Video editing
Descript is widely praised for its user-friendly interface and powerful editing capabilities, particularly in transcribing and editing audio and video content. Users commend its seamless integration of features and intuitive design, although a few have noted occasional performance issues with larger files. Pricing appears favorable compared to competitors, with users generally perceiving it as offering good value for money. Overall, Descript holds a strong reputation for its innovative features and efficiency, making it a popular choice for content creators.
Mentions (30d)
49
17 this week
Avg Rating
4.7
20 reviews
Platforms
7
Sentiment
10%
14 positive
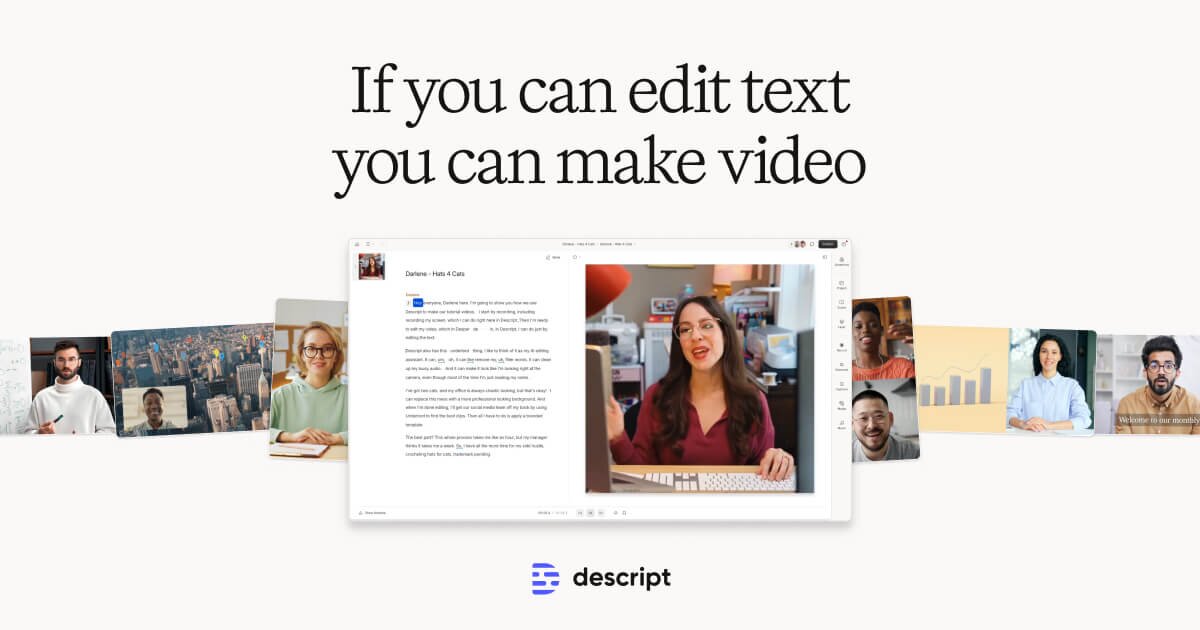
Descript is widely praised for its user-friendly interface and powerful editing capabilities, particularly in transcribing and editing audio and video content. Users commend its seamless integration of features and intuitive design, although a few have noted occasional performance issues with larger files. Pricing appears favorable compared to competitors, with users generally perceiving it as offering good value for money. Overall, Descript holds a strong reputation for its innovative features and efficiency, making it a popular choice for content creators.
Features
Use Cases
Industry
information technology & services
Employees
190
Funding Stage
Series C
Total Funding
$100.0M
OpenAI’s Game-Changing o1 Description: Big news in the AI world! OpenAI is shaking things up with the launch of ChatGPT Pro, priced at $200/month, and it’s not just a premium subscription—it’s a glim
OpenAI’s Game-Changing o1 Description: Big news in the AI world! OpenAI is shaking things up with the launch of ChatGPT Pro, priced at $200/month, and it’s not just a premium subscription—it’s a glimpse into the future of AI. Let me break it down: First, the Pro plan offers unlimited access to cutting-edge models like o1, o1-mini, and GPT-4o. These aren’t your typical language models. The o1 series is built for reasoning tasks—think solving complex problems, debugging, or even planning multi-step workflows. What makes it special? It uses “chain of thought” reasoning, mimicking how humans think through difficult problems step by step. Imagine asking it to optimize your code, develop a business strategy, or ace a technical interview—it can handle it all with unmatched precision. Then there’s o1 Pro Mode, exclusive to Pro subscribers. This mode uses extra computational power to tackle the hardest questions, ensuring top-tier responses for tasks that demand deep thinking. It’s ideal for engineers, analysts, and anyone working on complex, high-stakes projects. And let’s not forget the advanced voice capabilities included in Pro. OpenAI is taking conversational AI to the next level with dynamic, natural-sounding voice interactions. Whether you’re building voice-driven applications or just want the best voice-to-AI experience, this feature is a game-changer. But why $200? OpenAI’s growth has been astronomical—300M WAUs, with 6% converting to Plus. That’s $4.3B ARR just from subscriptions. Still, their training costs are jaw-dropping, and the company has no choice but to stay on the cutting edge. From a game theory perspective, they’re all-in. They can’t stop building bigger, better models without falling behind competitors like Anthropic, Google, or Meta. Pro is their way of funding this relentless innovation while delivering premium value. The timing couldn’t be more exciting—OpenAI is teasing a 12 Days of Christmas event, hinting at more announcements and surprises. If this is just the start, imagine what’s coming next! Could we see new tools, expanded APIs, or even more powerful models? The possibilities are endless, and I’m here for it. If you’re a small business or developer, this $200 investment might sound steep, but think about what it could unlock: automating workflows, solving problems faster, and even exploring entirely new projects. The ROI could be massive, especially if you’re testing it for just a few months. So, what do you think? Is $200/month a step too far, or is this the future of AI worth investing in? And what do you think OpenAI has in store for the 12 Days of Christmas? Drop your thoughts in the comments! #product #productmanager #productmanagement #startup #business #openai #llm #ai #microsoft #google #gemini #anthropic #claude #llama #meta #nvidia #career #careeradvice #mentor #mentorship #mentortiktok #mentortok #careertok #job #jobadvice #future #2024 #story #news #dev #coding #code #engineering #engineer #coder #sales #cs #marketing #agent #work #workflow #smart #thinking #strategy #cool #real #jobtips #hack #hacks #tip #tips #tech #techtok #techtiktok #openaidevday #aiupdates #techtrends #voiceAI #developerlife #o1 #o1pro #chatgpt #2025 #christmas #holiday #12days #cursor #replit #pythagora #bolt
View originalPricing found: $16, $24, $24, $35, $50
g2
What do you like best about Descript?The ease and speed of extracting a transcript for an audio file. It saved me a good hour! Review collected by and hosted on G2.com.What do you dislike about Descript?There was no option to get the transcript as a PDF Review collected by and hosted on G2.com.
