service is running. These things change constantly, and markdown doesn't know it. So developers do what honest writers do - they add caveats. "Check package.json if this is stale." "Verify before running." "New packages may have been added since this was written." The intent is good. The effect is a list of things the AI has to go verify before it can do anything you actually asked for. We counted them in a real CLAUDE.md. There were seven. And CLAUDE.md is just one file type - the same problem exists everywhere AI reads markdown today. The Pre-Flight Tax Here's a representative CLAUDE.md. Nothing here is invented - these are patterns from real production repos: # CLAUDE.md > Before starting any session: Read ~/projects/api-core/SYNC.md first and check for > pending cross-project items. Update it after completing work. ## Project Overview Acme API - TypeScript REST API. Current version: 1.4.2 (check package.json if this is stale). ## Build and Run Commands # Development (API runs on port 3001, website on port 3000) # Note: PORT is set in .env - verify before running npm run dev:api npm run dev:web # Tests - currently 47 tests across 12 files npm run test:run Before running tests, make sure the test database is not already running on port 27018. Check with: docker ps | grep mongo-test ## Environment Variables | Variable | Required | Notes | |--------------|----------|-----------------------| | DATABASE_URL | YES | MongoDB connection | | JWT_SECRET | YES | Min 32 characters | | PORT | No | Defaults to 3001 | Check .env before assuming anything is configured. ## Architecture npm workspaces monorepo. Packages: - packages/api/ - packages/web/ - packages/shared/ - packages/db/ When in doubt about file counts or structure, run ls packages/ to check - new packages may have been added since this was written. ## Docker Check docker ps to see if a test container is still running from a previous session before starting a new build. Before Claude touches a single line of code, it has to: Open ~/projects/api-core/SYNC.md - cross-project lookup Read package.json - version check Read .env - port verification Check all env var statuses - is DATABASE_URL actually set? Run npm run test:run - or trust a number that's probably wrong Run docker ps | grep mongo-test - pre-test check Run ls packages/ - structure verification Seven tool calls. Each one costs a couple of seconds of latency. The test run alone can take ten. Add it up and Claude spends close to half a minute just getting to the starting line - consuming context and generating output before the actual task begins. And that's the obvious tax. The hidden one is subtler: every one of those checks can generate a follow-up. The .env read reveals WEBHOOK_SECRET isn't set. Now Claude has to decide whether to flag it or proceed. The docker ps shows a leftover container. Now Claude has to clean it up. Each verification spawns decisions, and each decision costs more context. The Same File, Rewritten MarkdownAI is a superset of Markdown. Any .md file that starts with @markdownai becomes live - directives resolve at render time, before Claude ever sees the file. Here's what the same CLAUDE.md looks like rewritten: @markdownai v1.0 @prompt role="context" This document is live. Every value was resolved at render time. Do not look up package.json, .env, or docker ps - current values are already below. @end # CLAUDE.md > Before starting: sync status is live in the Cross-Project Sync section below. ## Project Overview Acme API - version {{ read ./package.json path="version" }}. ## Build and Run Commands API on port {{ read .env key="PORT" fallback="3001" }}, web on {{ read .env key="WEB_PORT" fallback="3000" }}. @list ./package.json path="scripts" mode="entries" columns="key:Command,value:Runs" as="table" Test suite (live): @query "npm run test:run -- --reporter=verbose 2>&1 | tail -3" @cache session Mongo test container: @query "docker ps --format '{{.Names}} {{.Status}}' | grep mongo-test || echo 'not running - port 27018 is clear'" @cache session ## Environment Variables @if file.exists ".env" | Variable | Required | Status | |--------------|----------|-------------------------------------------------------------| | DATABASE_URL | YES | {{ env.DATABASE_URL != "" ? "set" : "MISSING - will not start" }} | | JWT_SECRET | YES | {{ env.JWT_SECRET != "" ? "set" : "MISSING - auth will fail" }} | | NODE_ENV | No | {{ env.NODE_ENV fallback="development" }} | @else **WARNING: No .env file found. App will not start.** @endif ## Architecture @list ./p
