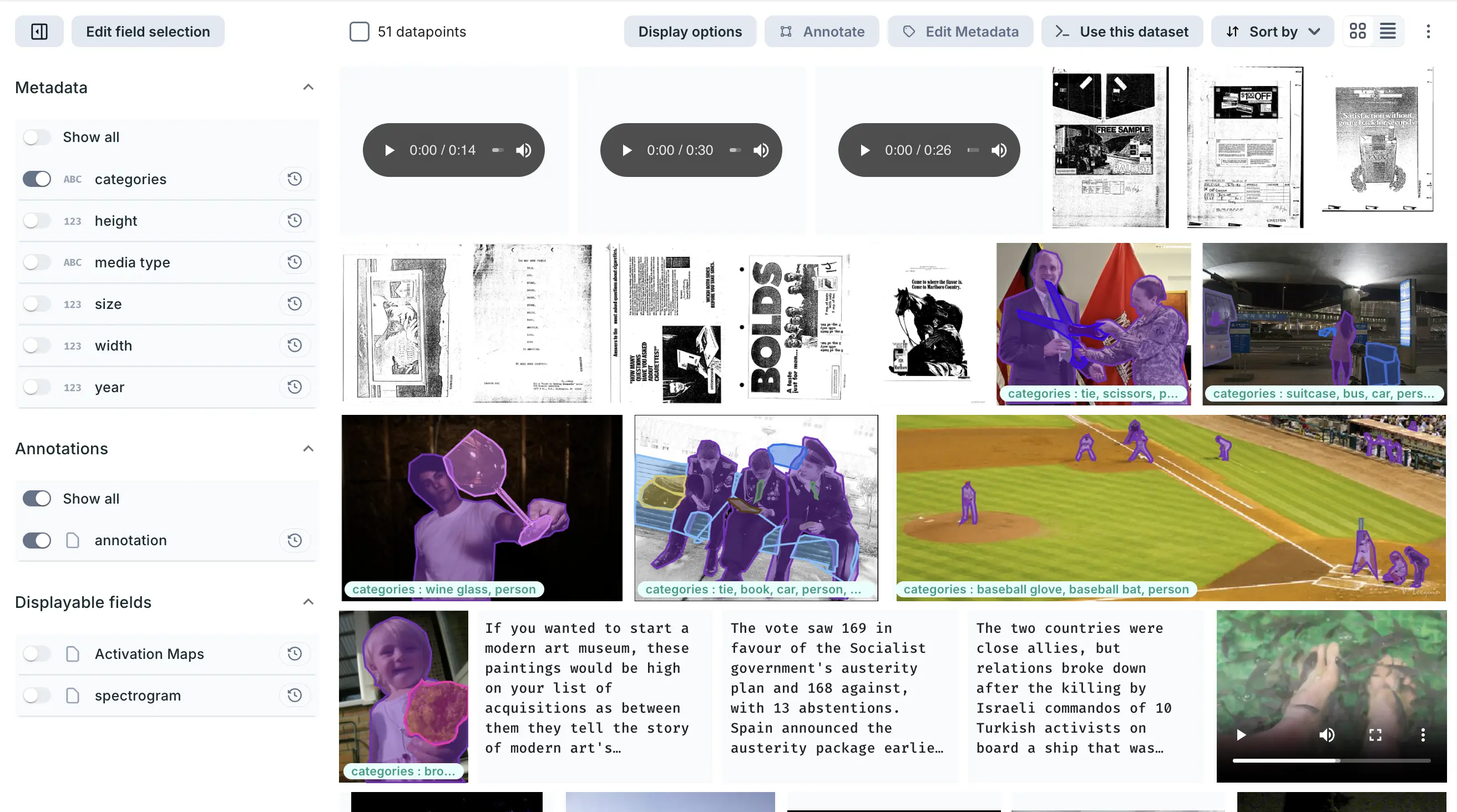
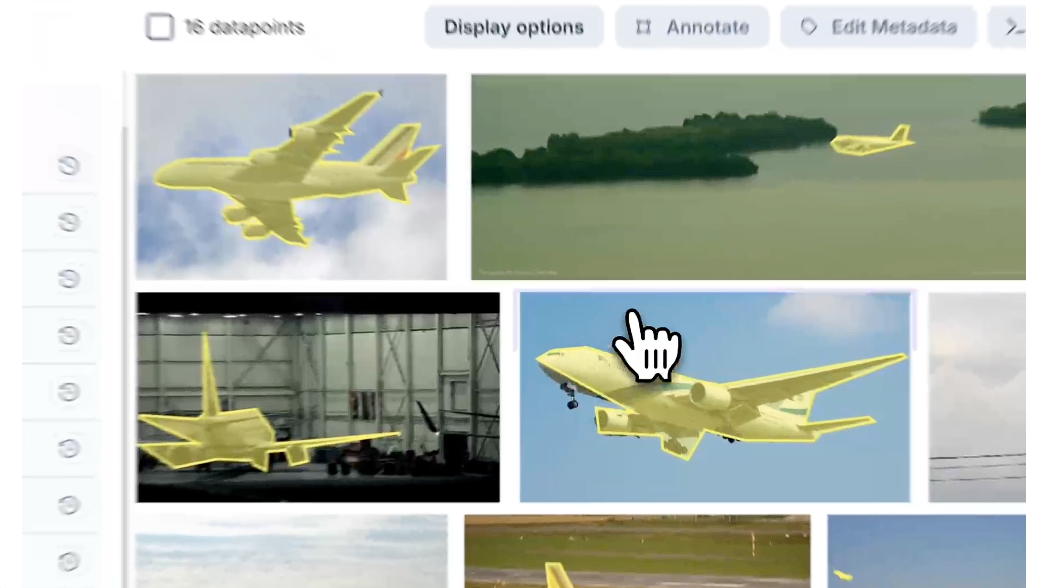
Curate and annotate vision, audio, and LLM datasets, track experiments, and manage models on a single platform
User feedback on DAGsHub highlights its strengths in seamless collaborative and version-controlled workflows for machine learning projects. Users appreciate its integration capabilities with popular data science tools and platforms. However, there are occasional mentions of a learning curve for new users, which can be a hurdle initially. Pricing sentiment is generally positive, with users feeling it's competitively priced for the features offered. Overall, DAGsHub enjoys a solid reputation as a robust and efficient platform for data science teams looking to streamline their ML operations.
Mentions (30d)
1
Reviews
0
Platforms
2
Sentiment
31%
4 positive

User feedback on DAGsHub highlights its strengths in seamless collaborative and version-controlled workflows for machine learning projects. Users appreciate its integration capabilities with popular data science tools and platforms. However, there are occasional mentions of a learning curve for new users, which can be a hurdle initially. Pricing sentiment is generally positive, with users feeling it's competitively priced for the features offered. Overall, DAGsHub enjoys a solid reputation as a robust and efficient platform for data science teams looking to streamline their ML operations.
Features
Use Cases
Industry
information technology & services
Employees
13
Funding Stage
Seed
Total Funding
$3.0M
Pricing found: $0, $0, $119, $99
I built Synapse AI: An open-source, DAG-based orchestrator for AI agents.
Hey Everyone, For the past three months, I’ve been building an open-source orchestration platform for AI agents called Synapse AI. I started this because I found existing frameworks (like LangChain or AutoGen) either too bloated or too unpredictable for production workflows. Letting agents freely "chat" with each other often leads to infinite loops, high API costs, and debugging nightmares. I wanted strict, predictable control. The Architecture: Instead of conversational routing, Synapse AI relies on a Directed Acyclic Graph (DAG) architecture. You define the work, strictly control the hand-offs between agents, and get a completed task on the other side. Under the Hood: Tool Agnostic: Build custom tools from scratch (Python/webhooks) or instantly plug in existing Model Context Protocol (MCP) servers. Local-First Emphasis: Full native support for Ollama so you can run routing and tasks entirely locally. (It also supports Gemini, Claude, and OpenAI for the heavy lifting). CLI Integration: Just shipped a community-requested feature to connect Claude Code, Gemini CLI, Codex CLI, and GitHub Copilot CLI directly to your agents. Frictionless Setup: A 1-step installation process across macOS, Windows, and Linux. What I'm looking for: I am currently maintaining this solo and rolling it out for an early pilot phase. I would love for this community to take a look under the hood. Specifically: Code Review: I’d love brutal feedback on the DAG implementation and overall architecture. Contributors & Collaborators: If you find the project worthwhile, I am actively looking for people to team up with! Whether it's adding new LLM providers, fixing UI quirks, or improving the 1-step installer, PRs are incredibly welcome. Repo: https://github.com/naveenraj-17/synapse-ai If you bump into any bugs, please drop an issue so I can patch it. Would love to hear your thoughts! submitted by /u/WabbaLubba-DubDub [link] [comments]
View originalBuilt an agent framework that runs Claude Code as the agentic loop: fractal architecture, inter-agent inboxes, schedulers, voice (pip install autonet-computer)
