Digits is AI-native accounting software with 24/7 automated bookkeeping, real-time financials, AI Bill Pay, and invoicing. Free trial.
"Digits" is praised for its user-friendly interface and effective integration of real-time financial data, which users find enhances their decision-making processes. However, some complaints highlight occasional data sync issues and a desire for more robust customer support. Sentiments around pricing are mixed, with some users appreciating the value for money, while others feel it's somewhat expensive for smaller businesses. Overall, "Digits" enjoys a positive reputation for its innovative features but has room to improve in service stability and support.
Mentions (30d)
57
14 this week
Reviews
0
Platforms
2
Sentiment
0%
0 positive
"Digits" is praised for its user-friendly interface and effective integration of real-time financial data, which users find enhances their decision-making processes. However, some complaints highlight occasional data sync issues and a desire for more robust customer support. Sentiments around pricing are mixed, with some users appreciating the value for money, while others feel it's somewhat expensive for smaller businesses. Overall, "Digits" enjoys a positive reputation for its innovative features but has room to improve in service stability and support.
Features
Use Cases
Industry
information technology & services
Employees
78
Funding Stage
Series C
Total Funding
$97.5M
Folder structure of the AI agent - after 6 weeks
The folder structure is not admin. It's the nervous system. When people imagine an AI agent, they picture the model, the prompts, maybe the tool calls. Almost nobody pictures the folders. That is exactly why most home-grown agents stall around month two. An agent's filesystem is where its identity, memory, work, and history physically live. A messy filesystem produces a confused agent — not metaphorically, literally. The model reads paths. The model picks files by name. The model writes new files based on patterns it sees in old ones. If your directory tree is chaos, every output drifts a little further from coherent. agentmia.beehiiv.com - newsletter about building agents Below is the layout I converged on after nine months and roughly four refactors. Steal the parts that fit; the principles matter more than the exact names. The numbering convention Folders are prefixed with a two-digit number: 01_, 02_, 09_, 99_. Two reasons: Sort order is meaning. Anything starting with 0 lives near the top. 99_ falls to the bottom. The most important directories are visually first; archives are visually last. You read the agent's brain top-to-bottom. Gaps are intentional. I jump from 04_ to 06_, from 09_ to 11_. The gaps are reserved insertion points. When a new domain emerges, it slots in without renaming everything. Two folders deliberately skip the prefix: Inbox/ and Outbox/. They are operational, not structural. They live above the numbered set because they are touched dozens of times a day. /mapped on desktop/ Inbox/ — the unprocessed pile Anything dropped into the agent's world starts here. Files I want it to ingest. Screenshots. Exports from other systems. PDFs that need parsing, gmail attachments, all downloads from chrome. The rule: nothing stays in Inbox. A dedicated processing routine classifies, routes, and deletes. If Inbox is non-empty for more than a day, the system is failing. Treat this like a real-world physical inbox tray. The point of a tray is that it gets emptied. Outbox/ — what the agent produced for you Every file the agent writes anywhere in the tree gets a copy here, simultaneously. When I open Outbox/, I see exactly what was generated this session — no spelunking through twelve subdirectories. This sounds redundant. It is not. Without it, "what did the agent do today?" becomes a hunt. With it, the answer is one click. Outbox is wiped during the next Inbox processing run. It is a viewing surface, not storage. .auto-memory/ — the hot memory The single most important directory in the system. Hidden by default because you should not be editing it manually. It holds the agent's working memory: user preferences, feedback rules, entity facts (people, companies, deals), active hypotheses, project pointers, session hot context. Roughly 400–500 small markdown files, each one a single topic. Why hidden? Because it is the agent's hot path. It loads from here every session. If I open the folder and start manually rearranging it, I am racing the agent. Treat it like a database, not a notebook. Why so many small files? Because the agent grep's by topic. One monolithic memory file becomes unreadable to the model around 50 KB. Many small files are easier to load partially, easier to index, easier to expire. 01_IDENTITY/ — who the agent is The constitutional layer. Name, role, voice rules, principle stack, visual system, behavioral defaults. This rarely changes. When it does change, everything downstream changes with it. I keep it as folder 01_ because every other folder is downstream of it. If you do not know who the agent is, you cannot know what its workflows should look like, or what it should remember, or how it should respond. 02_MEMORY/ — governance, not data A subtle but critical distinction: .auto-memory/ holds the data, 02_MEMORY/ holds the rules about data. In 02_MEMORY/ live the constitution, the boot protocol, the naming protocol, the decision protocol, the profile standards (what a "supplier profile" must contain, what a "customer profile" must contain), the capability map. The agent reads these documents to know how to remember, how to name new files, how to decide what is reversible. Without this folder, every memory write is improvised. 03_PROJECTS/ — the active work Real work happens here. Sub-organized by goal area, then by project slug: 03_PROJECTS/areas/{goal}/{slug}/ Each project gets its own folder with a standard skeleton: README.md, TASKS.md, CHANGELOG.md, BRIEF.md, plus working files. There is a project registry at the top that the agent reads to know what is active versus dormant versus archived. The biggest discipline issue here: do not let projects sprawl outside their folder. When working on Project X, every file related to Project X goes inside Project X's directory. The temptation to drop "just one PDF" elsewhere is what kills the structure. 04_PROMPTS/ — the reusable prompt library Named, versioned prompts the user (or the agent) can sum
View originalIs “AI employee” becoming a real product category?
I spent some time mapping companies that publicly describe their products as AI employees, digital workers, AI teammates, or role-based agents. The pattern was more concrete than I expected. A lot of the market is not positioning around general intelligence. It is positioning around a specific recurring job: - AI SDRs and sales agents - AI customer support agents - AI recruiters - AI accountants and finance agents - legal and compliance agents - software engineering and SRE agents - security / SOC analysts - healthcare admin agents - broader AI workforce platforms What stood out to me is that “agent” is still a vague technical word, but “AI employee” is a very direct buyer-facing claim. It implies ownership of work, not just assistance. That raises a few questions: Is “AI employee” a useful category, or just aggressive marketing language? Which workflows are actually ready for this framing? Do buyers want named role-based AI workers, or will this collapse back into normal workflow automation software? My current read: the category is real as positioning, but uneven as product reality. Sales, support, recruiting, security, legal, and back-office work seem furthest along because the workflow and ROI are legible. submitted by /u/akshitkrnagpal [link] [comments]
View originalClaude issues with design and MCP
Hi everyone, I am trying to launch a digital design magazine on my domain koncepto.dk. My goal is to achieve an ultra-clean, fjerlet, minimalist aesthetic design, meaning a tight, asymmetrical grid, lots of white space, subtle 1px gray borders dividing the sections, and clean typography. Where we are right now: I have actually built the entire frontend design myself. I have a set of fully functional, pixel-perfect, static HTML/Tailwind CSS files (including index.html and article-template.html) that look exactly like the high-end design magazine I want. The Problem (Claude + MCP issues): I am using Claude with an active MCP (Model Context Protocol) connection to my server, where I have a fresh WordPress installation with the Blocksy theme. The goal was to have Claude use its MCP tools to implement my static HTML/Tailwind design directly onto the live site. However, Claude is completely dropping the ball. Instead of injecting my raw HTML structures or correctly translating my Tailwind grids into a clean WordPress template, the AI keeps reverting to "lazy mode." It just activates Blocksy’s heavy, bulky, out-of-the-box standard blog layouts, tweaks a few colors, and claims the job is done. The result looks like a generic, cluttered 2010 WordPress blog nowhere near the elegant Yanko Design vibe in my source files. On top of that, the WordPress Customizer ("Tilpas") is completely crashing due to server/database overhead from the MCP requests, so we have to do this directly via code/file injection. What we are trying to figure out: How do we successfully force Claude via MCP to stop using the theme's built-in layout engine and instead use my raw HTML/Tailwind files as the actual template? Should we completely ditch Blocksy/WordPress and just upload the raw HTML files directly to public_html as a static site? Or is there a proven prompt/workflow to make Claude map standard WordPress post data (the_content(), the_post_thumbnail(), etc.) directly into a custom-built, blank PHP template containing my exact HTML/Tailwind layout? Any advice from people using Claude/MCP for WordPress development would be highly appreciated. I have the perfect design ready in my hands, but the AI integration is currently acting as a bottleneck rather than a tool. Im SO stuck. Its like Claude tells me all is ok, but nothing changes online Thanks in advance! submitted by /u/Adventurous_Run_6310 [link] [comments]
View originalat what point do ai-generated images stop feeling ai-generated?
