Apache Superset
Community website for Apache Superset™, a data visualization and data exploration platform
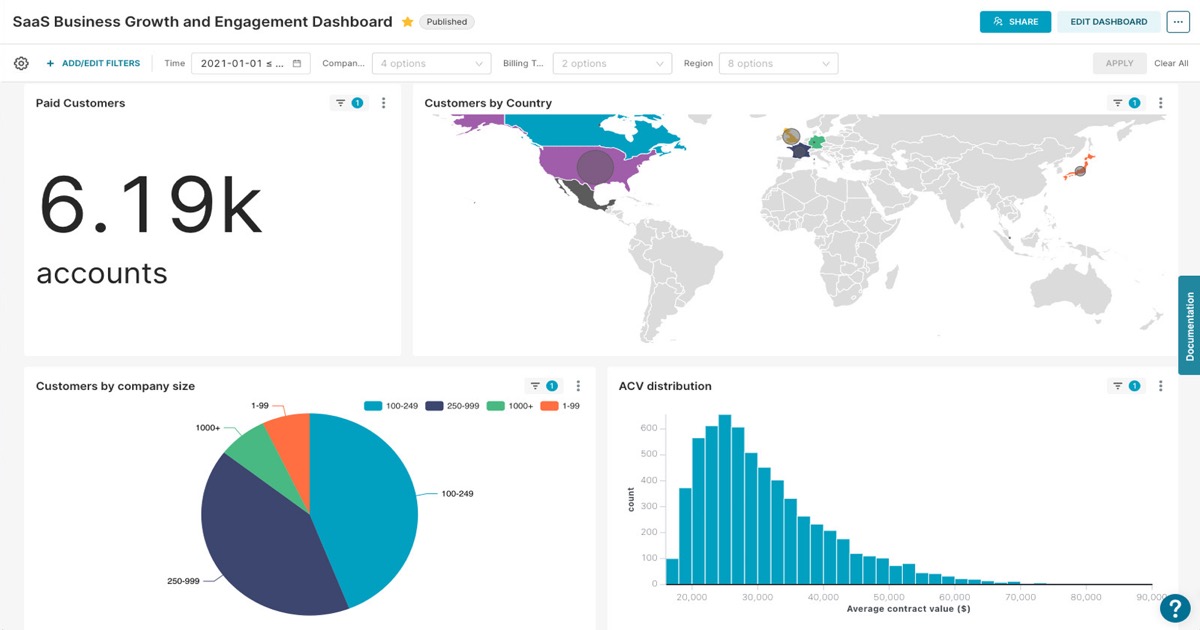
For analysts and business users. Learn to explore data, build charts, create dashboards, and connect to databases. For teams installing and operating Superset. Covers installation, configuration, security, and database drivers. For contributors and engineers building on Superset. Covers the REST API, extensions, and contributing workflows. Join the Superset community. Find resources on Slack, GitHub, the mailing list, and upcoming meetups. Superset makes it easy to explore your data, using either our simple no-code viz builder or state-of-the-art SQL IDE. Superset can connect to any SQL-based databases including modern cloud-native databases and engines at petabyte scale. Superset is lightweight and highly scalable, leveraging the power of your existing data infrastructure without requiring yet another ingestion layer. Superset ships with 40+ pre-installed visualization types. Our plug-in architecture makes it easy to build custom visualizations. Create physical and virtual datasets to scale chart creation with unified metric definitions. Explore data and find insights from interactive dashboards. Drag and drop to create robust charts and tables. Write custom SQL queries, browse database metadata, use Jinja templating, and more. Create physical and virtual datasets to scale chart creation with unified metric definitions. Explore data and find insights from interactive dashboards.
Motherduck
The modern cloud data warehouse powered by DuckDB. Serverless SQL analytics with no infrastructure to manage—query your data in seconds. Start free.
