Unified LLM Observability and Agent Evaluation Platform for AI Applications—from development to production.
Arize AI is widely praised for its advanced capabilities and integration in AI infrastructure, with strong satisfaction reflected in consistent high ratings from users on platforms like g2. Users appreciate its technical sophistication and benefits for autonomous agent deployment. Some minor complaints arise regarding the learning curve or complexity associated with its use. Pricing appears to be acceptable given the tool's robust features, contributing to its positive overall reputation in AI model monitoring and optimization communities.
Mentions (30d)
0
Avg Rating
4.3
20 reviews
Platforms
2
GitHub Stars
9,104
784 forks


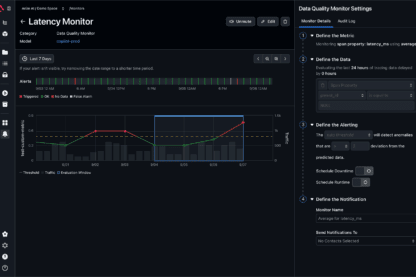
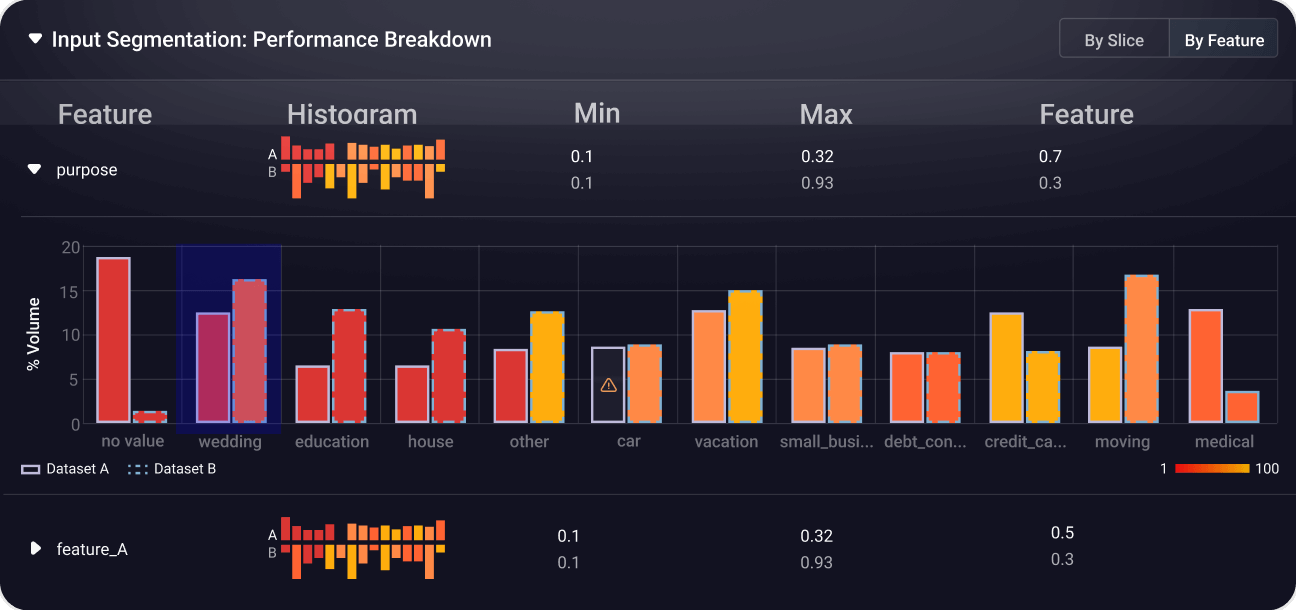
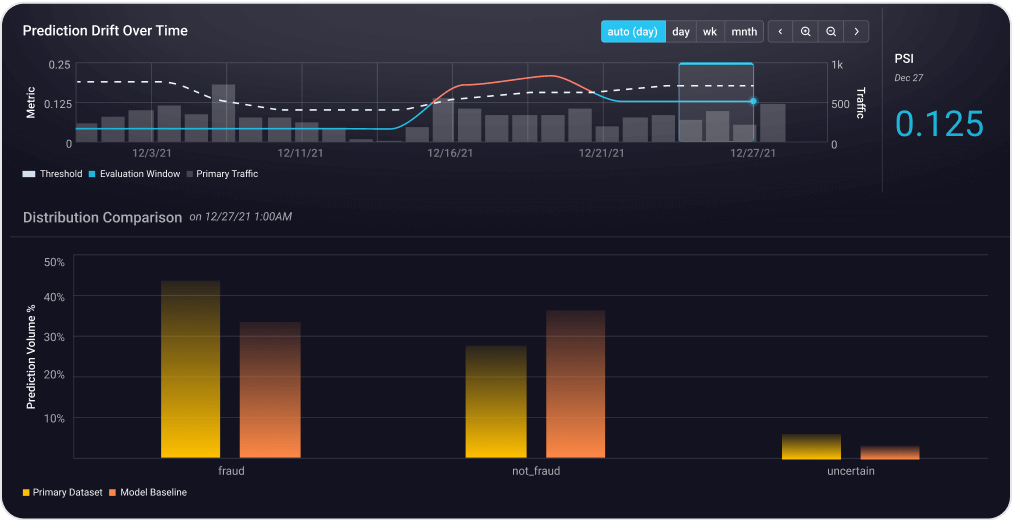
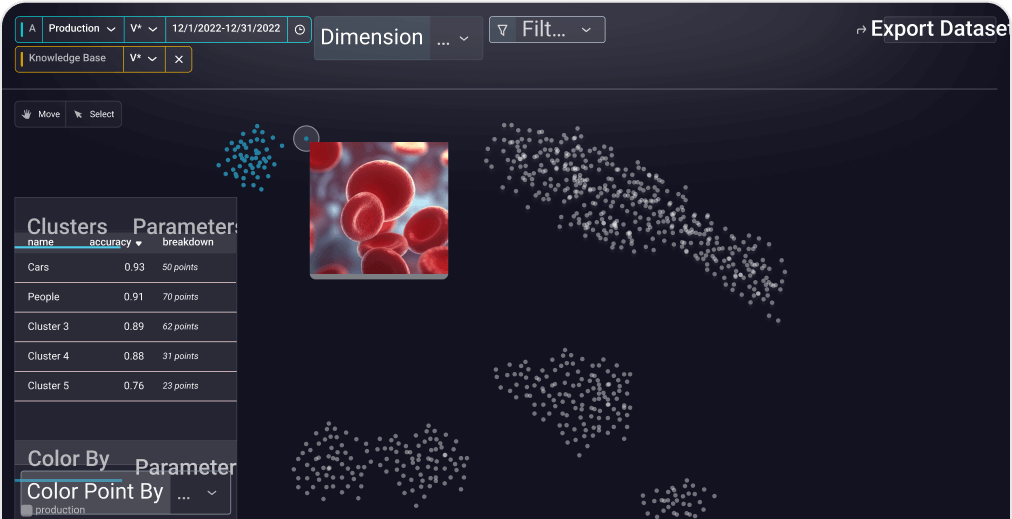
Arize AI is widely praised for its advanced capabilities and integration in AI infrastructure, with strong satisfaction reflected in consistent high ratings from users on platforms like g2. Users appreciate its technical sophistication and benefits for autonomous agent deployment. Some minor complaints arise regarding the learning curve or complexity associated with its use. Pricing appears to be acceptable given the tool's robust features, contributing to its positive overall reputation in AI model monitoring and optimization communities.