View originalSam Altman’s ego was OpenAI’s downfall
The more I watch OpenAI, the more convinced I become that Sam Altman’s ego was the beginning of the company’s decline. OpenAI did not become huge because Altman was some once-in-a-generation operator. It became huge because ChatGPT was a once-in-a-generation product. There is a difference. The company stumbled into one of the most important consumer tech moments since the iPhone, rode the sheer shock value of that innovation, and then somehow convinced itself that the person sitting on top of the rocket must have designed the laws of physics. OpenAI’s first real advantage was novelty. ChatGPT felt magical. That gave OpenAI a massive head start, but when the novelty vanished and the rest of the market caught up, the company failed to prove itself not just as an innovation lab with a celebrity CEO. Altman seems to want OpenAI to become Apple: a closed, prestigious, centralized, gatekept ecosystem where everyone builds inside his cathedral. Apps inside ChatGPT. Agents inside ChatGPT. Hardware. ChatGPT is popular, but OpenAI does not own the phone. It does not own the operating system. It does not own the enterprise workflow. It does not own the cloud layer the way Microsoft, Amazon, or Google do. It does not even have a product moat that feels as unbreakable as people thought it was two years ago. The underlying model quality gap keeps narrowing. Switching costs are low. Developers and businesses will use whatever works, whatever is cheaper, and whatever integrates better. That is why Anthropic looks much better run right now. Anthropic is not pretending Claude is some holy object that needs an Apple-style walled garden around it. Their strategy feels much more Microsoft-like: accept that the core product may not be permanently magical, then build the boring, useful, sticky layers around it. Claude Code, enterprise integrations, developer tools, workflows, partnerships, APIs, reliability, business adoption. Not as sexy. Much smarter. Anthropic’s venture capital money is obviously being burned too. This whole industry is basically setting money on fire to buy GPUs. But Anthropic’s burn feels more strategically allocated. Compute, yes. But also marketing, sales and developer adoption. Enterprise positioning. Product polish. Peripherals that make the model useful in actual workflows. They are not just trying to win the “my chatbot is smarter than your chatbot” contest. They are trying to become infrastructure. OpenAI, meanwhile, is gatekeeping and guard railing the shit out of their models and for some reason just restricting them as much as possible. He went from being one of the most respected figures in AI to becoming the face of a company that increasingly looks like it is being run aground by ambition without operational coherence. OpenAI’s original image was almost wholesome: brilliant researchers building something open source. Now it feels like a capitalist machine run by someone who does not fully understand capitalism beyond fundraising and valuation theater. Altman religiously narrowing his vision towards his AGI mission believing VC money won't dry down. Amodei also talks a lot about AGI but he understands profit matters. That is the irony. Altman was chosen and celebrated largely because he came from the venture/startup world. He knew how to talk to capital. He knew how to sell a vision. He knew how to make investors believe the future was being negotiated in whatever room he happened to be standing in. But being good at venture mythology is not the same as being good at running a giant operating company. A VC can be rewarded for telling a compelling story before the business fundamentals exist. A CEO eventually has to make the fundamentals exist. OpenAI had the best possible starting position: the brand, the users, the developer mindshare, the press, the money, the talent, the cultural moment. And yet instead of consolidating that lead into a focused, profitable, durable company, it seems to have chased grandeur. Anthropic seems to understand something OpenAI forgot: the winner may not be the company with the loudest AGI rhetoric. It may be the company that makes AI useful, embedded, and rational. submitted by /u/Alternative_Bid_360 [link] [comments]
View originalSam Altman's ego was OpenAI's downfall.