I built Autonet, an agent framework where the core agentic loop is Claude Code itself - not just API wrappers. Why Claude Code as the loop matters: Most agent frameworks wrap the API and build their own tool-calling logic. Autonet runs the actual Claude Code harness, which means you get all of Claude's native capabilities: file reading/writing, code execution, tool use, and reasoning - managed by the same system Anthropic built for Claude Code. Framework features: Fractal agent architecture - agents spawn sub-agents recursively. No rigid DAG. The hierarchy emerges from the task. Inter-agent inboxes - agents communicate through a notification/inbox system rather than passing context through a central orchestrator Built-in schedulers - agents can schedule recurring tasks, cron-style Open-ended shared tool library - agents share and extend tools across the hierarchy Voice integration - talk to your agents The framework also supports decentralized model training (VL-JEPA architecture with local decoders/encoders for distributed backprop), governed by an on-chain DAO: https://werule.io/#/Etherlink-Shadownet/0x7c83FF7b0356DbE332BFC527F1Ea73283974aEA2 pip install autonet-computer GitHub: https://github.com/autonet-code Site: https://autonet.computer Happy to answer questions. submitted by /u/EightRice [link] [comments]
View originalRAG is a trap for Claude Code. I built a DAG-based context compiler that cut my Opus token usage by 12x.
Hey everyone, If you’ve been using the new Claude Code CLI or building agents with Sonnet 3.5 / Opus on mid-to-large codebases, you’ve probably noticed a frustrating pattern. You tell Claude: "Implement a bookmark reordering feature in app/UseCases/ReorderBookmarks.ts." What happens next? Claude starts using its grep and find tools, exploring the codebase, trying to guess your architectural patterns. Or worse, if you use a standard RAG (Retrieval-Augmented Generation) MCP tool, it searches your docs for keywords like "bookmark" and completely misses the abstract architectural rules like "UseCases must not contain business logic" or "Use First-Class Collections". Because of this Semantic Gap, Claude hallucinates the architecture, writes a massive transaction script, and burns massive amounts of tokens just exploring your repo. I got tired of paying for Claude to "guess" my team's rules, so I built Aegis. Aegis is an MCP server, but it's not a search engine. It’s a deterministic Context Compiler. Instead of relying on fuzzy vector math (RAG), Aegis uses a Directed Acyclic Graph (DAG) backed by SQLite to map file paths directly to your architecture Markdown files. How it works with Claude: Claude plans to edit app/UseCases/Reorder.ts and calls the aegis_compile_context tool. Aegis deterministically maps this path to usecase_guidelines.md. Aegis traverses the DAG: "Oh, usecase_guidelines.md depends on entity_guidelines.md." It compiles these specific documents and feeds them back to Claude instantly. No guessing, no grepping. The Results (Benchmarked with Claude Opus on a Laravel project with 140+ UseCases): • Without Aegis: Claude grepped 30+ files, called tools 55 times, and burned 65.4k tokens just exploring the codebase to figure out how a UseCase should look. Response time: 2m 32s. • With Aegis: Claude was instantly fed the compiled architectural rules via MCP. Tool calls: 6. Output tokens: 1.8k. Response time: 43s. That's a 12x reduction in token waste and a 3.5x speedup. More importantly, the generated code actually respected our architectural decisions (ADRs) because Claude was forced to read them first. It runs 100% locally. If you want to stop hand-holding Claude through your architecture and save on API costs, give it a try. GitHub: https://github.com/fuwasegu/aegis I'd love to hear your thoughts or feedback! Has anyone else felt the pain of RAG when trying to enforce strict architecture with Claude? submitted by /u/fuwasegu [link] [comments]