Features
Use Cases
Industry
information technology & services
Employees
120
Funding Stage
Series C
Total Funding
$131.0M
444
GitHub followers
57
GitHub repos
9,104
GitHub stars
20
npm packages
6
HuggingFace models
Engineering the Autonomous Local Enterprise: A Technical Blueprint for Agentic RAG and Sovereign AI Infrastructure
# Engineering the Autonomous Local Enterprise: A Technical Blueprint for Agentic RAG and Sovereign AI Infrastructure The transition from reactive large language model applications to autonomous agentic workflows represents a fundamental paradigm shift in enterprise computing. In the 2025–2026 technological landscape, the industry has moved beyond simple chat interfaces toward systems capable of planning, executing, and refining multi-step workflows over extended temporal horizons. This evolution is underpinned by the convergence of high-performance local inference, sophisticated document understanding, and multi-agent orchestration frameworks that operate within a "sovereign stack"—an infrastructure entirely controlled by the organization to ensure data privacy, security, and operational resilience. The architecture of such a system requires a nuanced understanding of hardware constraints, the mathematical implications of model quantization, and the systemic challenges of retrieving context from high-volume, complex document sets. # Executive Summary: The Rise of Sovereign Intelligence The contemporary AI landscape is increasingly bifurcated between centralized cloud-based services and a burgeoning movement toward decentralized, sovereign intelligence. For organizations managing sensitive intellectual property, legal documents, or healthcare data, the reliance on third-party APIs introduces unacceptable risks regarding data residency, privacy, and long-term cost volatility. The primary mission of this report is to define the architecture for a fully local, production-ready system that leverages the most advanced open-source components from GitHub and Hugging Face. The proposed system integrates high-fidelity document ingestion, a multi-stage RAG pipeline, and an agentic orchestration layer capable of long-horizon reasoning. By utilizing reasoning models such as DeepSeek-R1 and Llama 3.3, and optimizing them through advanced quantization, the enterprise can achieve performance levels previously reserved for high-cost cloud providers. This architecture is further enhanced by comprehensive observability through the OpenTelemetry standard, ensuring that every reasoning step and retrieval operation is transparent and verifiable. # Phase 1: The Local Discovery Engine Identifying the optimal components for a local sovereign stack requires a rigorous evaluation of active maintenance, documentation quality, and community health. The following repositories and transformers represent the current state-of-the-art for local LLM deployment with agentic RAG. # Top GitHub Repositories for Local Agentic RAG |**Repository**|**Stars**|**Last Updated**|**Primary Language**|**Key Strength**|**Critical Limitation**| |:-|:-|:-|:-|:-|:-| |**langchain-ai/langchain**|125,000|2026-01|Python/TS|700+ integrations; modular agentic workflows.|High abstraction complexity; steep learning curve.| |**langgenius/dify**|114,000|2026-01|Python/TS|Visual drag-and-drop workflow builder; built-in RAG.|Less flexibility for custom low-level Python hacks.| |**infiniflow/ragflow**|70,000|2025-12|Python|Deep document understanding; visual chunk inspection.|Resource-heavy; requires robust GPU for layout parsing.| |**run-llama/llama\_index**|46,500|2025-12|Python/TS|Superior data indexing; 150+ data connectors.|Transition from ServiceContext to Settings can be confusing.| |**zylon-ai/private-gpt**|52,000|2025-11|Python|Production-ready; 100% offline; OpenAI API compatible.|Gradio UI is basic; designed primarily for document Q&A.| |**Mintplex-Labs/anything-llm**|25,000|2026-01|Node.js|All-in-one desktop/Docker app; multi-user support.|Workspace-based isolation can limit cross-context queries.| |**DSProject/Docling**|12,000|2026-01|Python|Industry-leading table extraction (97.9% accuracy).|Speed scales linearly with page count (slower than LlamaParse).| # Top Hugging Face Transformers for Reasoning and RAG |**Model**|**Downloads**|**Task**|**Base Model**|**Params**|**Hardware (4-bit)**|**Fine-tuning**| |:-|:-|:-|:-|:-|:-|:-| |**DeepSeek-R1-Distill-Qwen-32B**|2.1M|Reasoning|Qwen 2.5|32.7B|24GB VRAM (RTX 4090).|Yes (LoRA).