The more I watch OpenAI, the more convinced I become that Sam Altman’s ego was the beginning of the company’s decline. OpenAI did not become huge because Altman was some once-in-a-generation operator. It became huge because ChatGPT was a once-in-a-generation product. There is a difference. The company stumbled into one of the most important consumer tech moments since the iPhone, rode the sheer shock value of that innovation, and then somehow convinced itself that the person sitting on top of the rocket must have designed the laws of physics. OpenAI’s first real advantage was novelty. ChatGPT felt magical. That gave OpenAI a massive head start, but when the novelty vanished and the rest of the market caught up, the company failed to prove itself not just as an innovation lab with a celebrity CEO. Altman seems to want OpenAI to become Apple: a closed, prestigious, centralized, gatekept ecosystem where everyone builds inside his cathedral. Apps inside ChatGPT. Agents inside ChatGPT. Hardware. ChatGPT is popular, but OpenAI does not own the phone. It does not own the operating system. It does not own the enterprise workflow. It does not own the cloud layer the way Microsoft, Amazon, or Google do. It does not even have a product moat that feels as unbreakable as people thought it was two years ago. The underlying model quality gap keeps narrowing. Switching costs are low. Developers and businesses will use whatever works, whatever is cheaper, and whatever integrates better. That is why Anthropic looks much better run right now. Anthropic is not pretending Claude is some holy object that needs an Apple-style walled garden around it. Their strategy feels much more Microsoft-like: accept that the core product may not be permanently magical, then build the boring, useful, sticky layers around it. Claude Code, enterprise integrations, developer tools, workflows, partnerships, APIs, reliability, business adoption. Not as sexy. Much smarter. Anthropic’s venture capital money is obviously being burned too. This whole industry is basically setting money on fire to buy GPUs. But Anthropic’s burn feels more strategically allocated. Compute, yes. But also marketing, sales and developer adoption. Enterprise positioning. Product polish. Peripherals that make the model useful in actual workflows. They are not just trying to win the “my chatbot is smarter than your chatbot” contest. They are trying to become infrastructure. OpenAI, meanwhile, is gatekeeping and guard railing the shit out of their models and for some reason just restricting them as much as possible. He went from being one of the most respected figures in AI to becoming the face of a company that increasingly looks like it is being run aground by ambition without operational coherence. OpenAI’s original image was almost wholesome: brilliant researchers building something open source. Now it feels like a capitalist machine run by someone who does not fully understand capitalism beyond fundraising and valuation theater. Altman religiously narrowing his vision towards his AGI mission believing VC money won't dry down. Amodei also talks a lot about AGI but he understands profit matters. That is the irony. Altman was chosen and celebrated largely because he came from the venture/startup world. He knew how to talk to capital. He knew how to sell a vision. He knew how to make investors believe the future was being negotiated in whatever room he happened to be standing in. But being good at venture mythology is not the same as being good at running a giant operating company. A VC can be rewarded for telling a compelling story before the business fundamentals exist. A CEO eventually has to make the fundamentals exist. OpenAI had the best possible starting position: the brand, the users, the developer mindshare, the press, the money, the talent, the cultural moment. And yet instead of consolidating that lead into a focused, profitable, durable company, it seems to have chased grandeur. Anthropic seems to understand something OpenAI forgot: the winner may not be the company with the loudest AGI rhetoric. It may be the company that makes AI useful, embedded, and rational. submitted by /u/Alternative_Bid_360 [link] [comments]
View originalClaude Platform on AWS reference - what's new in CC 2.1.139 (+2,248 tokens)