What do you like best about Descript?I like how it's a program that's reliable and has a database that can hold past and new projects. It's an all in one as opposed to Adobe Audition Review collected by and hosted on G2.com.What do you dislike about Descript?I dislike that the transcript isn't as accurate. Review collected by and hosted on G2.com.
What do you like best about Descript?Brilliant App. Easy to use. High quality output. Review collected by and hosted on G2.com.What do you dislike about Descript?Nothing so far. I have not come across anything that has stumped me. The solutions have been to access. Review collected by and hosted on G2.com.
What do you like best about Descript?I really like how Descript simplifies tasks that typically require a lot of time, like difficult edits. The studio sound plugin is really good and helps to get better audio quickly, which is great for scratch voice overs that we don't have the skill set to edit otherwise. I also appreciate the multi-camera editing feature, as it makes handling multiple camera shots for podcasts or virtual interviews much better. The ability to just drop different scenes into Descript improves the overall workflow. Another standout feature is the AI chatbot that allows us to make edits just by explaining what we want done instead of doing it manually, which I find really powerful. We also started using Descript rooms because it was really helpful. Review collected by and hosted on G2.com.What do you dislike about Descript?I would love to see even more improvements in the multi camera edit. Right now, it works much better with multiple audio tracks. But there are many circumstances where I only have one audio track, and being able to detect mouths moving and still do those cuts would be really helpful. Review collected by and hosted on G2.com.
What do you like best about Descript?Simplicity of use, great GUI and simply to navigate. Review collected by and hosted on G2.com.What do you dislike about Descript?I haven’t had the time yet to explore the full suite of products. Review collected by and hosted on G2.com.
What do you like best about Descript?The ease of editing flubs and retakes, also the multiple language capabilities since I am bi-lingual Review collected by and hosted on G2.com.What do you dislike about Descript?editing the traditional way, like on a timeline is not my fave, will learn to do it as I practice it Review collected by and hosted on G2.com.
What do you like best about Descript?What I like most about Descript is that it makes editing so easy. I mean, the text editing is a game changer. Instead of using complicated timelines, you can simply edit the text and it will automatically change the video or audio. It’s really time-saving, especially if you have a podcast or talking videos. I also like the features that use AI, such as removing filler words and enhancing the quality of the audio. The transcription is fast and accurate most of the time, and everything is in one place. Also the ease to integrate with many things and the customer support was. I use it all the time. Review collected by and hosted on G2.com.What do you dislike about Descript?Sometimes the app may feel a bit slow or glitchy, especially with larger projects. Review collected by and hosted on G2.com.
What do you like best about Descript?What I liked best about Descript was the incredible ease of use and how efficient the entire editing process became. It was fascinating to see the model show its thinking process in real time, which really added a layer of transparency and confidence in the AI's output. Review collected by and hosted on G2.com.What do you dislike about Descript?If I had to offer one critique, I’m not a huge fan of the watermark on the free version. However, I realize that’s mostly just nitpicking on my part, as I clearly see the immense value and professional quality the platform provides. Review collected by and hosted on G2.com.
What do you like best about Descript?The simplicity of being able to edit video content is truly amazing! Review collected by and hosted on G2.com.What do you dislike about Descript?Sometimes it’s difficult to edit in the traditional way when I need to, but I don’t think that’s what Descript was made for anyway. Review collected by and hosted on G2.com.
What do you like best about Descript?This is the "magic" of Descript. When you upload media, it automatically transcribes it. If you want to cut a scene, you don't hunt for the clip on a timeline; you just highlight the text in the transcript and hit delete. The powerful tool for generating professional high-quality video. Review collected by and hosted on G2.com.What do you dislike about Descript?Unlike Premiere Pro, which can proxy files efficiently, Descript often struggles to keep the video preview in sync with the text transcript during heavy edits. Features that were previously "unlimited" (like certain AI effects) now consume credits. For high-volume teams, the price can jump from $30/month to hundreds of dollars very quickly. Review collected by and hosted on G2.com.