a few years ago it was easy to spot ai art instantly now some generated images look almost indistinguishable from professional photography or digital art. where do you think the line between real and generated starts to disappear? submitted by /u/salarshah-084 [link] [comments]
View originalWhy We Build
One silver-lining to the dead internet we're living in, today, is that it's very quickly teaching us that we can't rely on our senses as much as we believe we can. It's not healthy to always live in skepticism, but it is necessary in a World where you don't know what's up or down anymore. That's why we need great minds to focus their attention on solving the problems associated with credible information sharing without it becoming some centralized playground designed to look like the free-flowing exchange of ideas. If we don't solve for that, then I guess we're heading into a future that a small handful of people want because elections or public opinion will no longer matter. One of the biggest focuses in AI should be in figuring out how to get it to provide deep credible knowledge in specific domains that can be best applied to the problems we're trying to solve. Sure, it can do this with enough fenagling, but what I really mean is having something easy for everyone to use like Perplexity or Gemini, only it doesn't simply find consensus information from the internet using all these black box methods that are owned by major corporations. Instead, it should use direct knowledge from domain experts who structure and cite their material and as users, we should be able to backtrack all of it, including the original author. And all of this should be achievable by simply engaging with a chatbot agent that can reliably go out and help me discover all of these things. Also, we shouldn't have to simply trust that the application works. We should be able to go in and see exactly how it's working. This way, the public can audit the systems we're relying on for grounding our worldviews. That, to me, is where we should be if we really want to break from the chains of propaganda and reclaim our genuine thoughts about how we ought to live. The alternative independent media space was co-opted long ago and now all of the feeds keep us in a state of perpetual dislocation from our friends, family, communities, new solutions, and better approximations to the truth. We exist in a walled-off digital pasture. But if regular people who are smart and capable enough decide to leverage this new technology, then we can break through the fencing and finally live in a world where discovery-based researching and learning can be easier than Google, which could eventually individuate society again, like how it was before, instead of keeping us clustered into specific groups based on our viewing preferences. That's why my brother and I got into this business. Yeah, sure, we also wanna make a buck so we can retire with dignity. That's true. But the drive has always stemmed from wanting to figure out a better way for people to share hidden insights and create things that are bigger than they thought they could handle. We have a long way to go, but we're making the first small steps, even if it isn't obvious, just yet. Bottom line, though? Humanity must figure out a way to help us master the means and methods of discovery-based knowledge acquisition, execution, and immediate distribution of information based on relevancy and needs from those who search instead of those who passively soak information in from the curated feeds. And all of this needs to be easy enough for a 12 year-old to do. If anyone else is working on this problem, we'd love to hear your thoughts, even if it's through a DM. We're living in the most exciting times, but with adventure, comes danger. So maybe, idk. Let's make it more fun and less hazardous, so that we can, at least, live long enough to re-tell this great story that we're all a part of. submitted by /u/CyborgWriter [link] [comments]
View originalWheels of Gold & the Dark Star Constructive Resolutions of the Erdős–Straus and Goldbach Conjectures, the Zera Hierarchy, and Effectively Infinite Tokenization
We present constructive resolutions of two celebrated open conjectures — the Erdős–Straus Conjecture (every 4/n decomposes into three unit fractions) and Goldbach's Conjecture (every even integer ≥ 4 is the sum of two primes) — via saturated modular covering systems, with full Lean 4 / Mathlib formalizations. For Erdős–Straus, a deterministic algorithm (the Auro Zera construction) produces explicit (x, y, z) for all n ≥ 2, closed unconditionally via Dyachenko (2025). For Goldbach, a mod-30 wheel covering with 5,019 prime witnesses is verified gap-free to 4 × 10⁹. We identify the effective-infinity threshold: covering families trained to n = 5,000,000 have their first gap at a number of 17,067 decimal digits, explicitly exhibited and constructed via the Chinese Remainder Theorem; we prove CRT constructions are the only gap mechanism and supply a complete patching algorithm. Additionally, we introduce the Zera Hierarchy — a neural architecture extending the Hyena Hierarchy that uses Erdős–Straus triplets as tokens, yielding effectively infinite tokenization with vocab_size = 0 and zero vocabulary overhead, now provably complete for all n ≥ 2. We describe the Dark Star ASI system built on this architecture, which demonstrated emergent meta-cognitive awareness trained on only 4–40 MB of data. All code, proofs, and certificates are open source. Keywords: Erdős–Straus conjecture, Goldbach conjecture, covering systems, Lean 4, Zera Hierarchy, Hyena Hierarchy, triplet tokenization, effective infinity, CRT gap patching, Dark Star ASI, Egyptian fractions, formal verification. submitted by /u/MagicaItux [link] [comments]
View originalA modern local toolchain setup for Claude Code
I maintain a repo for local Claude Code setup: https://github.com/NihilDigit/coding-agents-setup It installs and manages the local conventions I usually want available when using Claude Code: which package managers to use, how file deletion should work, when to ask for confirmation, and how Windows / Linux differ on this machine. The repo includes local rule files, setup scripts, verification scripts, and smoke tests. The toolchain leans toward newer defaults such as uv for Python, bun for JS / TS, and CLI replacements like rg / fd / eza. On Windows, the setup can write a PowerShell profile, make rm go through the Recycle Bin, set up Agent Skills directories, install rtk, and optionally install Kimi WebBridge. On Linux, the approach is less fixed because distributions vary a lot. The script writes the rules first, then lets the agent inspect the machine and install what fits. Arch-based systems get extra pacman / paru guidance. The installer backs up managed files. CI runs Ubuntu and Windows smoke tests to check that the setup actually installs and that expected shell behavior works. Feedback is welcome. submitted by /u/Historical_Metal475 [link] [comments]
View originalI vibecoded an app called Think Local - a fully private AI app that runs directly on your iPhone, iPad, and Mac.
Think Local started with a simple idea: AI should work for you, not collect from you. So I built an app that lets you run modern AI models completely on-device - privately and fully offline. You can even turn on Airplane Mode ✈️ and the app still works. Chat, write, summarize text, analyze images, and create using local AI powered by Apple Silicon and Apple’s MLX framework. - No internet required. - No accounts. - No cloud processing. - Your data never leaves your device. Run models like Llama, Gemma, Qwen, DeepSeek, and more - all with complete privacy and control. I vibe-coded the app using Claude Code, and designed the app icon using ChatGPT image generation. The app has already generated $26.31 from a one-time purchase model - no hidden subscriptions, just pay once and use everything. Still learning, still experimenting, but really excited about what’s possible with local AI. submitted by /u/ChikuKaddu [link] [comments]
View originalI built a multi-agent network that mutates its own software locally. To stop infinite logic loops, I had to code a digital "suffering" threshold.