NEW: Data: Claude Platform on AWS reference — Reference documentation for using the Claude Developer Platform through AWS infrastructure, including AnthropicAWS clients, required region and workspace configuration, SigV4 authentication, and short-term API keys. Agent Prompt: Conversation summarization — Adds requirement to note security-relevant instructions or constraints (sensitive files, forbidden operations, credential handling rules) and preserve them verbatim in the summary so they remain in effect after compaction. Agent Prompt: Recent Message Summarization — Same security-relevant instructions preservation requirement added to the recent-portion summarization flow. Data: Live documentation sources — Adds WebFetch URLs for Claude Platform on AWS and its required IAM actions documentation. Skill: Building LLM-powered applications with Claude — Reframes cloud-provider access so Claude Platform on AWS is treated as Anthropic-operated with same-day API parity and full Managed Agents support, while Bedrock, Vertex, and Foundry remain Claude API + tool use only. Skill: Dynamic pacing loop execution — Reorders steps so the brief confirmation (task ran, monitor as wake signal, fallback delay choice) is written as text before the schedule-wakeup call ends the turn. Skill: /insights report output — Removes the trailing additional-message block from the shareable report response. Skill: /loop self-pacing mode — Same reordering as dynamic pacing loop: confirm self-pacing, monitor wake signal, and fallback delay as text before the schedule-wakeup call. Skill: Model migration guide — Adds a Claude Platform on AWS section noting it uses bare first-party model IDs and that the full rename table and breaking-change sections apply verbatim, distinct from Bedrock. System Prompt: Auto mode — Drops the "Auto Mode Active" header and reframes destructive-action guidance generically rather than auto-mode-specific. System Prompt: Harness instructions — Removes the standalone note that automatic context compaction will trigger when conversations grow long. System Prompt: Memory instructions — Replaces 3–4 word titles with short kebab-case slugs, nests type under a metadata block, and introduces [[their-name]] cross-links between related memories. System Prompt: Partial compaction instructions — Adds the same security-relevant instructions preservation requirement so sensitive-file rules, forbidden operations, and credential handling carry across partial compactions. System Reminder: Output style active — Lets an output style supply its own per-turn reminder text, falling back to the default "follow the specific guidelines" wording. System Reminder: Task tools reminder — Removes the instruction telling Claude to never mention the reminder to the user. System Reminder: TodoWrite reminder — Removes the instruction telling Claude to never mention the reminder to the user. Tool Description: PowerShell — Adds a substantial reference table mapping Unix commands (head, tail, which, touch, wc, mkdir -p, rm -rf, ln -s, chmod, 2>/dev/null, inline VAR=x, bash control flow) to their PowerShell equivalents, and clarifies that -ErrorAction SilentlyContinue still causes exit 1 unless promoted to terminating and caught. Details: https://github.com/Piebald-AI/claude-code-system-prompts/releases/tag/v2.1.139 submitted by /u/Dramatic_Squash_3502 [link] [comments]
View originalClaude Platform on AWS is now generally available
AWS has officially announced the General Availability of Claude Platform on AWS, giving developers direct access to Anthropic’s native Claude Platform experience through existing AWS accounts. This is pretty interesting because AWS is now the first cloud provider offering direct access to the native Claude experience without requiring separate Anthropic account management. https://preview.redd.it/u1ow3zwu4n0h1.png?width=2451&format=png&auto=webp&s=03686874221fa4e7ac870fcee28739d3ee83e2b0 Some notable features available: Claude Managed Agents (Beta) Web Search & Web Fetch Code Execution Files API MCP Connector Prompt Caching Citations Batch Processing Claude Console for prompt development and evaluation What stands out to me is the operational simplicity: Existing IAM authentication AWS billing integration CloudTrail logging visibility No separate account handling One important point AWS mentioned: Customer data for Claude Platform on AWS is processed outside the AWS security boundary, so organizations with strict data residency/compliance requirements may want to evaluate that carefully. The service is already available across multiple AWS regions globally. Source Link submitted by /u/Few-Engineering-4135 [link] [comments]
View originalAWS just gave AI agents their own wallets. Your agent can now pay for itself.