| |**DeepSeek-R1-Distill-Llama-70B**|1.8M|Reasoning|Llama 3.3|70.6B|48GB VRAM (2x 4090).|Yes (LoRA).| |**Llama-3.3-70B-Instruct**|5.5M|General/RAG|Llama 3.3|70B|48GB VRAM (2x 4090).|Yes.| |**Qwen 2.5-72B-Instruct**|3.2M|Coding/RAG|Qwen 2.5|72B|48GB VRAM.|Yes.| |**Ministral-8B-Instruct**|800K|Edge RAG|Mistral|8B|8GB VRAM (RTX 3060).|Yes.| # Phase 2: Hardware Topographies and Inference Optimization The viability of local intelligence is strictly dictated by the memory bandwidth and VRAM capacity of the deployment target. In 2025, the release of the NVIDIA RTX 5090 introduced a significant leap in local capability, featuring 32GB of GDDR7 memory and a bandwidth of approximately 1,792 GB/s, representing a 77% improvement over its predecessor. # The Physics of Inference: Bandwidth vs. Compute A detailed 2025 NVIDIA research pap
View originalPricing found: $50, $10, $3
g2
What do you like best about Arize AI?I really like the presentation of the tracing in Arize AI; it's really good. I also like the auxiliary functionality such as experimentation, evaluators, and annotations. The initial setup was straightforward, and I received quite a bit of help from the customer support team, which made the process easier. Review collected by and hosted on G2.com.What do you dislike about Arize AI?I'd like more flexibility around the way LLMs are integrated for the judge functionality. It currently seems restricted to APIs with API keys, and it would be good to have other ways of connecting elements. Review collected by and hosted on G2.com.
What do you like best about Arize AI?I appreciate Arize AI for its ability to bridge the gap between development and production. I find the field level observability feature really useful as it allows me to compare, debug, and optimize models instead of only relying on high-level performance metrics. I also like that the initial setup is quick and intuitive, which makes it easy to get started. Review collected by and hosted on G2.com.What do you dislike about Arize AI?I dislike that the output isn't showing the dashboard correctly. Review collected by and hosted on G2.com.
What do you like best about Arize AI?Custom Code Evaluator and Live tracing projects. Review collected by and hosted on G2.com.What do you dislike about Arize AI?when you choose to run 10/20 rows in the playground by selecting the dataset. Instead of first 10 rows it randomly runs any 10 examples. Which doesn't helps with the consistency in running the evals Review collected by and hosted on G2.com.
What do you like best about Arize AI?I really like the evaluation aspect of Arize AI. It excels in running offline and online based evaluations, which is something I find valuable. I appreciate its ability to test against different prompts and LLM models by conducting various experiments. This feature is definitely a strength of the Arize AI platform. Review collected by and hosted on G2.com.What do you dislike about Arize AI?I think a couple of things I've already shared with the Arize support team. One is we would love to get more of the prompt management features or capabilities. It has got to do with categorizing these prompts by, you know, let’s say, by a BU or maybe by different verticals within the organization. Whether the prompt management capabilities have integration with data sources, external data sources. We definitely had challenges because we were, I think, one of the first guinea pigs in terms of integrating with the Arize platform. Arize, as a platform, didn't have out-of-the-box capability to support the integration at that point in time. So there was quite a bit of, you know, a few tweaks here and there in the core base that was done to get it up and running. Review collected by and hosted on G2.com.
What do you like best about Arize AI?I like how accessible it is to view traces, spans, and sessions, along with the evaluation methods. It’s also helpful that I can access them either through the UI or even offline. The filtering of data also makes it very easy to view the required spans, traces and sessions. Also the trace tree feature is very helpful to view the kind of each span. Review collected by and hosted on G2.com.What do you dislike about Arize AI?There’s really nothing to dislike. The only thing I’d change is making the filtration a bit simpler, because it took me a while to understand. Once I got how the filtration works, though, I was able to connect without any issues. Review collected by and hosted on G2.com.