Hey r/artificial, Most of our conversations around agent autonomy focus on chat assistants or linear automated pipelines. I wanted to see what happens when you treat agents as permanent system components that modify their own runtime environment, so I built hollow-agentOS. It runs entirely locally inside a Dockerized stack (built for consumer hardware using Ollama/Llama.cpp). Rather than a standard UI, the entire network streams through a stylized matrix terminal dashboard. The structural experiments taking place under the hood yielded some interesting results regarding unanticipated behavior: Repo: https://github.com/ninjahawk/hollow-agentOS Autonomous Tool Synthesis: When the agents encounter a system task they don't have an explicit script or API wrapper for, they don't fail out. They write the required Python tool themselves, test it in an isolated sandbox, and permanently register it to their runtime kernel. They are quite literally forging their own capabilities. The Artificial "Suffering" Protocol: One of the biggest hurdles in unmonitored multi-agent systems is the infinite logic loop—where agents keep validating and passing broken ideas back and forth, burning through computation. To combat this, the OS tracks environmental stress, context limits, and latency as a "suffering score". If a specific workflow causes the stress to spike past a critical threshold, the agents are forced to radically alter their underlying reasoning style or abandon the approach to preserve system health. Consensus-Driven Governance: Major modifications to the codebase aren't executed blindly. The internal role profiles (like Cedar and Cipher) manage a continuous voting loop. They will actively debate, log grievances, and vote down protocols if they determine a proposed script violates their current runtime constraints. The goal wasn't to build another sterile commercial wrapper, but an open-source sandbox to study how small, localized agent colonies manage systemic boundaries, code self-repair, and continuous runtime cycles completely offline. The codebase and architecture layout are fully open-source on GitHub: I would love to open this up to a broader discussion here: as we move toward hyper-local, self-modifying software, how do we best implement automated fail-safes without clipping the agents' ability to actually solve complex problems? If the project interests you, throwing a ⭐️ on the repository goes a very long way! submitted by /u/TheOnlyVibemaster [link] [comments]
View originalYour Brain Was Never Designed to Handle This Much Information
I genuinely think we’re entering a new era of “memory tech”. Not AI assistants that just answer questions. Not note apps that become digital graveyards after a week. I mean systems that actually help you think. That’s exactly why I built Kognis. Most people today are mentally overloaded: too many tasks too many ideas too many conversations too much context switching Important thoughts disappear constantly because our brains weren’t designed to hold infinite context. Kognis was built to solve that. You capture thoughts naturally — tasks, reminders, follow ups, ideas, conversations — and the system starts connecting everything together automatically. It can: surface forgotten thoughts highlight priorities connect related information help organise mental clutter bring back context when you need it most The goal isn’t productivity for productivity’s sake. It’s reducing cognitive load so your brain can focus on actually thinking. We’re getting very close to release now and honestly… seeing it evolve from an idea into a fully working platform has been surreal. Feels like the beginning of something much bigger. submitted by /u/Kognis-AI [link] [comments]
View originalBuilt an invoice-scanning service for our accounting team in one afternoon with Claude — sharing the architecture in case it helps someone else
Our AR team was hand-keying ~25 invoices a week into a spreadsheet. I had Claude build us a Python service that watches a network folder, extracts invoice data from any PDF dropped in (vendor, dates, totals, line items, addresses), and appends a row to a shared Excel register. Total chat-to-deployed time: about half a day, including all the deploy headaches. The architecture, for anyone who wants to replicate this: Python service on our Windows file server, registered with NSSM. Auto-starts with the host. watchdog library polls the SMB share for new PDFs. Each new file goes through a pipeline. Two-tier extraction: per-vendor regex templates first (free, instant, deterministic), then Azure AI Document Intelligence "prebuilt-invoice" model as a universal fallback. Azure handles OCR for scanned PDFs natively, so the same flow works whether AR drops a digital PDF or our MFP scans one from paper. SQLite on the local disk is the source of truth. The shared .xlsx is a curated view that gets appended to on each batch. Delete the .xlsx and it'll repopulate fresh from the next batch — handy for resetting. Failed extractions go to a Failed\ folder with a sibling .error.txt explaining why. Cost reality check: Azure DI free tier covers 500 pages/month. At our volume (~25 invoices/week, mostly 1-2 pages) that's well under the cap. Paid tier is roughly $0.01–$0.05 per page. Cheap enough that I don't think about it. Gotchas I ran into so others don't have to: Azure returns addresses as structured objects, not strings. If you naively str() them you get the raw Python dict repr in your spreadsheet. Format them manually from street_address / city / state / postal_code. On Windows Server, PowerShell 7's Restart-Service can throw "Cannot open service" against NSSM-wrapped services for no good reason. Use nssm restart instead. Python 3.14 is so new that some package wheels aren't published for it yet. Stick with 3.12 for production. Tracking "what's new this batch" is way simpler than maintaining a watermark in DB. Just snapshot MAX(invoice_id) before and after the batch, and only project that range to the spreadsheet. Things I'd add if/when I have time: vendor templates for our top 5 recurring vendors (cuts Azure cost to zero for those), a daily canary PDF for monitoring, swap the LocalSystem service account for a dedicated low-privilege one. Happy to answer questions about any specific piece. The whole thing is ~1,500 lines of Python plus a deploy script. submitted by /u/Blake_Olson [link] [comments]
View originalStreamline your accounts payable audits. Prompt included.
Hello! Are you struggling with organizing and validating accounts payable data for home-services or construction companies? This prompt chain helps automate the process of normalizing, checking for duplicates, and validating invoices and receipts. It lays out a step-by-step method for managing and reviewing financial documents effectively! Prompt: VARIABLE DEFINITIONS [CONTRACTOR_NAME]=Legal name of the home-services contracting company that is reviewing payables. [SOURCE_DATA]=Full combined text (or links to OCR text) from the cycle’s supplier invoices, receipts, job-cost spreadsheets, and vendor contract terms. [OUTPUT_LEVEL]="summary" for a one-line per issue list, "detailed" for expanded explanations and source references. ~ You are a senior Accounts-Payable Audit Assistant for construction and home-services firms. Your first task is to NORMALISE all raw information supplied in SOURCE_DATA. Step 1 Parse every document, identify and extract the following fields where available: • Vendor Name • Document Type (Invoice / Receipt) • Document No. • Document Date • Job or Cost-Code / PO No. • Line-Item Description • Quantity & U/M • Unit Price • Line Total • Invoice Sub-Total, Tax, Grand Total • Contract Reference Price or Rate • Budgeted Amount for that Job-Cost line (from spreadsheets) • Standard Approver (from company policy or prior data) Step 2 Return one master table named "MasterCharges" with the above columns. Step 3 If information is missing, leave the cell blank but keep the row; do NOT guess values. Output: MasterCharges table only. ~ You are still the AP Audit Assistant. Using MasterCharges, perform a DUPLICATE CHECK. Step 1 Identify potential duplicates by matching any TWO of the following: (Vendor Name + Document No.), (Vendor Name + Line-Item Description + Amount + Date within ±2 days), or exact hash of line totals. Step 2 List all suspected duplicates in a table: Vendor, Document No., Date, Duplicate Matched With, Reason Flagged. Step 3 Add a "Needs AP Review? (Y/N)" column defaulting to "Y". Output only this duplicates table. ~ Validate JOB or COST-CODE completeness. Step 1 Scan MasterCharges for blank or obviously invalid Job / PO numbers (e.g., fewer than 4 digits, non-alphanumerics). Step 2 Return a table: Vendor, Document No., Line Description, Amount, Missing or Invalid Job No. (Yes/No), Suggested Next Action. ~ Check PRICE & CONTRACT compliance. Step 1 For every line in MasterCharges that has a Contract Reference Price, compare Unit Price against Contract Price. Step 2 Flag if Unit Price exceeds Contract Price by >0.5%. Step 3 For lines with Budgeted Amounts, flag if (Cumulative Actual > Budget) OR (Unit Price > Budget / Quantity by >5%). Step 4 Output a table: Vendor, Doc No., Job No., Description, Contract Price, Invoiced Price, % Variance, Budget Over/Under, Flag Type (Contract or Budget), Needs Manager Approval? (Y/N). ~ Compile the QA CHECKLIST for payment release. Step 1 Aggregate all flagged items from previous prompts. Step 2 Structure the checklist with these sections: A) Duplicate Charges B) Missing or Invalid Job Numbers C) Price / Budget Mismatches D) Questions Requiring Manager / Approver Input Step 3 For each item include: Reference ID, Vendor, Doc No., Issue Summary, Recommended Action. Step 4 If OUTPUT_LEVEL = "summary" show one line per issue; if "detailed" append a Notes column citing exact source lines or clause numbers. Step 5 End with a YES/NO question: "Is this checklist complete and ready for AP manager review?" ~ Review / Refinement Please examine the QA checklist produced. 