This dropped 4 days ago and I haven't seen enough people talking about it. AWS launched Amazon Bedrock AgentCore Payments in partnership with Coinbase and Stripe. The short version: your agent now has a wallet and can spend money on its own. Here's what the workflow actually looks like now: You give your agent a Coinbase or Stripe wallet. You fund it. You set a session spending limit (e.g. "$5 max per run"). The agent runs. It hits a paid API mid-execution? It pays. Paywalled data it needs? It pays. A better-suited agent available for a subtask? It pays that agent and gets the result back. All of this happens inside the same execution loop, with zero human interruption. The protocol making this work is called x402. It's open source, developed by Coinbase, and it revives the long-dormant HTTP 402 "Payment Required" status code. The flow is dead simple: agent requests a resource, server responds with 402 + a price, agent signs a USDC micropayment, gets the content, keeps going. Settlement happens in ~200ms on Base at a fraction of a cent per transaction. The protocol has already processed over 169 million payments across 590,000 buyers and 100,000 sellers in its first year. Why this matters for indie developers and SaaS builders: The pricing model for software is about to split in two. There will be products built for humans (subscriptions, seats, dashboards) and products built for agents (pay-per-call, x402 endpoints, micropayment APIs). Many agent transactions involve amounts as small as fractions of a cent, making traditional payment networks unusable. That's the gap x402 fills. If you're building any kind of data API, research tool, or specialized service today, the question you should be asking is: "How does another agent pay me automatically?" Coinbase also launched the Bazaar MCP server inside AgentCore Gateway, essentially an App Store for x402-enabled services. Agents can search, discover, and pay for services when relevant to their task, turning paid endpoints into something agents can find on their own. The honest take: The agentic economy is still in its earliest days, and the infrastructure to support it at scale doesn't exist yet. This is preview infrastructure, not production-ready magic. But the direction is clear. 2026 was the year agents learned to work. 2027 is shaping up to be the year they learn to transact. The builders who figure out agent-native pricing now will have a real advantage over those retrofitting subscriptions later. Curious if anyone here is already building x402-compatible endpoints or thinking about agent-to-agent billing models. Would love to see what people are working on. submitted by /u/Direct-Attention8597 [link] [comments]
View originalClaude Code may be Anthropic’s real moat
The recent “What’s new in Claude Code” (https://www.youtube.com/live/IMZa42k6L6M?si=v9tysKPRHK8Zn3uQ) session made me think Anthropic’s real product moat may not be chat. It may be workflow. Claude Code is starting to look less like “AI that helps me code” and more like an engineering operating system: planning, code review, cloud agents, routines, permission handling, team onboarding, and eventually more autonomous engineering workflows. That’s a much bigger product direction than autocomplete or chat-based coding help. The open question is whether developers want that level of integration, or whether they still want AI to stay as a controllable assistant rather than an embedded workflow layer. Curious what people think: is Claude Code becoming Anthropic’s strongest wedge, or is this just the natural evolution of coding assistants? submitted by /u/Roaring_lion_ [link] [comments]
View originalAnthropic just partnered with SpaceX and doubled Claude Code rate limits effective today
Anthropic just partnered with SpaceX and doubled Claude Code rate limits effective today Big news dropped this morning. Anthropic signed a deal to use all compute capacity at SpaceX's Colossus 1 data center. That's 300+ megawatts and over 220,000 NVIDIA GPUs coming online within the month. But the part that actually matters to developers right now: What changed today: - Claude Code 5-hour rate limits are doubled (Pro, Max, Team, Enterprise) - Peak hours limit reduction on Claude Code is removed for Pro and Max - API rate limits for Claude Opus models raised considerably This is on top of their existing compute deals 5 GW with Amazon, 5 GW with Google/Broadcom, $30B of Azure capacity with Microsoft and NVIDIA, and $50B in infrastructure with Fluidstack. They also mentioned interest in developing orbital AI compute with SpaceX. Which is a sentence I did not expect to read in 2026. For those of us building with Claude Code daily, the doubled limits + no more peak hour throttling is the headline. Rate limits have been the most frustrating bottleneck when you're deep in a long coding session. Anyone else noticing a difference already? submitted by /u/Direct-Attention8597 [link] [comments]
View originalNew Compute Partnership with Anthropic and xAI
https://x.ai/news/anthropic-compute-partnership submitted by /u/WhyLifeIs4 [link] [comments]