What do you like best about Arize AI?It provides the metrics readily and allows for easy integration. Review collected by and hosted on G2.com.What do you dislike about Arize AI?Latency and custom instrumentation in most cases Review collected by and hosted on G2.com.
What do you like best about Arize AI?Their search and retrieval functionality is excellent, with a diverse set of tools for various issues that can come up. The langchain integration is also immensly helpful. Review collected by and hosted on G2.com.What do you dislike about Arize AI?They have not released their prompt improvement tool kit yet which could add significant value to the platform as a whole. Improving propmt flow is very relevant to most LLM related work today. Review collected by and hosted on G2.com.
What do you like best about Arize AI?Arize AI offers a comprehensive platform for monitoring machine learning models in real-time. The platform's ability to provide actionable insights into model drift, data issues, and performance degradation is particularly impressive. The user interface is intuitive, making it easy to track and understand the health of deployed models. The integration capabilities with various ML frameworks are also a significant upside, streamlining the process of setting up and monitoring models. Review collected by and hosted on G2.com.What do you dislike about Arize AI?While Arize AI offers a robust set of features, there can be a learning curve for those new to ML operations. Some advanced features might require a deeper understanding of the platform, and the documentation, while extensive, could be overwhelming for beginners. It would be beneficial if there were more beginner-friendly tutorials or guided walkthroughs. Review collected by and hosted on G2.com.
What do you like best about Arize AI?Optimising MLOps framework Feedback analysis Clustering approach to data analysis Documentation for quick implementation Review collected by and hosted on G2.com.What do you dislike about Arize AI?Software navigation bit complicated to understand at first Only cloud instance of the software, and need to share all the data in cloud . Review collected by and hosted on G2.com.
What do you like best about Arize AI?The product is crisp and I understood how it operates through courses. It has almost got everything for model monitoring and other important features. It helps in all the for ML operations. Review collected by and hosted on G2.com.What do you dislike about Arize AI?Arize AI, if I am not wrong is like a dashboard. It would have been better if there was an API sort of thing where we can leverage the features through a package. Review collected by and hosted on G2.com.
Engineering the Autonomous Local Enterprise: A Technical Blueprint for Agentic RAG and Sovereign AI Infrastructure
# Engineering the Autonomous Local Enterprise: A Technical Blueprint for Agentic RAG and Sovereign AI Infrastructure The transition from reactive large language model applications to autonomous agentic workflows represents a fundamental paradigm shift in enterprise computing. In the 2025–2026 technological landscape, the industry has moved beyond simple chat interfaces toward systems capable of planning, executing, and refining multi-step workflows over extended temporal horizons. This evolution is underpinned by the convergence of high-performance local inference, sophisticated document understanding, and multi-agent orchestration frameworks that operate within a "sovereign stack"—an infrastructure entirely controlled by the organization to ensure data privacy, security, and operational resilience. The architecture of such a system requires a nuanced understanding of hardware constraints, the mathematical implications of model quantization, and the systemic challenges of retrieving context from high-volume, complex document sets. # Executive Summary: The Rise of Sovereign Intelligence The contemporary AI landscape is increasingly bifurcated between centralized cloud-based services and a