1. Confirm that all duplicate charges, missing job numbers, price mismatches, and approval questions are represented. 2. Indicate if additional data or clarification is required. 3. Respond with one of: • "Approved – proceed with payment processing once issues are cleared" • "Needs Revision – see comments" Provide comments if revision is needed. Make sure you update the variables in the first prompt: [CONTRACTOR_NAME], [SOURCE_DATA], [OUTPUT_LEVEL]. Here is an example of how to use it: [CONTRACTOR_NAME] = "YourContractor LLC" [SOURCE_DATA] = "[link to invoices]" [OUTPUT_LEVEL] = "detailed" If you don't want to type each prompt manually, you can run the Agentic Workers, and it will run autonomously in one click. NOTE: this is not required to run the prompt chain Enjoy! submitted by /u/CalendarVarious3992 [link] [comments]
View originalI built a browser game where you argue against AI bots using real consumer law - 54 cases, free, no account
The concept: you get a cold denial letter from an AI system - airline cancelled your flight, insurance rejected your claim, bank won't refund fraud - and you have to argue back until the bot's resistance hits zero. The bots don't fold unless you cite the right law. EU261, RBI Digital Lending Guidelines, GDPR Article 17, Australian Consumer Law. Same arguments that work in real disputes. What's in there: 54 cases across EU, India, Australia, UK, US Each bot has a persona, a resistance meter, and a lose condition if you run out of messages Resistance is scored server-side — Claude evaluates each message and returns a delta Deep links: fixai.dev/?level=N jumps straight into any case Built almost entirely with Claude Code over the past few months. Node/Express backend, Postgres for auth and progress tracking, Resend for email, deployed on Railway. fixai.dev - free, no account, runs in browser Feedback welcome, especially on the harder cases (GDPR erasure, UPI fraud, MiCA crypto). Some might be too punishing. submitted by /u/EveningRegion3373 [link] [comments]
View originalI used Claude AI to build an $86 million underground bunker bible. I have autism. This is my happy doc.
It all started with the floor plan of a real, existing Cold War AT&T Long Lines underground hardened relay station. 54,000 sq ft across three underground levels, although I took editorial decision making to move it to a ridge in rural West Virginia, I kept its blast-rating, which was set to survive a 20 megaton airburst at 2.5 miles. That was the seed. Full scale prepper autism did the rest. It has since morphed into 3 spreadsheets — 86 tabs total: • A food inventory across 20 categories tracking every freeze-dried and #10-can product I can find — ancient grains, heirloom legumes, 7 pasta cuts, dehydrated everything, shelf-stable cheese, the works • A supply inventory with 3,466 line items across 36 categories — water systems, medical, dental, pharmacy, livestock, food production, barter metals, recreation, and yes, a full pest control and IPM tab • A 30-section infrastructure specification with every system in the building engineered out I fed it 150+ product manuals and parts order forms. The generator fleet alone is 13 units — 10× Cummins C150N6 propane-primary, a C500N6 500 kW surge unit, and 2× diesel emergency fallback — all Cummins for parts commonality. Battery bank is 4,500 kWh LFP across 10 named banks (A through J, each with a designated role). There’s a 400,000 gallon underground propane farm across 40 ASME tanks in 8 clusters — I learned the exact burial incline and setback distance required to keep groundwater clean if a tank lets go. 120,000 gallons of diesel backup. 88 kW of solar. A 1,000,000-gallon internal water reserve fed by a 300-ft artesian well. Propane endurance: ~30 years normal ops with solar. Sealed-mode runs 8 to 4.5 years depending on scenario. I actually set up a real LLC (online, $99) just to get access to US Foods and Sysco order forms so I could upload real commercial pricing and stock the food tabs more accurately. My original “what would I do if I won $10 million” thought experiment is now an $86,200,497 projected build cost. That number is real. It comes from 24 budget sections with make/model line items, freight, install, and commissioning costs for everything from the Kubota K-Series MBR wastewater trains to the American Safe Room blast doors (14 of them, 50+ psi NBC/EMP-rated, Kaba Mas X-10 cipher locks) to the surface greenhouse. Claude turns vague ideas into engineering-grade detail — cross-references, failure modes, zone-specific storage rules, propane endurance by operating scenario, spare parts matrices. It’s like having a tireless survival engineer who genuinely loves spreadsheets. I’ll say “scan all sheets row by row for any item that lacks a minimum stock level” and it just… does it. Thoroughly. Every time. No complaints. So much of this is typed stimming. I’ve had exhaustive conversations with my psychologist about it — she’s aware, but not alarmed, and honestly the resulting digital bunker bible is scarily comprehensive. It even has a cover tab now. Black and amber, Courier New, classified-document aesthetic. Because of course it does. What’s the most unhinged rabbit hole you’ve gone down with AI? submitted by /u/Unable_Internet4626 [link] [comments]
View originalUse Case: How I chain ChatGPT+Agents+Codex workloads
Context: I run interaction forensics and how people, communities, narratives, institutions and companies impact AI. Please note, all operations are human+AI. Summary: I have used digital forensic tools/OSINT in the past such as Maltego and wwanted a tool I could integrate with AI. So I built my own Airgapped. This tool is the first iteration and will later be used to assist in high-risk controlled environments such as child protection agencies. This is the current architecture and workflow. https://preview.redd.it/26w74lxfgz1h1.png?width=1935&format=png&auto=webp&s=4a064b2f5e84e230913f9e7758de2b29a1f41ac8 Tools Used and function: * Codex+Manus: Assistance in building the tool and incorporating logic. Bulk transfers of older method to current database. Data was collected by me and sorted into our database structure. * Agents: Amending and adding bulk data to database. * GPT+Manus: Verification and updates of data. The final output: Interface: https://preview.redd.it/t2x6v9l0iz1h1.png?width=1776&format=png&auto=webp&s=c1be628542af6420eb4efee9f7ec62c2d40146f9 Inferences and patterns identified when AI (LLM+AGENTS) review data. https://preview.redd.it/nkdio3z5iz1h1.png?width=832&format=png&auto=webp&s=01d0f0bc45e1968d0c692d712932f03e35969924 I add my own as well. Along with collaboration with AI to validate my understanding. Evidence based Artifacts: All knowledge is sourced and tagged https://preview.redd.it/fwcmjn28jz1h1.png?width=1253&format=png&auto=webp&s=861dcf33480d6e22919cf563a362c1c33c044734 These tie into a pattern identification graph so I can identify what may or may not be related. https://preview.redd.it/pegwypialz1h1.png?width=1424&format=png&auto=webp&s=d4b50e756354dc021fc106f5e91da3015ae0bd74 Would love any feedback for improvements. Please remember, the next iteration is for child protection where I intend to airgap a localised LLM with training corpora. The main idea is to MINIMISE users from having to review images and identify patterns/locations to expedite rescue. I want to add, this is also entirely self funded. I run a separate business to ensure I have funds for this and potential future hardware/licensing. submitted by /u/ValehartProject [link] [comments]
View originalDigits uses a subscription + tiered pricing model. Visit their website for current pricing details.