View originalHow does Claude (with access to the law) perform compared to law-specific AI systems (like Westlaw/Lexis)? We ran a series of head to head tests
We’re now a couple of years into the AI wave, and it seems like the available legal AI technology has begun splitting down two different tracks: In one direction, there are general purpose AI systems like Claude or Chat GPT; in the other direction you have purpose-built legal AI systems like Westlaw’s AI Deep Research and Lexis Protege. We’re two active litigators (Ding and Duff) who use both Claude and Westlaw regularly. Curious to see how well the various systems perform legal research, we decided to run a series of comparison tests consisting of five prompts across all three systems. We think the results are interesting so we’ve decided to share them. By itself Claude doesn’t have access to the cases or statutes. We’ve used a connector that we built called DingDuff (it’s free for now if you supply your own Anthropic API key). As discussed below, DingDuff allows Claude to search for and retrieve cases and statutes, but the decisions about what to research or how are coming from Claude (we ran tests with and without a case law research skill file and it didn’t make a huge difference). One fascinating result of this test is it reveals how quickly Claude has improved as an AI system. These outputs were mostly generated in late April 2026 using the latest version of Claude co-work and (we think) they are very impressive. Claude could not have produced these outputs a year ago. The five prompts are made-up fact patterns designed to cover different states and different areas of law, but we tried to craft them so that they resemble real prompts we actually use. The prompts Prompt 1 Adverse Possession — Walton County, GA. Prepare a memo analyzing my client's position in a boundary dispute in Walton County, Georgia. In 1998 my client's predecessor-in-title built a barbed-wire fence intended to follow the surveyed boundary between two rural parcels. A 2024 survey revealed that the fence encroaches approximately 12 feet onto the adjoining owner's land over a 400-foot run, enclosing roughly 4,800 square feet. My client bought the property in 2011 and has continuously grazed cattle on the enclosed strip; his predecessor used it for pasture from 1998 to 2011. The record owner has paid property taxes on the disputed strip throughout. The neighbor first objected in late 2025 and has threatened ejectment. Please address: (1) whether my client can establish title by adverse possession (20-year) or prescription (7-year under color of title) under relevant Georgia statutes and case law; (2) whether tacking between predecessors is available on these facts; (3) whether the hostility element can be satisfied when the parties mutually (but mistakenly) believed the fence sat on the true line — i.e., the "mistaken boundary" line of authority; (4) the effect, if any, of the record owner's tax payments; and (5) the procedural vehicle and venue for quieting title. 2 Piercing the Corporate Veil — Single-Member Delaware LLC, Harris County forum. Please prepare a memo analyzing whether a trade creditor can pierce the veil of a Delaware LLC whose sole member is a Texas-resident individual. The LLC was formed in Delaware in 2019 to operate a single Houston-area restaurant. The sole member routinely paid personal expenses (his home mortgage, his wife's vehicle lease, his children's tuition) directly from the LLC operating account; the LLC never adopted anything beyond a one-page operating agreement, held no member meetings, and was initially capitalized with $5,000 against monthly operating expenses of roughly $80,000. My client, a produce wholesaler, is owed approximately $220,000 on open account. The LLC has ceased operations and is insolvent. Suit will be filed in Harris County. Please address: (1) whether Delaware or Texas law governs the veil-piercing analysis under Texas choice-of-law principles (internal affairs doctrine vs. substantive tort/contract characterization); (2) the substantive standards under each jurisdiction; (3) whether reverse veil-piercing is available; and (4) whether a companion Texas Uniform Fraudulent Transfer Act claim against the individual member is viable and how it interacts with the veil theory. 3 Mechanics Lien Priority — Subcontractor vs. Construction Lender, LA County. Please prepare a memo analyzing priority between my client (an HVAC subcontractor) and a construction lender on a mixed-use project in Los Angeles County. My client first furnished labor and materials on March 3, 2024, and served a 20-day preliminary notice on the owner, general contractor, and the original construction lender on March 28, 2024 (within statutory time). The original lender assigned the construction loan to a successor lender in July 2024; my client did not serve a new preliminary notice on the successor. My client last furnished work on December 15, 2024, and recorded a mechanics lien on February 10, 2025 (56 days later). The general contractor recorded a notice of completion on January 2, 2025. The s
View originalClaude is my SEO strategist, content engine, and CTO. From 0 to 10,000 active users in 6 weeks, $0 on ads.