View originalKarpathy just said "the human is the bottleneck" and "once agents fail, you blame yourself" — I built a system that fixes both problems
In the No Priors podcast posted 3 days ago, Karpathy described a feeling I know too well: He's spending 16 hours a day "expressing intent to agents," running parallel sessions, optimizing agents.md files — and still feeling like he's not keeping up. I've been in that exact loop. But I think the real problem isn't what Karpathy described. The real problem is one layer deeper: you stop understanding what your agents are doing, but everything keeps working — until it doesn't. Here's what happened to me: I was building an AI coding team with Claude Code. I approved architecture proposals I didn't understand. I pressed Enter on outputs I couldn't evaluate. Tests passed, so I assumed everything was fine. Then I gave the agent a direction that contradicted its own architecture — because I didn't know the architecture. We spent days on rework. I wasn't lazy. I was structurally unable to judge my agents' output. And no amount of "running more agents in parallel" fixes that. The problem no one is solving I surveyed the top 20 AI coding projects on star-history in March 2026 — GStack (Garry Tan's project, 16k+ stars), agency-agents, OpenCrew, OpenClaw, etc. Every single one stops at the same layer: they give you a powerful agent team, then assume you know who to call, when to call them, and how to evaluate their output. You're still the dispatcher. You went from manually prompting one agent to manually dispatching six. The cognitive load didn't decrease — it shifted. I mapped out 6 layers of what I call "decision caching" in AI-assisted development: Layer What gets cached You no longer need to... 0. Raw Prompt Nothing — 1. Skill Single task execution Prompt step by step 2. Pipeline Task dependencies Manually orchestrate skills 3. Agent Runtime decisions Choose which path to take 4. Agent Team Specialization Decide who does what 5. Secretary User intent Know who to call or how + Education Understanding Worry about falling behind Every project I found stops at Layer 4. Nobody is building Layer 5. What I built: Secretary Agent + Education System Secretary Agent — a routing layer that sits between you and a 6-agent team (Architect, Governor, Researcher, Developer, Tester + the Secretary itself). The key innovation is ABCDL classification — it doesn't classify what you're talking about, it classifies what you're doing: A = Thinking/exploring → routes to Architect for analysis B = Ready to execute → routes to Developer pipeline C = Asking a fact → Secretary answers directly D = Continuing previous work → resumes pipeline state L = Wants to learn → routes to education system Why this matters: "I think we should redesign Phase 3" and "Redesign Phase 3" are the same topic but completely different actions. Every existing triage/router system (including OpenAI Swarm) treats them identically. Mine doesn't. The first goes to research, the second goes to execution. When ambiguous, default to A. Overthinking is correctable. Premature execution might not be. Before dispatching, the Secretary does homework — reads files, checks governance docs, reviews history — then constructs a high-density briefing and shows it to you before sending. Because intent translation is where miscommunication happens most. The education system: the exam IS the course When you send a message that touches a knowledge domain you haven't