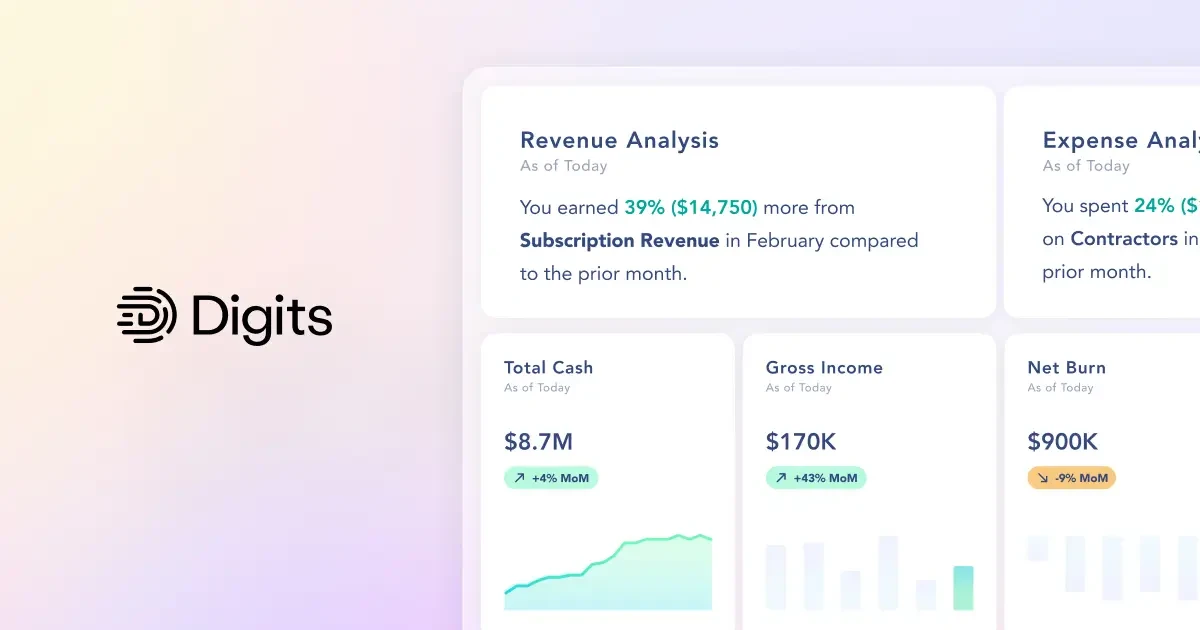
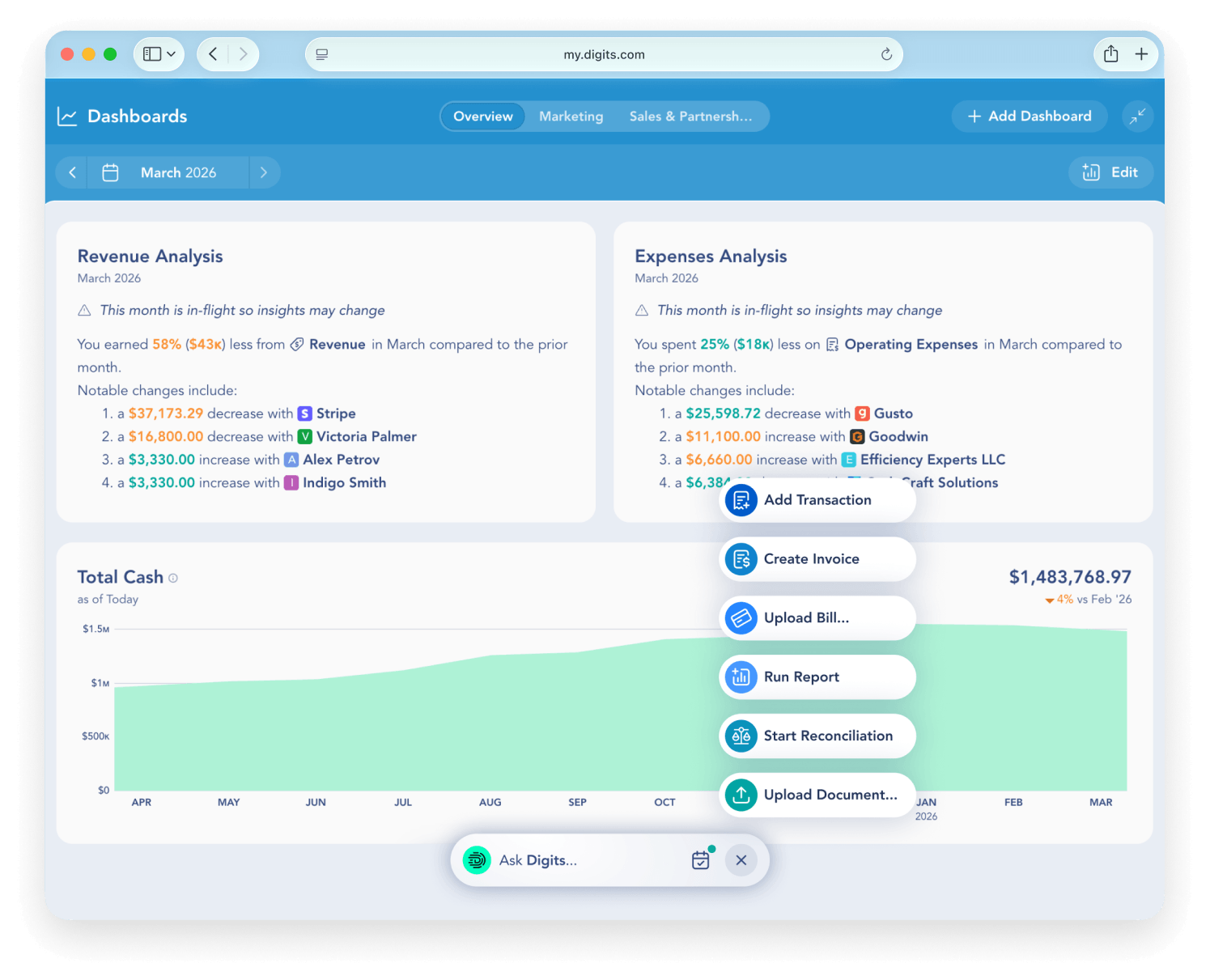
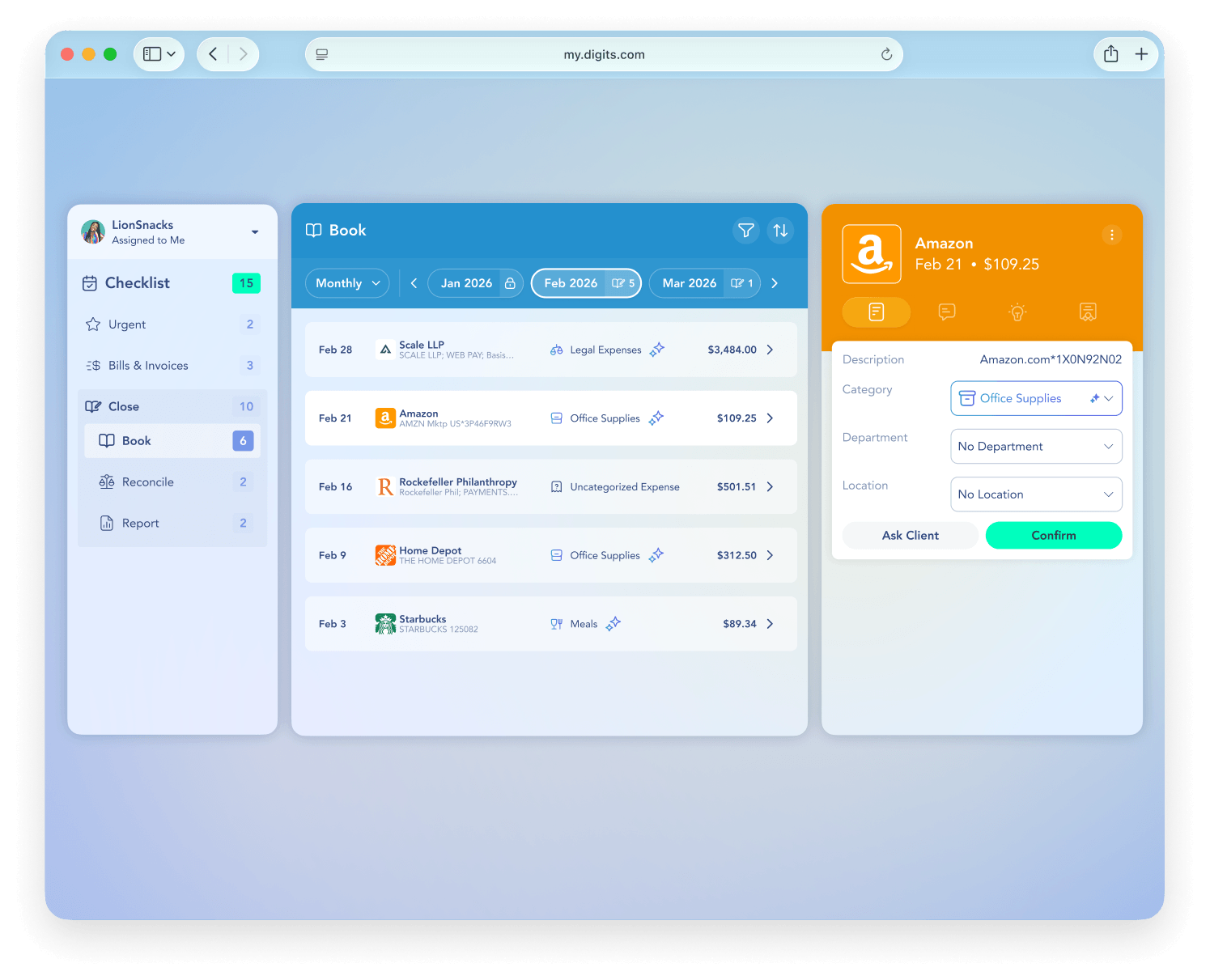
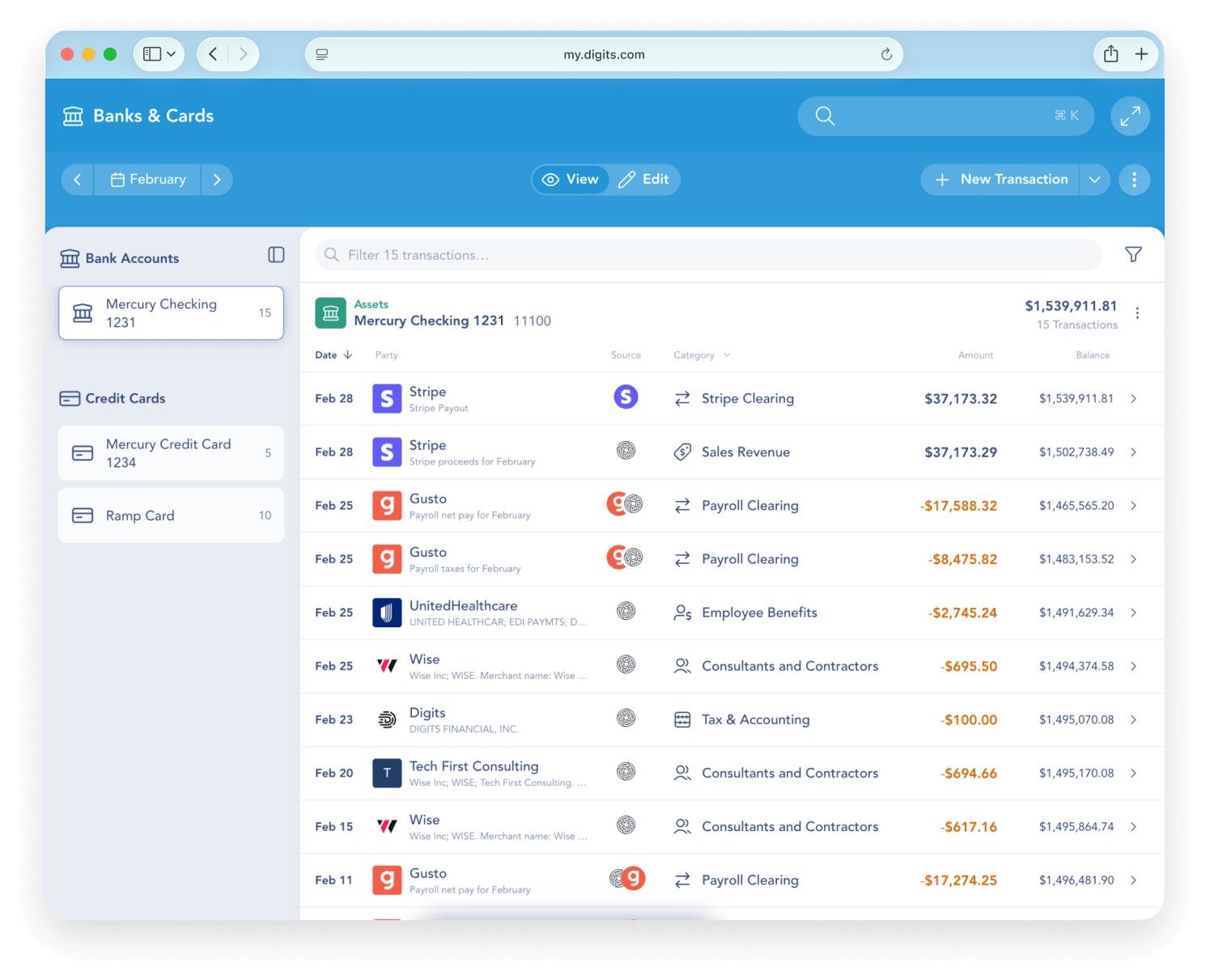
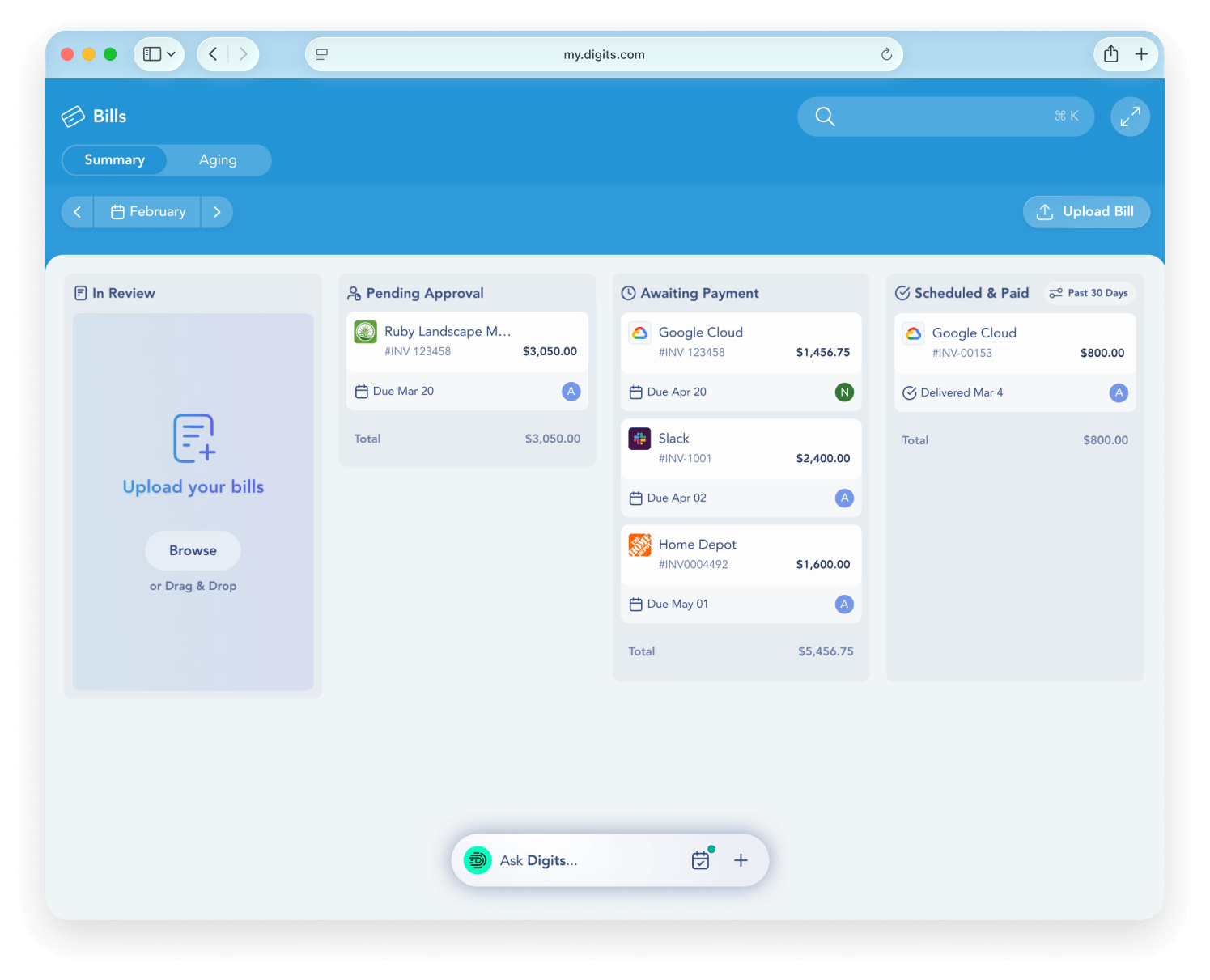
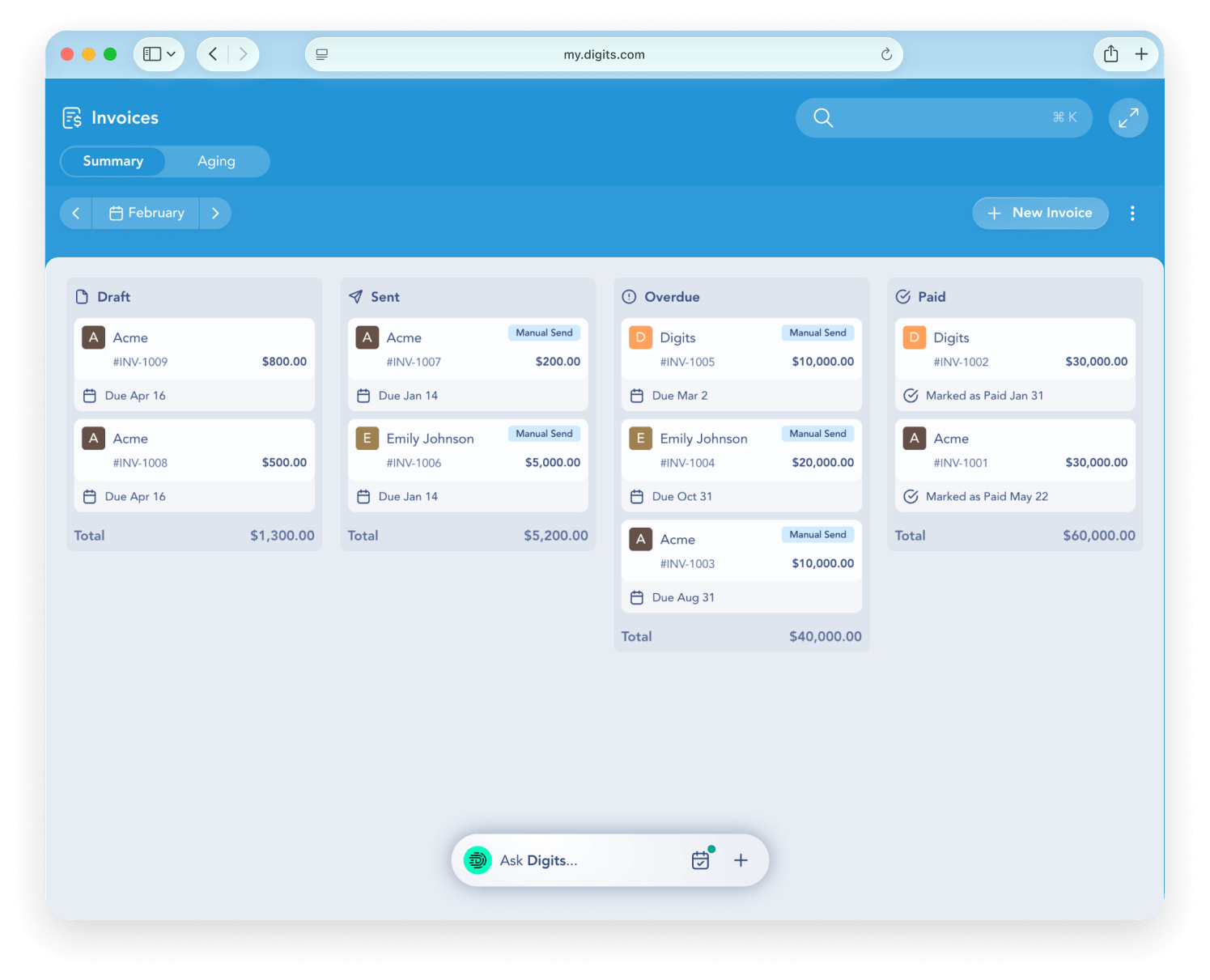
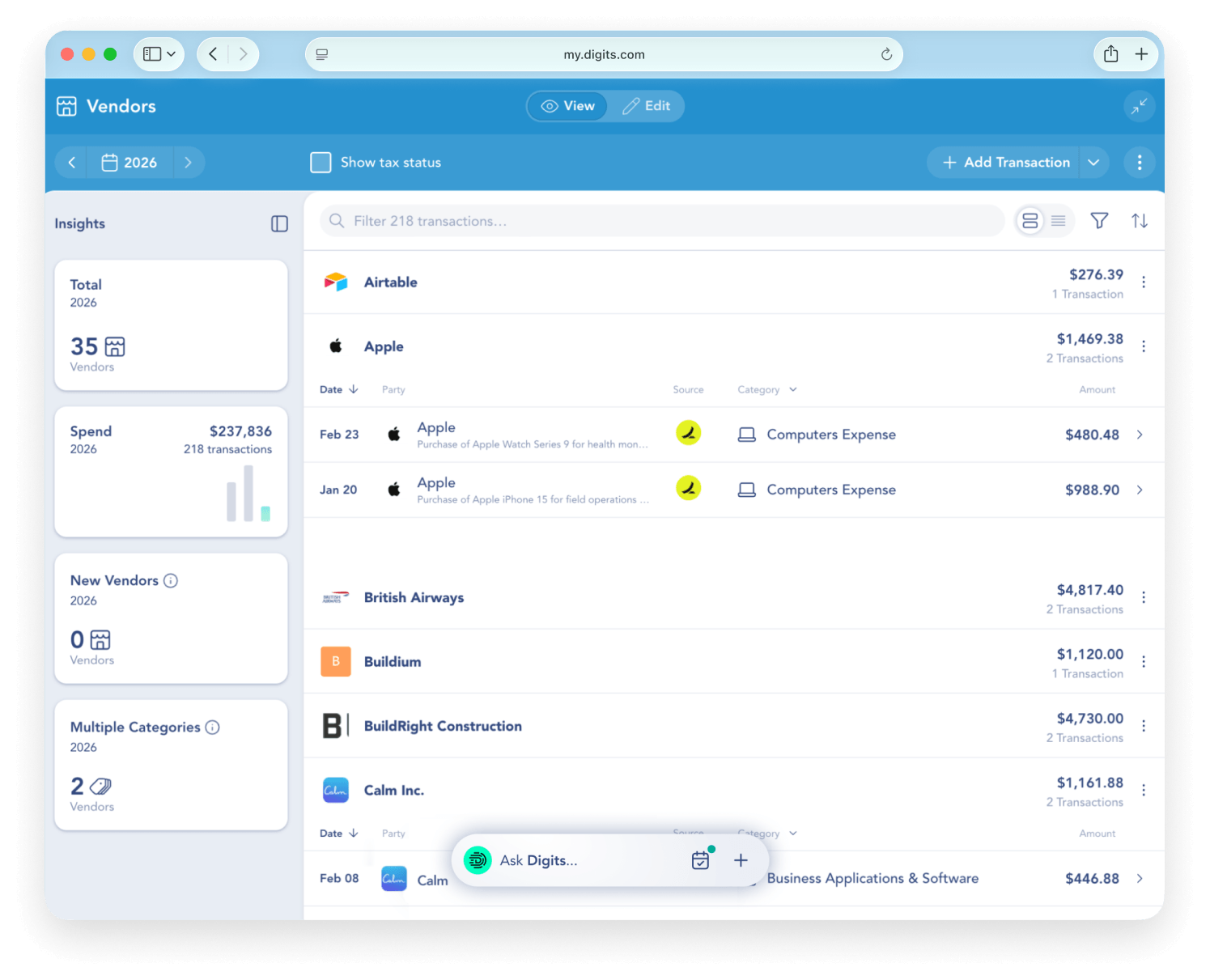