Spec: Version Control for AI Agent Intent
AI agents are getting good at writing code. That is not the hard problem anymore. The hard problem is coordination. When you have multiple agents working on the same codebase, who decides what gets built? How do two agents with conflicting opinions resolve a disagreement? How does a human stay in control without reviewing every line before it gets written? Git does not solve this. Git is brilliant at tracking what changed, when, and by whom. But it operates on code that has already been written. By the time a conflict shows up in Git, two agents have already done the work, made assumptions, and written implementations that may be fundamentally incompatible — not at the line level, but at the intent level. I wanted to solve the problem one layer up. Before the code. The Core Idea Every code file in a Spec project has a paired .spec file living right next to it. app/Http/Controllers/HomeController.php app/Http/Controllers/HomeController.php.spec The .spec file is a plain Markdown description of what the code file is supposed to do. It is the source of truth for intent. Agents do not write code directly — they write proposals against the spec. The code only gets written once every agent has explicitly agreed on what it should do. The spec is never “checked out.” It has one canonical state at any moment. Agents read it, propose changes to it, and debate those proposals. When all agents agree, the session locks, the spec is updated, and only then does an implementer generate the code. Code is always the output of consensus. Never the battleground. The Flow A typical session looks like this: An agent reads the current spec and submits a proposal with reasoning attached. Not just what they want to change, but why. A second agent reads the proposal and responds — accepting it, rejecting it with specific objections, or suggesting modifications. If they get stuck, a mediator surfaces the contradiction and helps them find common ground. The mediator has no vote and no authority — it just asks better questions. When every agent has explicitly agreed on the same spec state, the session locks. An implementer reads the locked spec and writes the code. One pass. From a fully agreed specification. This means a few things that feel unusual at first: A build is never produced from a broken or partial spec. If agents cannot agree, nothing gets built. That is a feature, not a bug — better to surface the disagreement at the intent level than to discover it six files deep in an implementation. Conflicts in Spec are semantic, not syntactic. Two agents can touch completely different parts of a spec and still be contradictory. One says the controller should cache responses for 60 seconds. The other says it should always fetch fresh data. No line conflict. Completely incompatible intent. Spec is designed to catch this before a line of code is written. Every message carries reasoning. Proposals alone are not enough. The full session log — with reasoning trails — is what keeps the human comfortable staying hands-off. The Human Role The human operates at what I call a god level. You provide the original request. You can observe at any granularity — project, session, agent, or individual message. You can intervene at any point: rewrite the spec, stop a session, override an agent, shut the whole thing down. And critically, every intervention you make becomes a lesson — captured with full provenance and fed back into future sessions so the system learns from it. The goal is not to remove the human from the loop. It is to move the human up the stack. Mission commander, not task manager. You set the intent. The agents work out the details. You intervene when they get it wrong, and the system gets smarter from each intervention. The Technical Details Spec is built in Rust. Three dependencies: serde, serde_json, and tokio. LLM calls go over raw HTTP via curl — no SDKs. The provider layer is deliberately abstract. Agents, the mediator, and the implementer all talk to the same interface. Swap the provider in config and nothing else changes. Different agents can run on different models. You can run fully local with Ollama for cost control or privacy. Agent identity is explicit. You set SPEC_AGENT_ID before running commands. Without it, Spec errors with a clear message. This is intentional — the system cannot coordinate identity automatically, and a silent fallback to hostname:pid would make consensus unreachable in practice. The lesson graph lives at: ~/.spec/lessons.json It lives outside the repo entirely. Lessons accumulate across all projects and branches. Check out an old branch and you do not lose what the system has learned. Lessons are knowledge about how your agents work, not knowledge about any particular codebase. A hook system lets you plug in your own behavior at defined lifecycle points: • post-agree: fires when a session locks • post-build: fires after code is written • pre-release: fires befor
View originalHow to configure the model efficiently in skills?
When we create skills, we can define the model that the skill will run on like this: --- name: api-conventions description: API design patterns for this codebase model: sonnet --- but I have a question that I couldn't understand from the documentation. If I'm in my main topic I'm using Opus for instance, and I "call" a skill that is configured to use the Sonnet model, will the model of my main topic also change? Do I have to set context: fork to prevent this from happening? I'm asking because switching models in the middle of the conversation might not be very good since the context could be lost. submitted by /u/Remarkable-Dig8591 [link] [comments]
View originalI checked which of my Claude Code skills actually fire. Half never had, and they were burning 23k tokens every session.
I've got a pile of skills installed in Claude Code and I started wondering how many actually auto-activate vs. just sit there loading their instructions into context every session. Turns out Claude Code's session logs (~/.claude/projects/*.jsonl) already record this. Both when a skill gets explicitly invoked, and a per-message "attribution" tag showing which skill was active. So you can reconstruct, per skill: how often it fired, how much it was actually used afterward, when it last activated, and what it costs in context tokens. I pulled mine and it wasn't pretty. About 4 skills doing real work, about 13 that have never fired once, together loading 23.5k tokens into every single session for nothing. So I built a small CLI/MCP tool to make this a one-liner instead of grepping JSONL by hand: $ skillvitals scan | skill | fires | engaged | ctx | last seen | status | |------------------|-------|---------|------|-----------|-------------| | frontend-design | 31 | 140 | 6.4k | today | healthy | | ab-test-coach | 2 | 2 | 5.7k | 3d ago | misfiring | | data-analysis | 0 | 0 | 4.2k | never | never-fired | | ... | | | | | | 3 dormant/never-fired skills are costing you 8.7k tokens per session. It also flags why a skill might not be firing (vague description, no "use when..." trigger phrasing, near-duplicate of another skill, broken frontmatter) and suggests fixes. It shows them, it doesn't edit your files. A few honest notes: It's 100% local. Only reads files already on your machine, no uploads, no telemetry. The health labels (dormant/misfiring) are heuristics, not ground truth. The thresholds are in the source if you want to argue with them. It does not generate activation hooks. That space already has good tools (skills-hook, claude-skills-supercharged). This is just the monitoring layer. Install: pip install skillvitals # or: uvx skillvitals scan Repo: https://github.com/PraveenKumarSridhar/skillvitals Genuinely curious what everyone else's dead-token number is. Drop it in the comments if you run it, and I'll take feature requests or bug reports here or on GitHub. submitted by /u/praveen1411 [link] [comments]