been assessed on, the system asks: Before routing this to the Architect, I notice you haven't reviewed how the team pipeline works. This isn't a test you can fail — it's 8 minutes of real scenarios that show you how the system actually operates. A) Learn now (~8 min) B) Skip C) 30-second overview If you choose A, you get 3 scenario-based questions — not definitions, real situations: You answer. The system reveals the correct answer with reasoning. Testing effect (retrieval practice) — cognitive science shows testing itself produces better retention than re-reading. I just engineered it into the workflow. The anti-gaming design: every "shortcut" leads to learning. Read all answers in advance? You just studied. Skip everything? System records it, reminds you more frequently. Self-assess as "understood" but got 3 wrong? Diagnostic score tracked separately, advisory frequency auto-adjusts. It is impossible to game this system into "learning nothing." That's by design. Other things worth mentioning Agents can say no to you. Tell the Secretary to skip the preview gate, it pushes back: "Preview gating is mandatory. Skipping may cause routing errors. Override?" You can force it — you always can — but the override gets logged and the system learns. Cross-model adversarial review. The Architect proposes a solution, then attacks its own proposal using a second AI model (Gemini). Only proposals that survive cross-model scrutiny get through. Constitutional governance. 9 Architecture Decision Records protected by governance rules. You can't unilaterally change them
View originalI built Claudeck — a browser UI for Claude Code with agents, cost tracking, and a plugin system
I've been using Claude Code daily and wanted a visual interface that doesn't get in the way — so I built Claudeck, a browser-based UI that wraps the Claude Code SDK. One command to try it: npx claudeck@latest Here are the top 5 features: 1. Autonomous Agent Orchestration 4 built-in agents (PR Reviewer, Bug Hunter, Test Writer, Refactoring) plus agent chains, DAGs with a visual dependency graph editor, and an orchestrator that auto-delegates tasks to specialist agents. Full metrics dashboard with cost aggregation and success rates. 2. Cost & Token Visibility Per-session cost tracking with daily timeline charts, input/output token breakdowns, streaming token counter, and error pattern analysis across 9 categories. You always know exactly what you're spending. 3. Git Worktree Isolation Run any chat or agent task in an isolated git worktree — then merge, diff, or discard the results. Experiment freely without touching your working branch. 4. Persistent Cross-Session Memory Claudeck remembers project knowledge across sessions using SQLite with FTS5 full-text search. Auto-captures insights from conversations, supports manual /remember commands, and has AI-powered memory optimization via Claude Haiku. 5. Full-Stack Plugin System 7 built-in plugins (Linear, Tasks, Repos, Claude Editor, etc.) plus a user plugin directory at ~/.claudeck/plugins/ that persists across upgrades. Drop in a client.js and optionally server.js — no fork needed. Bonus Parallel mode (4 independent chats in a 2x2 grid), session branching, message recall with ↑, MCP server management, Telegram notifications with AFK approve/deny, Skills Marketplace integration, and installable as a PWA. Zero framework — vanilla JS, 6 npm dependencies, no build step Works on macOS, Linux, and Windows MIT licensed npm: npmjs.com/package/claudeck GitHub: github.com/hamedafarag/claudeck Happy to answer any questions or hear feature requests! submitted by /u/hafarag [link] [comments]
View originalI built a registry of 156 production-ready skills for Claude Code - think "plugins" that teach it domain expertise