burgeoning movement toward decentralized, sovereign intelligence. For organizations managing sensitive intellectual property, legal documents, or healthcare data, the reliance on third-party APIs introduces unacceptable risks regarding data residency, privacy, and long-term cost volatility. The primary mission of this report is to define the architecture for a fully local, production-ready system that leverages the most advanced open-source components from GitHub and Hugging Face. The proposed system integrates high-fidelity document ingestion, a multi-stage RAG pipeline, and an agentic orchestration layer capable of long-horizon reasoning. By utilizing reasoning models such as DeepSeek-R1 and Llama 3.3, and optimizing them through advanced quantization, the enterprise can achieve performance levels previously reserved for high-cost cloud providers. This architecture is further enhanced by comprehensive observability through the OpenTelemetry standard, ensuring that every reasoning step and retrieval operation is transparent and verifiable. # Phase 1: The Local Discovery Engine Identifying the optimal components for a local sovereign stack requires a rigorous evaluation of active maintenance, documentation quality, and community health. The following repositories and transformers represent the current state-of-the-art for local LLM deployment with agentic RAG. # Top GitHub Repositories for Local Agentic RAG |**Repository**|**Stars**|**Last Updated**|**Primary Language**|**Key Strength**|**Critical Limitation**| |:-|:-|:-|:-|:-|:-| |**langchain-ai/langchain**|125,000|2026-01|Python/TS|700+ integrations; modular agentic workflows.|High abstraction complexity; steep learning curve.| |**langgenius/dify**|114,000|2026-01|Python/TS|Visual drag-and-drop workflow builder; built-in RAG.|Less flexibility for custom low-level Python hacks.| |**infiniflow/ragflow**|70,000|2025-12|Python|Deep document understanding; visual chunk inspection.|Resource-heavy; requires robust GPU for layout parsing.| |**run-llama/llama\_index**|46,500|2025-12|Python/TS|Superior data indexing; 150+ data connectors.|Transition from ServiceContext to Settings can be confusing.| |**zylon-ai/private-gpt**|52,000|2025-11|Python|Production-ready; 100% offline; OpenAI API compatible.|Gradio UI is basic; designed primarily for document Q&A.| |**Mintplex-Labs/anything-llm**|25,000|2026-01|Node.js|All-in-one desktop/Docker app; multi-user support.|Workspace-based isolation can limit cross-context queries.| |**DSProject/Docling**|12,000|2026-01|Python|Industry-leading table extraction (97.9% accuracy).|Speed scales linearly with page count (slower than LlamaParse).| # Top Hugging Face Transformers for Reasoning and RAG |**Model**|**Downloads**|**Task**|**Base Model**|**Params**|**Hardware (4-bit)**|**Fine-tuning**| |:-|:-|:-|:-|:-|:-|:-| |**DeepSeek-R1-Distill-Qwen-32B**|2.1M|Reasoning|Qwen 2.5|32.7B|24GB VRAM (RTX 4090).|Yes (LoRA).| |**DeepSeek-R1-Distill-Llama-70B**|1.8M|Reasoning|Llama 3.3|70.6B|48GB VRAM (2x 4090).|Yes (LoRA).| |**Llama-3.3-70B-Instruct**|5.5M|General/RAG|Llama 3.3|70B|48GB VRAM (2x 4090).|Yes.| |**Qwen 2.5-72B-Instruct**|3.2M|Coding/RAG|Qwen 2.5|72B|48GB VRAM.|Yes.| |**Ministral-8B-Instruct**|800K|Edge RAG|Mistral|8B|8GB VRAM (RTX 3060).|Yes.| # Phase 2: Hardware Topographies and Inference Optimization The viability of local intelligence is strictly dictated by the memory bandwidth and VRAM capacity of the deployment target. In 2025, the release of the NVIDIA RTX 5090 introduced a significant leap in local capability, featuring 32GB of GDDR7 memory and a bandwidth of approximately 1,792 GB/s, representing a 77% improvement over its predecessor. # The Physics of Inference: Bandwidth vs. Compute A detailed 2025 NVIDIA research pap
View originalRepository Audit Available
Deep analysis of Arize-ai/phoenix — architecture, costs, security, dependencies & more
Pricing found: $50, $10, $3
Arize AI has an average rating of 4.3 out of 5 stars based on 20 reviews from G2, Capterra, and TrustRadius.