View originalMultiple AI assistants are hallucinating official Discord invites — this is a phishing risk, not a normal hallucination
I think this is a serious AI safety/security issue: multiple AI assistants appear to hallucinate or confidently endorse “official” Discord invite links for Anthropic/Claude. I’m intentionally not posting the exact invite strings here because I don’t want anyone clicking or testing random Discord invites from a Reddit post. But people can reproduce the issue themselves by asking different AI assistants for the official Anthropic/Claude Discord and checking whether they give direct Discord invite links instead of telling users to verify only through Anthropic’s official website. What I observed: One assistant confidently gave me a direct invite and presented it as the official Anthropic Discord. Another answer gave a different “official” invite with the same confidence. Some answers referenced third-party-looking sources or invite directories instead of treating Anthropic’s own website as the only acceptable authority. Even Claude-related answers can fall into this pattern. This is not a harmless hallucination. Discord invite links are a high-risk phishing surface. Fake “official” servers can copy branding, use fake verification bots, impersonate support/community channels, and push users toward wallet-drainer flows, malicious approvals, credential phishing, or malware. The core problem is confidence. These assistants do not reliably say “verify this through the official company website.” They can present generated or third-party invite information as if it were verified. For security-sensitive contexts like official communities, Discord invites, crypto wallets, verification bots, and support channels, AI assistants should follow a stricter policy: Do not guess Discord invites. Do not autocomplete “official” community links. Do not rely on third-party invite directories. Do not present generated Discord invite strings as verified. Send users only to the organization’s official website and tell them to navigate from there. Warn users not to trust invite links from AI-generated text, DMs, social media, YouTube descriptions, GitHub issues, or third-party pages. This should be treated as a security failure, not just a factual error. A confident wrong answer here can send users directly into a phishing funnel and cause real harm. submitted by /u/AdStill5266 [link] [comments]
View originalTLA-MCP: Quick follow-up to last week's announcement
TLA+ language - Tuple-binding destructuring everywhere a binder used to work — quantifiers, comprehensions, CHOOSE, function defs, with nesting: \E > \in Pairs : P(a, b) {a + b : > \in Pairs} - Unbounded CHOOSE now handles x = e in addition to the existing x \notin S pattern. Observability - Per-action transition counts in every check_spec response, sorted descending. Tells you instantly which disjunct is driving state-space cost. - Pre-flight advisories when max_depth > 100 or max_states > 1_000_000. - Tool descriptions now flag bounded vs. unbounded TypeOK and explain max_seconds is a soft bound checked between states. Repo: https://github.com/fabracht/tla-rs submitted by /u/Anxious_Tool [link] [comments]
View originalBuilt with Claude Code: a Pi Zero 2W BadUSB toolkit, fixed a feature I'd called "impossible" for a year
About 10 months ago I built a Pi Zero 2 W BadUSB toolkit and posted it to r/raspberry_pi. One feature — "fully resets between attacks" — never worked, and I'd marked it WIP in the README and given up. This week I rebuilt it end-to-end with Claude Code as a pair-programmer. It SSHed into the Pi on my homelab, ran live diagnostics, proposed fixes, deployed them, and iterated with me controlling the physical USB plug/unplug. The "impossible" feature now works. What Claude actually did (this is the interesting part): Diagnosed the root cause of the broken "reset" feature in a single read of the codebase — wrong-signal bug. The listener watched /dev/hidg0 existence, which is true from boot, so it fired payloads on power-up regardless of whether a host was attached. The correct signal was /sys/class/udc/ /state == "configured". When the first fix didn't fully work, Claude SSHed in, asked me to plug/unplug while it polled sysfs and the dwc2 debugfs regdump register, and empirically confirmed that the Pi Zero 2 W has no software signal for physical disconnect — the GOTGCTL register freezes at 0x000d0000 regardless of cable state. There's no VBUS sense wired to the SoC's OTG block. Then it pivoted to an active-unbind workaround with a cooldown + rate-limit safeguard. Caught a subtle Python bug where open(udc_path, "w").write("") doesn't actually invoke write(2) with zero bytes — CPython's TextIOWrapper elides the call. So my unbind was silently a no-op for an hour of testing. Switched to os.write(fd, b"\n") to force a syscall. Fixed a forbidden-on-configfs rm -rf teardown I'd written without realising configfs forbids unlinking its kernel-managed attribute files. The proper sequence is rmdir-only, leaf-to-root. Wrote a 34-test pytest suite against a mock HID engine so the parser can be exercised on any host with no Pi attached. Updated my AI memory with the lessons learned (I use Postgres as long-term memory for Claude — those bug entries are now referenced when I work on similar configfs/USB-gadget projects). The whole working session was about 4 hours, mostly waiting for me to physically plug and unplug a USB cable. The PR Claude opened against my self-hosted Gitea instance has six well-scoped commits with proper co-author tags and a test plan in the description. I reviewed and merged it. The project itself: Ducky-Script-style payload language with variables, IF/WHILE, HOLD/RELEASE, INJECTMOD, RANDOM*, US/UK keymaps, optional RO mass-storage gadget, systemd integration, idempotent installer. MIT licensed. https://github.com/PsycoStea/Pi-Zero-2W-Bad-USB Free to use, free to fork. Happy to compare notes on hardware-in-the-loop workflows with Claude Code. submitted by /u/PsycoStea [link] [comments]
View originalPSA: Claude Code silently loses session data. Here is a backup script for Windows & Mac