Been frustrated that Claude Code is brilliant at writing code but has no persistent knowledge between sessions. Every new session, you're starting from scratch explaining your conventions. So I built AbsolutelySkilled — a registry of structured skill modules you install into Claude Code once, and they guide its behavior across all future sessions. **How it works:** Each "skill" is a SKILL.md file with structured knowledge that Claude Code loads when triggered. They're not just prompts — they include trigger conditions, reference files, evals (10-15 test cases per skill), and anti-patterns. **What I'm most proud of:** **Superhuman** — reimagines the entire dev lifecycle for AI constraints: - Decomposes work into dependency-graphed DAGs of sub-tasks - Executes independent tasks in parallel via sub-agents - Enforces TDD at every step with verification loops - Maintains a persistent `board.md` that survives across sessions/context resets - 7-phase workflow: INTAKE → DECOMPOSE → DISCOVER → PLAN → EXECUTE → VERIFY → CONVERGE **Second Brain** — persistent tag-indexed memory for your agent: - `~/.memory/` survives across ALL projects and sessions - 100-line file ceiling for context efficiency - Wiki-linked graph navigation - Auto-proposes learnings after complex tasks **The registry has 156 skills** including system design, Docker, Kubernetes, React, Next.js, PostgreSQL, security review, technical writing, SEO mastery, and way more. Install: ``` npx skills add AbsolutelySkilled/AbsolutelySkilled --skill superhuman ``` Or add everything at once: ``` npx skills add AbsolutelySkilled/AbsolutelySkilled -g ``` GitHub: https://github.com/AbsolutelySkilled/AbsolutelySkilled Would love feedback on the skill format and what skills you'd want to see added! submitted by /u/maddhruv [link] [comments]
View originalI built a workflow orchestrator with first-class Claude Code, Codex CLI, and Gemini CLI integration — generate, fix, and refine sysadmin tasks from natural language
I build and maintain Linux servers and got tired of the same cycle: something breaks, I cobble together shell commands to fix it, they work, and then I lose them to shell history. Next time the same thing breaks, I start from scratch. So I built workflow — a file-based workflow orchestrator with a TUI and CLI. The interesting part for this community: it has deep integration with AI coding CLIs. How the AI integration works: If claude (Claude Code), codex (Codex CLI), or gemini (Gemini CLI) is on your PATH, you get four capabilities: Generate — press a in the TUI, type "check nginx status, restart if down, send Slack alert on failure". The AI generates a multi-step YAML workflow with proper dependencies and error handling. Review before saving. Update — press A on any existing task. Type "add retry logic to the upload step" or "parallelize the independent checks". AI rewrites the YAML while preserving your structure. Fix — when a workflow fails, press a. The AI reads the error output, diagnoses the problem, and proposes corrected YAML. This is the one I use most at 2am. Refine — at any preview stage, press r to iteratively improve. "Add error handling" → preview → "also add logging" → preview → save. Multiple rounds supported. There's also a Claude Code skill included — install it and you can manage workflows entirely from Claude Code conversations. "Create a workflow for daily database backups." "Dry-run the staging deploy." "List my overdue tasks." This makes workflow a building block for agentic automation — AI agents can create, validate, and execute operational tasks through a file-based interface. The AI integration is tool-agnostic. It auto-detects whichever CLI you have installed. No API keys configured inside workflow itself — just authenticate your AI CLI tool and it works. Beyond the AI features: 42 bundled sysadmin/Docker/Kubernetes templates, DAG execution with retries and timeouts, overdue reminders, shell history import, git sync across machines. GitHub: https://github.com/vchaindz/workflow MIT licensed, single Rust binary. submitted by /u/codenotary [link] [comments]