The cloud data warehouse built for answers, in SQL or natural language. Fast, serverless analytics powered by DuckDB–from production apps to internal insights. Get the complete book for free in your inbox! A cloud analytical database that scales per-user compute nodes independently, serving sub-second latency without resource contention. Turn natural language questions into accurate, traceable SQL queries with fully sandboxed compute. Cloud analytics and data warehouse solutions for every team Who ended up with a big data problem Who ended up having to do data engineering Cloud analytics and data warehouse solutions for every team Who ended up with a big data problem Who ended up having to do data engineering Is your data all over the place? Modern cloud data warehouse tools bring it together for business intelligence and SQL analytics. Build data pipelines, share data, and collaborate with your team. Unlike traditional BI, customer-facing analytics is built directly into your product for end users. This embedded analytics solution delivers real-time, low-latency insights at scale — think milliseconds, not minutes — powered by a columnar database that handles thousands to millions of concurrent queries. MotherDuck's architecture, from Hypertenancy to Wasm support, is designed for Customer-Facing Analytics that drives user engagement directly in your app. A Duckling is a dedicated DuckDB instance for each user, ensuring optimal performance and scalability in data analytics. Our smallest instance, perfect for ad-hoc analytics tasks Built to handle common data warehouse workloads, including loads and transforms For larger data warehouse workloads with many transformations or complex aggregations An extremely large instance for when you need complex transformations done quickly Largest instances enable the toughest transformations to run faster MotherDuck's cloud data warehouse employs a Hypertenancy and vertical scaling strategy. Users connect to their own MotherDuck Ducklings (DuckDB instances), which are sized (pulse, standard, jumbo, mega, giga) to meet their specific needs. There is also the option for additional Ducklings, through read scaling (explained below), to ensure flexible resource allocation. Ultimately, each Duckling establishes a connection with the central data warehouse storage. MotherDuck's read scaling capabilities allow users to connect via a BI Tool to dedicated Ducklings that function as read replicas. These read replicas can be provisioned in various sizes (pulse, standard, jumbo, mega or giga) to accommodate different needs. Ultimately, these read replicas connect to the Data Warehouse storage, enabling efficient handling of read operations. Plans that fit customer-facing analytics and internal data warehousing use cases. For solo practitioners and hobbyists leaving the nest Everything you need for production analytics Customized plans for large-scale deployments Internal users in your
Apache Superset
Motherduck
Apache Superset
Motherduck
Pricing found: $0, $250, $0, $250, $0.04
Only in Apache Superset (10)
Only in Motherduck (10)
Apache Superset
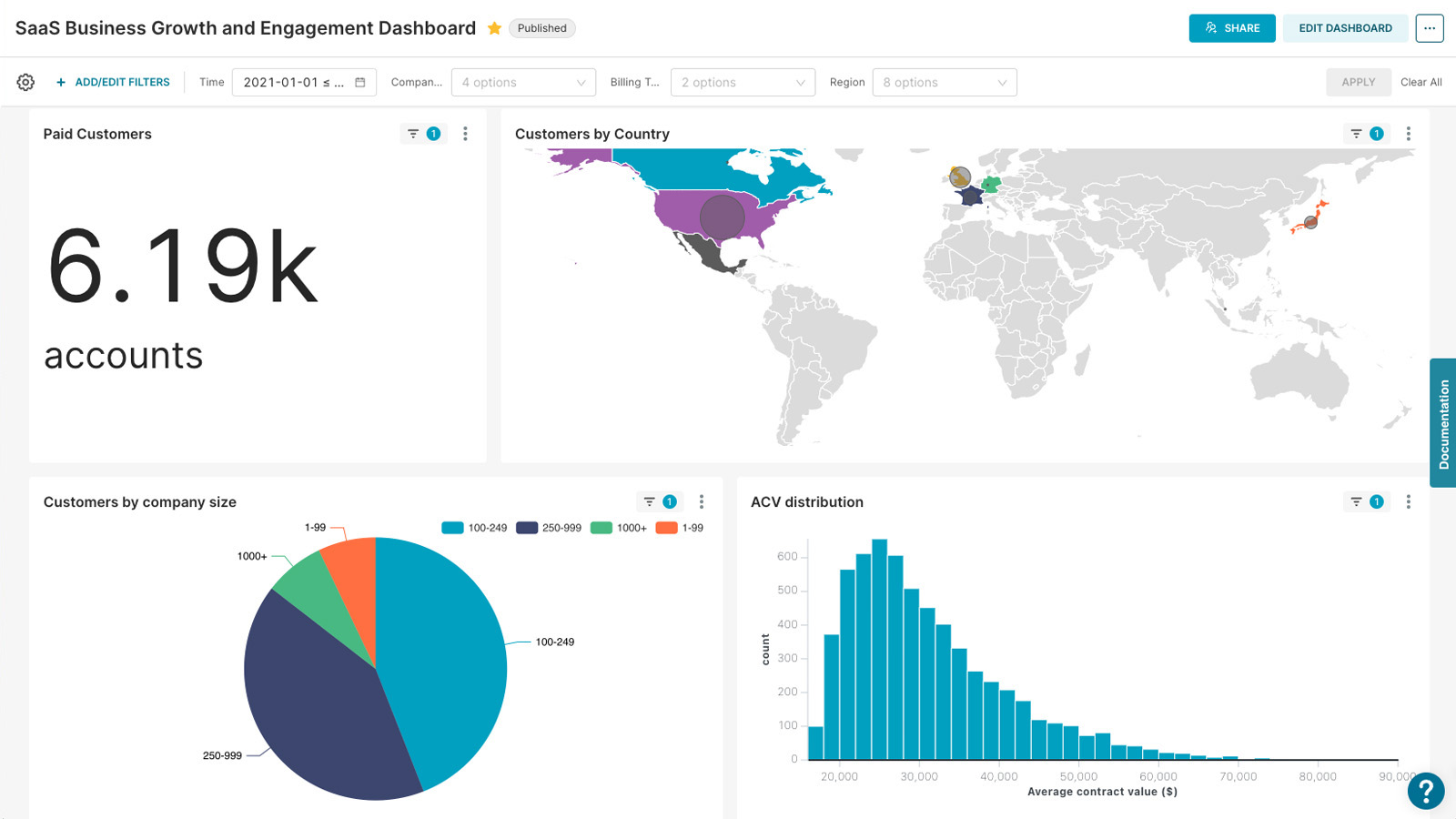


Motherduck



Apache Superset
Motherduck