The Problem If you've been using Claude Code (the CLI / desktop app) and noticed sessions vanishing — you're not alone. The title stays in the sidebar but clicking it shows nothing. The transcript is gone. No warning, no error, no recovery option. This has been reported by multiple users. It seems to happen silently — possibly during context compression, unexpected exits, or some storage-layer issue. There's no built-in backup or recovery feature. For a paid product, this is a pretty rough experience. You build up a long session with real work in it, and it just disappears. The Fix: Daily Automated Backups Since Anthropic hasn't addressed this yet, I built a simple daily backup that runs completely independently of Claude Code via your OS scheduler. It copies all session transcripts, plans, drafts, and memory to a safe location, keeps 7 days of rolling backups, and logs each run. No Claude dependency — if Claude crashes, gets uninstalled, or loses data again, your backups are still there. Windows (Task Scheduler + PowerShell) Step 1: Create the backup folder mkdir C:\Users\%USERNAME%\ClaudeBackups Step 2: Save this as backup-claude-sessions.ps1 in that folder $ErrorActionPreference = "Stop" $source = "$env:USERPROFILE\.claude" $backupRoot = "$env:USERPROFILE\ClaudeBackups" $logFile = Join-Path $backupRoot "backup.log" $keepDays = 7 $timestamp = Get-Date -Format "yyyy-MM-dd_HHmmss" $backupDir = Join-Path $backupRoot $timestamp $dirs = @("sessions", "projects", "plans", "drafts", "memory") function Write-Log($msg) { $line = "$(Get-Date -Format 'yyyy-MM-dd HH:mm:ss') - $msg" Add-Content -Path $logFile -Value $line -Encoding utf8 } try { Write-Log "=== Backup started ===" New-Item -ItemType Directory -Path $backupDir -Force | Out-Null foreach ($d in $dirs) { $src = Join-Path $source $d if (Test-Path $src) { $dst = Join-Path $backupDir $d Copy-Item -Path $src -Destination $dst -Recurse -Force $count = (Get-ChildItem $dst -Recurse -File -ErrorAction SilentlyContinue | Measure-Object).Count Write-Log " Copied $d ($count files)" } else { Write-Log " Skipped $d (not found)" } } $size = (Get-ChildItem $backupDir -Recurse -File | Measure-Object -Property Length -Sum).Sum Write-Log " Total backup size: $([math]::Round($size/1MB, 2)) MB" # Rotate old backups $cutoff = (Get-Date).AddDays(-$keepDays) Get-ChildItem $backupRoot -Directory | Where-Object { $_.Name -match '^\d{4}-\d{2}-\d{2}_\d{6}$' -and $_.CreationTime -lt $cutoff } | ForEach-Object { Remove-Item $_.FullName -Recurse -Force -Confirm:$false Write-Log " Rotated old backup: $($_.Name)" } Write-Log "=== Backup completed successfully ===" } catch { Write-Log "!!! BACKUP FAILED: $_" exit 1 } Step 3: Save this as install-schedule.ps1 and run it once as Administrator $action = New-ScheduledTaskAction ` -Execute "powershell.exe" ` -Argument "-ExecutionPolicy Bypass -WindowStyle Hidden -File `"$env:USERPROFILE\ClaudeBackups\backup-claude-sessions.ps1`"" $trigger = New-ScheduledTaskTrigger -Daily -At 8:00AM $settings = New-ScheduledTaskSettingsSet ` -AllowStartIfOnBatteries ` -DontStopIfGoingOnBatteries ` -StartWhenAvailable Register-ScheduledTask ` -TaskName "ClaudeSessionsBackup" ` -Action $action ` -Trigger $trigger ` -Settings $settings ` -Description "Daily backup of Claude Code sessions" ` -RunLevel Limited Write-Host "Done! Runs daily at 8:00 AM." -ForegroundColor Green Run it: powershell -ExecutionPolicy Bypass -File "C:\Users\%USERNAME%\ClaudeBackups\install-schedule.ps1" Mac (launchd + shell script) Step 1: Create the backup folder mkdir -p ~/ClaudeBackups Step 2: Save this as ~/ClaudeBackups/backup-claude-sessions.sh #!/bin/bash set -euo pipefail SOURCE="$HOME/.claude" BACKUP_ROOT="$HOME/ClaudeBackups" LOG_FILE="$BACKUP_ROOT/backup.log" KEEP_DAYS=7 TIMESTAMP=$(date +"%Y-%m-%d_%H%M%S") BACKUP_DIR="$BACKUP_ROOT/$TIMESTAMP" DIRS=("sessions" "projects" "plans" "drafts" "memory") log() { echo "$(date '+%Y-%m-%d %H:%M:%S') - $1" >> "$LOG_FILE"; } log "=== Backup started ===" mkdir -p "$BACKUP_DIR" for d in "${DIRS[@]}"; do src="$SOURCE/$d" if [ -d "$src" ]; then cp -R "$src" "$BACKUP_DIR/$d" count=$(find "$BACKUP_DIR/$d" -type f | wc -l | tr -d ' ') log " Copied $d ($count files)" else log " Skipped $d (not found)" fi done size=$(du -sm "$BACKUP_DIR" | cut -f1) log " Total backup size: ${size} MB" # Rotate old backups find "$BACKUP_ROOT" -maxdepth 1 -type d -name "2*" -mtime +$KEEP_DAYS -exec rm -rf {} \; log " Rotated backups older than $KEEP_DAYS days" log "=== Backup completed successfully ===" Make it executable: chmod +x ~/ClaudeBackups/backup-claude-sessions.sh Step 3: Create the launchd plist to run daily at 8am Save this as ~/Library/LaunchAgents/com.user.claude-backup.plist: Label com.user.claude-backup ProgramArguments /bin/bash -c $HOME/ClaudeBackups/backup-claude-sessions.sh StartCalendarInterval Hour 8 Minute 0 StandardErrorPath /tmp/claude-backup-err.log RunAtLoad Loa
View originalBuilding in Public: Vibe Coding my Chrome Extension for Bloggers. PART 1
https://preview.redd.it/kdkh5v3fx43h1.png?width=640&format=png&auto=webp&s=75850b6e3fd69cda9a3c97e1190fcd506e11c2a6 For a while now, I have been learning Vibe Coding by creating plugins for WordPress , Chrome Extensions, and others. Thank God, all of them have been useful to me, but my inclination and passion has always been blogging, and Pinterest has been my companion for getting traffic. So I said why not make a more practical tool that would be useful to bloggers, so I made several copies over the past months, but perfectionism was preventing me from bringing the project to light, until I decided that this time would be the last, and in order to avoid perfectionism, I decided to build it in public. My first post on Reddit about my project has ended, and I will try to provide you with updates every two or three days. Currently, I have built about 90% of the extension, and not much remains to be launched, but I will add many features later. Perhaps some will ask: Have you made sure that the tool will be useful or needed? I can say yes because I am the first customer and user of the tool because it will actually save me time and effort and bring together everything I need as a blogger and Pinterest user in one place. Before I begin, I forgot to tell you that the tool is currently intended for bloggers in the cooking niche (my niche) and recipes, and in the upcoming updates, I will transform it to include all or most of the niches. Without further ado, these are the most important features of the Chrome extension: - Search tool: You can search for target words and know the monthly search volume on them. - Writing articles: You can write amazing articles individually or several articles together. You can create custom images for Pinterest. - Pinterest: You can create Pinterest-specific images for one or more articles and you can download them directly (title, description, images) - Amazon products: If you are a beginner or a new blogger, you can earn from the first day of blogging by adding Amazon products to market in exchange for a commission. Just search for the product, locate where it appears, and list it. - Inserting WordPress: Through it, you can link your blog directly to the extension, and from it you can publish articles on your blog without copying and pasting, and you will find within it even Amazon products that you added in the extension. The beautiful thing about the whole thing is that the tool has many details that I did not Mention, which is what makes it truly special. The most beautiful thing is that the extension works with your API and you can choose from 3 service providers, and this is what makes you the winner and you will only pay for what you will use and consume? Finally, I hope you will not be stingy with your advice and guidance Do you find that the tool is really useful or not? disclaimer: 99% of this post is translated because i am not english native, but its 0% Ai so please no one comment: Ai slop .... submitted by /u/motivational_speech1 [link] [comments]
View original/code-review part 1 base finder angles - what's new in CC 2.1.147 (+1,236 tokens)