View originalI built a framework to orchestrate multiple Claude Code agents working together as a team
I'm an AI student and I've been using Claude Code since 2025 for my projects. Claude Code was my main tool for building this, writing the kernel, adapters, CLI, tests. The project itself also uses Claude Code as its primary agent runtime. AgentOS lets you define teams of Claude Code agents in YAML, each with scoped tools, budgets, and roles, connected through a DAG with human approval gates: agents: researcher: adapter: tier2_claude_code tools: [file_read, file_write, web_search] role: "Research the latest developments on the topic." analyst: adapter: tier2_claude_code tools: [file_read, file_write] role: "Analyze findings and produce insights." tasks: gather_news: agent: researcher description: "Research ${topic}." review_gate: type: approval_gate depends_on: [gather_news] analyze_trends: agent: analyst depends_on: [review_gate] Then run it: agentos workflow run workflow.yaml --db run.db --param topic="AI regulation" --live --interactive AgentOS spawns Claude Code instances for each task, scopes their tools (the researcher gets web search, the analyst doesn't), enforces budget limits, and pauses at gates for your review. You can type feedback at a gate and it flows as context to the next agent. What it does: - Spawns real Claude Code processes with scoped tools and isolated workspaces - Hard budget limits (tokens, cost, time), agents stop cleanly when exceeded - Approval gates where you review, approve with guidance, or reject - Conditional branching: route to different agents based on task output - Manager agents that delegate to teams of specialists - Full event log: Every action recorded, replayable, exportable as compliance reports I've tested with up to 14 agents (hedge fund analysis pipeline with parallel research, adversarial validators, and compliance checks). There's a demo_run/ folder in the repo with the full output from a real run if you want to see what the agents actually produce. Current version is terminal-based. BUSL 1.1 licensed. GitHub: https://github.com/LucasPRLobo/AgentOS Feedback form: https://forms.gle/ZBsbSapfr1Zv54mNA Built with Claude Code, for Claude Code. Would love feedback on what works, what doesn't, what you'd use it for. Thanks! submitted by /u/POWERFUL-SHAO [link] [comments]
View originalYes, DAGsHub offers a free tier. Pricing found: $0, $0, $119, $99
Key features include: Sign In, Data and code versioning, Seamless connection with GitHub, Data and code Diffs, Data annotations, Visualizations, Experiments comparison, Metrics and parameters visualizations.
DAGsHub is commonly used for: Collaborative data science projects, Version control for machine learning models, Experiment tracking and management, Data annotation for training datasets, Visualizing model performance metrics, Comparing results of different experiments.
DAGsHub integrates with: GitHub, Slack, Jupyter Notebooks, TensorFlow, PyTorch, Keras, MLflow, DVC (Data Version Control), Google Cloud Storage, AWS S3.
Based on user reviews and social mentions, the most common pain points are: API costs, token usage, cost tracking.

How to Import Annotations into DagsHub
May 13, 2025
Based on 13 social mentions analyzed, 31% of sentiment is positive, 69% neutral, and 0% negative.