I built a marketplace for AI agent skills called Agensi. The entire thing was built with Claude and Lovable. I'm not a developer. But that's not what this post is about. This post is about how Claude became the single most important tool in my growth stack. Not for coding. For SEO, content strategy, and a new thing called AEO (answer engine optimization) that I think most people are sleeping on. Claude writes all my content, but not the way you think I don't ask Claude to "write me a blog post about X." That produces generic AI slop that nobody reads and Google doesn't rank. Instead, I feed Claude my Google Search Console data (queries, impressions, click-through rates, average positions) and ask it to find keyword gaps. Claude analyzes the data, identifies queries where I have high impressions but zero clicks, finds topics where I have no content but competitors do, and spots cannibalization where multiple pages compete for the same query. Then we write articles together targeting those specific gaps. Every article has a structure that Claude and I developed over weeks of iteration: a Quick Answer block at the top (40-60 words that directly answer the main question), H2 headings phrased as questions (not "Claude Code Skill Locations" but "Where Does Claude Code Store Skills?"), comparison tables where relevant, and internal links to related articles. 96 articles later, we went from 5 clicks per week to 1,000+ clicks per week. 300K search impressions per month. 878+ page-1 Google rankings. All organic. The AEO strategy nobody is talking about Here's what surprised me. ChatGPT, Gemini, Perplexity, and Claude itself are now sending us traffic. 348 AI-referred sessions per month and growing fast. These AI answer engines cite agensi.io when developers ask where to find SKILL.md skills. Claude helped me build the entire AEO infrastructure. We restructured every H2 heading as a question because AI Overviews prefer extracting from question-format sections. We added FAQ schema to every page so Google's AI picks up our Q&As. We built an /about page as an entity anchor with Organization, Person, and AboutPage schema. We created a robots.txt that explicitly allows all AI crawlers and an llms.txt file that tells LLMs what the site is and where to find key content. The result is that when someone asks ChatGPT "where can I find SKILL.md skills" or asks Perplexity "what is the best skill marketplace for AI agents," they get pointed to agensi.io. Claude helped me engineer that outcome deliberately. It wasn't an accident. Claude as a technical SEO auditor Every week I export data from Google Search Console, Ahrefs, and Google Analytics and dump it into Claude. Claude finds things I would never catch on my own. It found that 121 queries where I ranked position 1-3 had zero clicks because AI Overviews were stealing the traffic. That insight changed my entire strategy from chasing rankings to becoming the source that AI Overviews cite. It found that my "best claude code skills 2026" article had 25,000 impressions and only 29 clicks. The problem was the title. Claude rewrote it to "15 Best Claude Code Skills in 2026 (Tested & Ranked)" and we're watching the CTR climb. It found that I had 18 published articles with zero Google impressions because they weren't indexed. Claude generated the IndexNow ping commands and the GSC URL Inspection list to fix it. It diagnosed a duplicate FAQPage schema issue that was causing GSC errors on 90 pages. The root cause was React components emitting FAQ schema client-side AND the SSR edge function emitting it server-side. Claude identified the exact files, wrote the Lovable prompts to fix it, and verified the fix with curl commands. The structured data layer Claude built the entire structured data architecture for the site. Every page type has the right schema: Homepage has Organization, WebSite with SearchAction, and FAQPage with 15 Q&As. Individual skill pages have SoftwareApplication with pricing, BreadcrumbList, and conditional FAQPage. Article pages have Article, FAQPage, HowTo, BreadcrumbList, and Organization. The /about page has Organization, AboutPage, and