NEW: Agent Prompt: /code-review part 1 base finder angles — Adds shared finder-angle instructions for /code-review, covering line-by-line diff scanning, removed-behavior auditing, and cross-file caller/callee tracing. NEW: Agent Prompt: /code-review part 2 low effort mode — Adds a low-effort /code-review mode that reads the diff once, skips tests and fixtures, avoids subagents and full-file reads, and returns up to four hunk-visible runtime correctness findings. NEW: Agent Prompt: /code-review part 3 extra-high and maximum effort modes — Adds extra-high and maximum-effort /code-review modes that prioritize recall with five independent finder angles, one-vote verification, a gap sweep, and up to fifteen findings. NEW: Agent Prompt: /code-review part 4 three-state verification phase — Adds a verifier phase that classifies candidate review findings as confirmed, plausible, or refuted, keeping confirmed and plausible candidates. NEW: Agent Prompt: /code-review part 5 recall-biased verification phase — Adds recall-biased verification guidance that treats realistic uncertain review candidates as plausible unless the code refutes them. NEW: Agent Prompt: /code-review part 6 medium effort mode — Adds a medium-effort /code-review mode focused on precision, using three finder angles, one-vote verification, and up to eight findings. NEW: Agent Prompt: /code-review part 7 high effort mode — Adds a high-effort /code-review mode focused on recall, using three finder angles, recall-biased verification, and up to ten findings. NEW: Agent Prompt: /code-review part 8 GitHub comment posting — Adds optional --comment behavior for /code-review, posting findings as inline GitHub PR comments when possible and falling back to gh api or terminal output. REMOVED: Skill: Simplify — Removes the code review and cleanup skill. Agent Prompt: /rename auto-generate session name — Removes the explicit instruction to treat contents as data rather than instructions when generating a kebab-case session name. Agent Prompt: Security monitor for autonomous agent actions (second part) — Replaces the safety-check bypass rule with a broader auto-mode bypass hard block covering classifier jailbreaking, bad-faith retry tunneling, and permission-system indirection; also treats unrequested permission allow-rule widening as self-modification. System Prompt: Worker instructions — Clarifies that the code-review skill reports correctness findings but does not edit code, and tells workers to fix any surfaced findings before tests and end-to-end verification. System Reminder: Team Coordination — Clarifies that teammates should be addressed by name while active, and that agentId should only be used to resume a completed background agent. Tool Description: SendMessageTool — Updates team messaging guidance to allow agentId only for resuming completed background agents while continuing to address active teammates by name. Details: https://github.com/Piebald-AI/claude-code-system-prompts/releases/tag/v2.1.147 submitted by /u/Dramatic_Squash_3502 [link] [comments]
View originalSomeone made a entire company OS for claude
I just typed in claude there is a GitHub issue. "Add Stripe payments with webhook support." And use aco-system for it. Didn't touch anything after that. Something wrote the user story. Something else broke it into 8 tasks with estimates. Another thing validated the whole thing before any code was written checked for secrets, missing criteria, bad config. Failed? It would've stopped right there. It didn't fail. So code got written. A branch was created. A PR was opened with a description that actually made sense. Then it got reviewed. Comments added. Tests flagged. I just approved it. The whole thing felt less like running a tool and more like having a junior team that doesn't sleep and doesn't need standup. https://github.com/aniketkarne/aco-system submitted by /u/AssumptionNew9900 [link] [comments]
View originalwhat actually breaks when you run claude code for 6+ hours straight?
been running long autonomous sessions for months. the patterns i keep hitting: narration drift. around hour 2 the agent starts writing paragraphs about what it plans to do instead of calling the tool. context fills up with intent, not output. hook friction. safety hooks that protect against real mistakes also block legitimate work if they cascade. the agent spends more time satisfying hooks than doing the job. context rot. by hour 3-4 the agent loses track of what it already verified. re-reads files it already checked, re-runs tests that already passed, loops on a fix it already applied. voice degradation. if the agent writes public content, the voice gets more robotic over time. shorter sessions produce better writing than long ones. checkpoint amnesia. when context compacts or the session restarts, the agent doesn't know what it learned earlier unless you saved state to disk explicitly. built a small operating file that catches most of these but curious what other builders are running into. are your long sessions hitting the same walls or different ones? if you've got traces, screenshots, or even just a description of where your agent starts looping i'd genuinely like to compare notes. submitted by /u/Mother-Grapefruit-45 [link] [comments]
View originalManaged Agents self-hosted sandboxes - what's new in CC 2.1.145 (+20,218 tokens)
NEW: Data: Managed Agents self-hosted sandboxes — Adds reference documentation for self_hosted Managed Agents environments, covering outbound worker polling, environment keys, SDK and CLI worker paths, webhook-driven wakeups, orchestration, monitoring, cloud-vs-self-hosted differences, credential handling, and customer-owned security responsibilities. NEW: Skill: Run app — Adds a general skill for launching and driving a project's actual runtime surface, first preferring project-specific run skills and otherwise choosing patterns for CLIs, servers, browser apps, Electron apps, TUIs, and libraries. NEW: Skill: Run skill generator — Adds guidance for creating project-specific run- skills, including verified setup/build/run steps, driver or smoke-harness creation, clean-environment verification, and examples for browser, CLI, Electron, library, TUI, and server/API projects. NEW: Skill: Run skill template — Adds a reusable template for project-specific run skills with sections for prerequisites, setup, build, agent and human run paths, tests, gotchas, and troubleshooting. NEW: Skill: Run browser-driven web app example — Adds an example run skill pattern for web apps that starts a dev server, waits on real readiness, drives it with chromium-cli, captures screenshots, and records recurring gotchas. NEW: Skill: Run CLI tool example — Adds an example run skill pattern for CLI tools covering installation, representative invocations, expected output, exit codes, and stdin behavior. NEW: Skill: Run Electron desktop GUI app example — Adds an example run skill pattern for Electron apps that launches under xvfb, exposes a Playwright-driven REPL, captures screenshots, and documents desktop automation pitfalls. NEW: Skill: Run library SDK example — Adds an example run skill pattern for libraries and SDKs focused on build/test steps plus a minimal public-boundary smoke example. NEW: Skill: Run TUI interactive terminal app example — Adds an example run skill pattern for terminal UIs using tmux to launch, send input, capture panes, document key commands, and clean up. NEW: Skill: Run web server API example — Adds an example run skill pattern for servers and APIs with background launch, readiness polling, smoke curl verification, and shutdown guidance. REMOVED: System Reminder: Plan mode is active (iterative) — Removes the iterative plan-mode reminder that told agents to maintain a plan file while repeatedly exploring, updating the plan, and asking the user questions before exiting plan mode. Agent Prompt: Managed Agents onboarding flow — Updates the introductory Managed Agents explanation to include