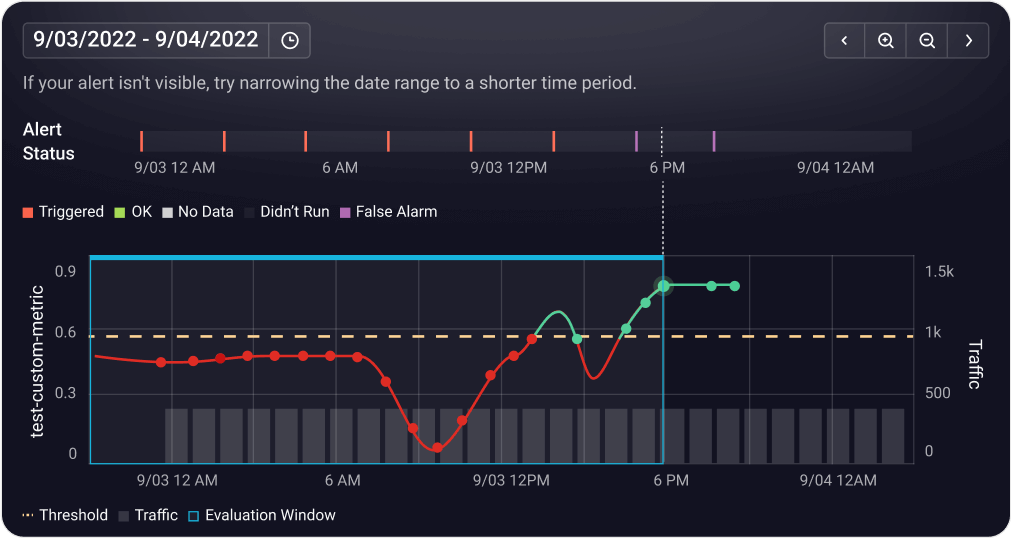
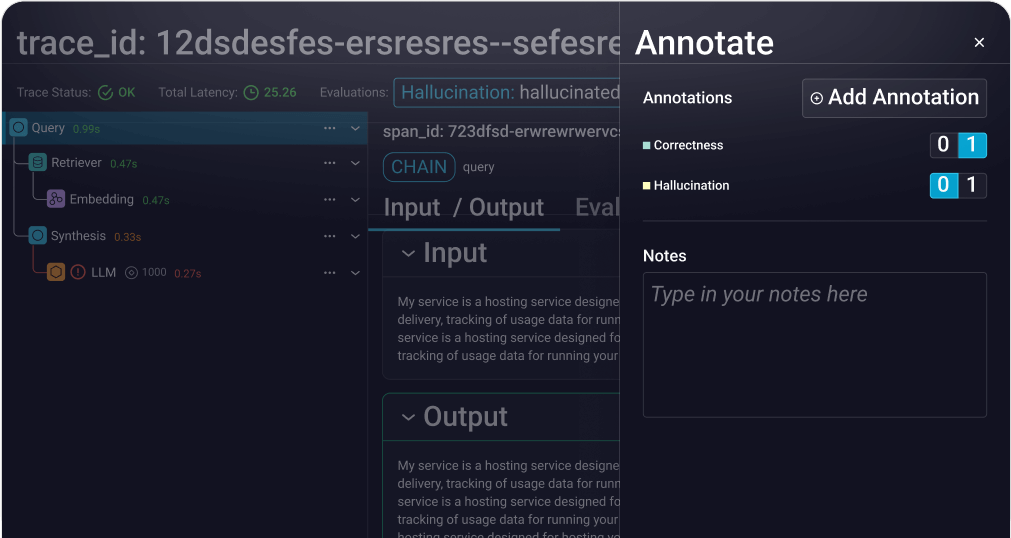
Key features include: Arize AX, Learn, Insights, Company, Tracing, Datasets and Experiments, Prompt Playground & Management, Evals Online and Offline.
Arize AI is commonly used for: Lou Kratz, PhD..
Arize AI integrates with: OpenTelemetry, AWS, Google Cloud, Azure, Kubernetes, TensorFlow, PyTorch, Scikit-learn, Jupyter, MLflow.
Arize AI has a public GitHub repository with 9,104 stars.
Cerebras
Company at Cerebras Systems
1 mention

Boost Claude Code performance with prompt learning - optimize your prompts automatically with evals
Apr 3, 2026