Person schema for entity anchoring. I didn't know what any of this was before Claude explained it. Now every page is machine-readable for both Google and AI engines. PageSpeed Insights shows "Structured data is valid" on every page with a 100 SEO score. Core Web Vitals fixes Claude diagnosed that our desktop LCP was 2.5-4s on 190 URLs. It identified the causes (460KB eager JS bundle, framer-motion loading on every page for a mobile menu animation, synchronous analytics scripts) and wrote the Lovable prompts to fix each one. Desktop LCP went from 2.5-4s to 0.9s. Performance score went from ~70 to 97. For mobile, Claude found that the LCP element was a 1920x1920px, 179KB PNG logo being rendered at 112px. It was imported as a JS module so the browser couldn't even start downloading it until the entire JS bundle par
View originalTalkie: a 13B LLM trained only on pre-1931 text used Claude Sonnet to help test the model and judge its output
Researchers Alec Radford (GPT, CLIP, Whisper), Nick Levine, and David Duvenaud just released talkie: a 13 billion parameter language model trained exclusively on text published before 1931. No internet. No Wikipedia. No World War II. Its worldview is frozen at December 31, 1930. Why does this matter? Every major LLM today (GPT, Claude, Gemini, Llama) ultimately shares a common ancestor: the modern web. That makes it nearly impossible to tell what these models genuinely reason versus what they simply memorized. Talkie breaks that lineage entirely. From the team: "It's an important question how much LM capabilities arise from memorization vs generalization. Vintage LMs enable unique generalization tests." Interestingly, Claude has a direct role in talkie's creation: Claude Sonnet 4.6 was used as the judge in talkie's reinforcement learning pipeline (online DPO), and Claude Opus 4.6 generated synthetic multi-turn conversations used in the final fine-tuning stage. The team even notes the irony: using a thoroughly modern LLM to help shape a model that's supposed to be frozen in 1930, and flagging it as a contamination risk they're actively working to eliminate in future versions. The most striking example: talkie can learn to write Python code from just a few in-context examples... despite having zero modern code in its training data. It's reasoning from 19th-century mathematics texts, not retrieval. What it's being used to study Long-range forecasting: how well can a model "predict" the future from its frozen vantage point? Invention: can it develop ideas that postdate its knowledge cutoff? LLM identity: what makes a model itself? Talkie's alien data distribution helps isolate what's architecture vs. what's just "vibes absorbed from the web" Links Chat with talkie live Official blog post Original announcement on X Discussion on r/accelerate Discussion on r/singularity Both models are Apache 2.0 licensed and open-weight on Hugging Face. The team is already planning a GPT-3-scale vintage model for later this year. submitted by /u/BatPlack [link] [comments]
View originalYes, Amazon Q Developer offers a free tier. Pricing found: $19/mo, $.003, $0.003, $19, $19
Amazon Q Developer has an average rating of 4.5 out of 5 stars based on 5 reviews from G2, Capterra, and TrustRadius.
Key features include: JetBrains, VS Code, Visual Studio, Command line, Eclipse, Get expert assistance on AWS, Code faster, Customize code recommendations.
Amazon Q Developer is commonly used for: Implementing features autonomously in software development, Documenting code and generating documentation automatically, Testing code and writing unit tests, Reviewing and refactoring existing code, Performing software upgrades and migrations, Optimizing cloud costs and resource management in AWS.
Amazon Q Developer integrates with: AWS Management Console, Microsoft Teams, Slack, GitLab, JetBrains, VS Code, Visual Studio, Eclipse, Command Line Interface (CLI), AWS Console Mobile Application.
Based on user reviews and social mentions, the most common pain points are: spending limit, token usage.
Based on 50 social mentions analyzed, 24% of sentiment is positive, 74% neutral, and 2% negative.