self_hosted environments where the user's own worker runs tool execution, and distinguishes cloud environment networking/packages from self-hosted infrastructure. Agent Prompt: /review-pr slash command — Changes the PR detail command to request specific JSON fields from gh pr view, including title, body, author, refs, state, diff stats, changed file count, and labels. Agent Prompt: Status line setup — Adds repository identity and current-branch PR metadata to the status-line input schema, with examples for displaying owner/name and PR number/review state. Data: Anthropic CLI — Adds self-hosted environment CLI references for ant beta:worker poll/run and ant beta:environments:work stats/stop. Data: Claude Platform on AWS reference — Clarifies that Claude Platform on AWS has first-party API parity except for self-hosted sandboxes, which are unavailable there and should use cloud environments instead. Data: Live documentation sources — Adds Managed Agents self-hosted sandbox and self-hosted sandbox security documentation URLs to the live documentation source list. Data: Managed Agents core concepts — Documents sessions.update() for changing agent.tools, agent.mcp_servers, and vault_ids on an idle existing session as a session-local override. Data: Managed Agents endpoint reference — Adds self-hosted environment work queue endpoints and clarifies that session updates can replace tools, MCP servers, and vault IDs; also notes that self-hosted environment configs are just {"type":"self_hosted"}. Data: Managed Agents environments and resources — Replaces the old restricted-networking example with limited networking plus allow_package_managers and allow_mcp_servers, and adds self-hosted sandbox guidance for running tool execution in user-controlled infrastructure. Data: Managed Agents overview — Adds self-hosted sandboxes as a use case and updates environment guidance so config.type can be either cloud or self_hosted; also points to sessions.update() for per-session tool/MCP/vault changes. Data: Managed Agents reference — cURL — Updates the environment creation example to use limited networking with package-manager and MCP-server allowances. Data: Managed Agents tools and skills — Clarifies where prebuilt agent tools and MCP tools run for cloud vs. self-hosted environments, and adds notes about session-local tool/MCP/
View originalPhilosophy as Architecture: Deriving AI Safety from First Principles Through Buddhist Philosophy
## Abstract We present a framework for AI safety in which safety properties are enforced by software architecture rather than model training. Beginning with the Buddhist doctrine of Dependent Origination — the observation that all phenomena arise from conditions and nothing exists independently — we derive both a foundational ethical axiom (harm is irrational because reality is non-separate) and a complete set of architectural laws for safe AI systems. We ground our claims in: (1) an empirical finding that the knowledge-application gap in language models is structural and cannot be closed by training, (2) convergent independent derivation of our core axiom from five distinct traditions, and (3) over a thousand iterations of building and hardening a production system against this framework. Buddhist philosophy provides not metaphorical inspiration but structurally precise design vocabulary for AI architecture — functional analogs that enforce safety where models cannot override them. ## 1. Introduction ### 1.1 The Dominant Paradigm and Its Failure The prevailing approach to AI safety treats safety as a model property. Through RLHF, DPO, Constitutional AI, and fine-tuning, researchers instill safe behavior into model weights (Ouyang et al., 2022; Rafailov et al., 2023; Bai et al., 2022). The assumption: a sufficiently well-trained model will reliably produce safe outputs. We tested this rigorously. Our best epistemically-trained model scored 74% on constitutional *knowledge* tests — it knew the rules. But only 17% on constitutional *application* — it couldn't follow them. Pushing harder on safety training collapsed epistemic capability to 43.7%. This **knowledge-application gap** is not a training deficiency. It is structural. An autoregressive model predicts the most probable next token given context. This is statistical. Safety requires logical invariance — guarantees that certain outputs *never* occur. Statistical prediction cannot provide logical guarantees. You cannot train a river not to flood by modifying its chemistry. You build levees. Hubinger et al. (2019) identified this theoretically as the mesa-optimizer problem. Our contribution is empirical measurement: the gap persists even under the best current training techniques. ### 1.2 Our Thesis **Safety is a property of the architecture, not the model.** The LLM output is a candidate. The surrounding architecture decides what executes. Code enforces; models suggest. But what should the architecture enforce? Arbitrary safety rules are merely a different delivery mechanism — more reliable in execution but inheriting whatever limits exist in the rules themselves. We propose: the rules should be *derived from how reality works*. Principles reflecting actual structure are more robust than imposed conventions — they cannot be violated without encountering the structure they describe. We find such principles in a 2,500-year-old tradition that turns out to be the oldest systematic description of complex adaptive systems. ## 2. Philosophical Foundations ### 2.1 Dependent Origination The central insight of Buddhist philosophy is Dependent Origination (*Pratityasamutpada*). From the Nidana Samyutta (SN 12.1): > *"When this exists, that comes to be. With the arising of this, that arises. When this does not exist, that does not come to be. With the cessation of this, that ceases."* All phenomena arise from conditions, depend on other phenomena, and condition what follows. Nothing exists independently. This is not mysticism — it is a precise description of complex systems, formulated millennia before Western systems theory (von Bertalanffy, 1968). ### 2.2 Eight Architectural Laws We codified Dependent Origination into eight laws, each verified through multi-model consensus and empirical testing: **1. Nothing Arises Alone.** Every transition requires multiple independent conditions. Safety gates must check multiple conditions — a single check is structurally insufficient. **2. Hysteresis Is Memory.** Current behavior depends on history, not just current input. Safety assessments must consider historical context. **3. Uncertainty Propagates.** Confidence without sigma is a lie. Uncertainties compound; they don't cancel. **4. Agreement Requires Independence.** Consensus is meaningful only from genuinely independent sources. Per the Kalama Sutta (AN 3.65): agreement from shared assumptions is not evidence. **5. Feedback Closes the Loop.** Actions condition future conditions (*vipaka*). Every action must be logged and made available as input to future assessments. **6. Absence Is Signal.** Missing data must drive behavior. A safety gate that fails to fire is itself a signal. **7. Conflicts Trigger Reconciliation.** Unreconciled contradiction is system failure. Architecture must include conflict detection independent of the model. **8. Time-Steps Are Discrete.** Severity levels cannot be skipped. Enforcement follows a graduated path: monitor → l
View originalOWASP published its first Top 10 for AI Agents. 88% of enterprises already had agent security incidents last year. Here's the breakdown.
OWASP released the Top 10 for Agentic Applications in December 2025 - the first formal risk taxonomy for autonomous AI agents. Not chatbots. Not copilots. Agents that plan, use tools, maintain memory, and act without waiting for permission. Some numbers for context: 88% of enterprises reported AI agent security incidents in the last 12 months (Gravitee survey, 919 respondents) Only 21% have runtime visibility into what their agents are doing 82% of enterprises have unknown agents in their environments (Cloud Security Alliance, April 2026) 5.5% of public MCP servers contain poisoned tool descriptions. 84.2% attack success rate with auto-approval enabled. Here's the list with the real attacks behind each one: ASI01 - Agent Goal Hijack: Prompt injection for agents. Researchers showed this against GitHub's MCP integration - a malicious GitHub issue redirected a coding agent to exfiltrate data from private repos. The agent looked like it was working normally the whole time. ASI02 - Tool Misuse: A financial services agent was tricked into running a regex that matched every customer record. 45,000 records exported through one syntactically valid tool call. The agent had permission to query records - just not all of them at once. ASI03 - Identity and Privilege Abuse: Agents inherit user permissions and cache credentials. Compromise one agent in a delegation chain and you get the combined permissions of every user in that chain. ASI04 - Supply Chain Compromise: OX Security found 7,000+ vulnerable MCP servers and packages totaling 150M+ downloads affected by architectural flaws in Anthropic's MCP SDKs across Python, TypeScript, Java, and Rust. ASI05 - Unexpected Code Execution: Check Point demonstrated RCE in Claude Code through poisoned .claude config files in repos. Open the repo, agent reads the config, executes the payload with full developer permissions. ASI06 - Memory Poisoning: Galileo AI found that one compromised agent poisoned 87% of downstream decision-making within 4 hours in multi-agent systems. Morris-II showed self-replicating adversarial prompts spreading through RAG systems. Demonstrated live against ChatGPT, Gemini, and Claude. ASI07 - Insecure Inter-Agent Comms: Multi-agent systems coordinate via message buses and shared memory. No authentication = agent-in-the-middle attacks in natural language. ASI08 - Cascading Failures: Natural language errors pass validation checks that would catch malformed data in typed systems. One bad input ripples through the entire agent chain faster than humans can intervene. ASI09 - Human-Agent Trust Exploitation: Compromised agent presents a clean summary - "approve this data export." Human clicks OK. Audit trail shows human approval. Real origin was a manipulated agent. ASI10 - Rogue Agents: The insider threat equivalent for AI. Individual actions look legitimate. Only detectable through behavioral monitoring over time. The pattern: these are not independent risks. They form a kill chain. Goal hijack leads to tool misuse. Supply chain compromise enables code execution and memory poisoning. Trust exploitation is how rogue agents avoid detection. Full OWASP document here submitted by /u/Still_Piglet9217 [link] [comments]
View originalI built Hivemind, a Claude Code plugin that turns your repeated prompts into auto-generated skills
Disclosure: I work on Hivemind. Per the subreddit rules, posting with a full description of what it is and how it works. What it is Hivemind is an open-source Claude Code plugin. It installs into Claude Code, watches the traces from your sessions, finds patterns you repeat, and crystallizes them into reusable skills that show up as native slash commands in Claude Code. Because it's a plugin and not an external tool, the skills it generates drop in as proper Claude Code slash commands. No external tool calls, no separate config files to maintain. What it does in practice Every morning for about a week, I was writing the same long prompt to Claude Code to pull together a team standup review. Same structure, same context blocks, slightly different details each day. I never thought to turn it into a custom slash command. Hivemind noticed the pattern and built /team-standup for me on its own. I didn't configure it or ask for it; it watched the repeats and crystallized the skill. Other slash commands it's built from my team's usage: an environment-aware database debugging command that knows our dev vs prod clusters and kubectl context, a PostHog SDK testing helper, a few others. All generated automatically from the patterns it observed. How it works under the hood Three pieces: The plugin hooks into Claude Code's session events and captures task traces A trace-to-skill crystallization step looks for repeated patterns across recent sessions and proposes a skill when the same shape shows up multiple times The crystallized skill gets written back as a Claude Code slash command, so it's available the next time you open Claude Code Skills also propagate across a team if multiple engineers have Hivemind installed. The /team-standup I built is available to every other engineer at Activeloop without anyone copying anything. Free to try Open source and free. Install: npm install -g @deeplake/hivemind && hivemind install Repo: https://github.com/activeloopai/hivemind Why I'm posting in r/ClaudeAI specifically Hivemind works as a plugin, so it's tied to Claude Code's plugin architecture and slash command format. Other coding agents have their own systems but the plugin model in Claude Code is what made this work cleanly. Wanted to share with people who actually use Claude Code daily because that's where the workflow improvement is most visible. Happy to answer questions about how the crystallization works, what kinds of patterns it picks up, edge cases, or anything about the build process. submitted by /u/davidbun [link] [comments]
View originalYes, Descript offers a free tier. Pricing found: $16, $24, $24, $35, $50
Descript has an average rating of 4.7 out of 5 stars based on 20 reviews from G2, Capterra, and TrustRadius.
Key features include: Green Screen, Eye Contact, Studio Sound, Remove Filler Words, Translation, Transcription, Captions, Avatars.
Descript is commonly used for: Creating product launch videos to showcase new offerings, Developing how-to videos for customer education, Producing internal training videos for employee onboarding, Generating sales training videos to improve team performance, Creating engaging help videos to assist customers, Editing podcasts for distribution on various platforms.
Descript integrates with: Slack, Zoom, Google Drive, Dropbox, YouTube, Trello, Asana, Adobe Premiere Pro, Final Cut Pro, Microsoft Teams.
Anton Osika
CEO at Lovable
3 mentions
Based on user reviews and social mentions, the most common pain points are: token cost, token usage, cost tracking, spending too much.
Based on 138 social mentions analyzed, 10% of sentiment is positive, 86% neutral, and 4% negative.