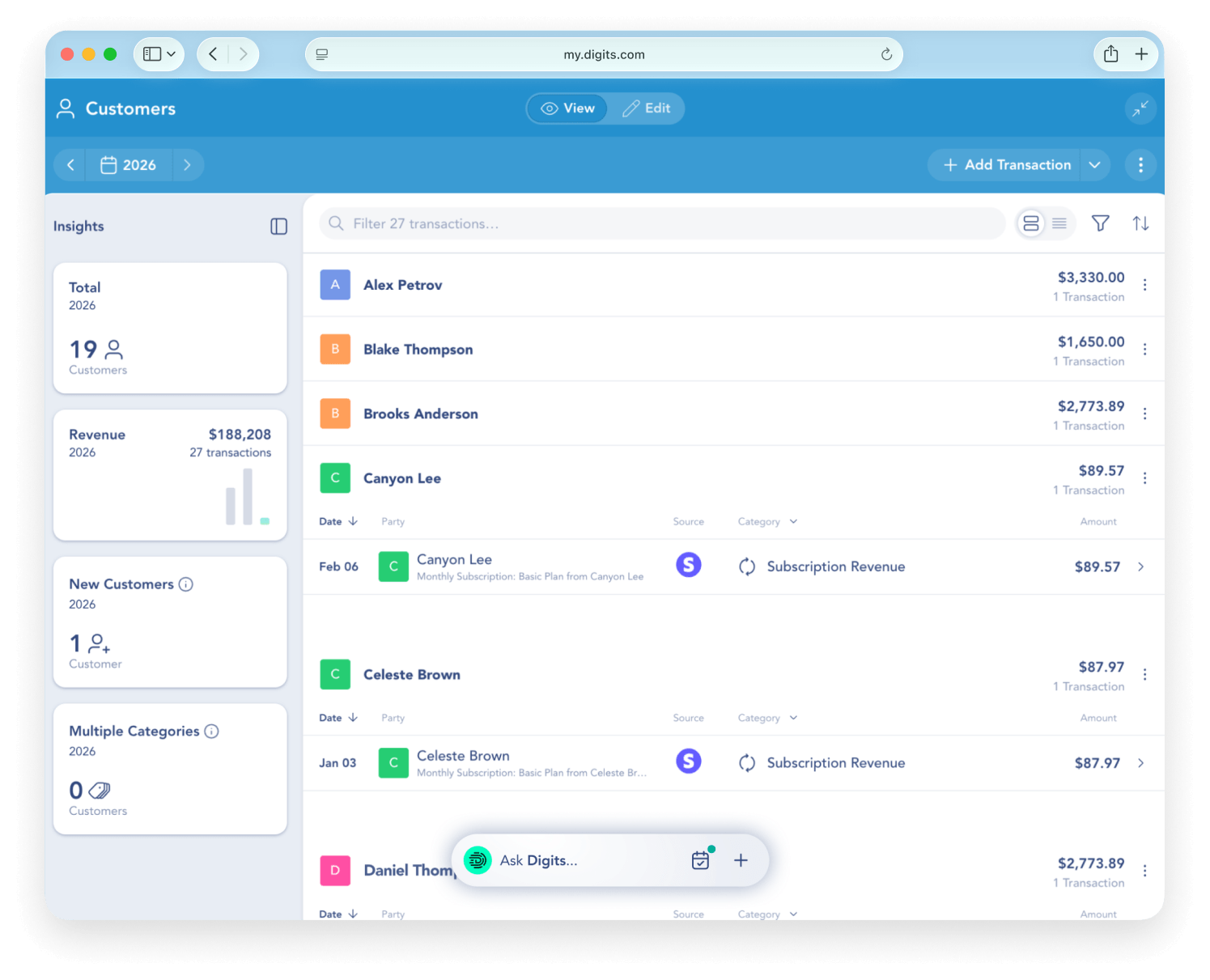
Key features include: Real-time categorization, Automated reconciliations, Live data you can trust, Dimensional accounting, Stay on top of runway, Smart insights, Your team, on the same page, Essentials.
Digits is commonly used for: Streamlining financial reporting for solopreneurs, Automating reconciliations for small businesses, Providing real-time insights for growing companies, Facilitating dimensional accounting for multi-entity operations, Enhancing collaboration among team members on financial data, Tracking runway and cash flow for early-stage startups.
Digits integrates with: QuickBooks, Xero, Stripe, PayPal, Shopify, Square, Zapier, Google Sheets, Slack, Microsoft Teams.
Based on user reviews and social mentions, the most common pain points are: spending too much, token usage.
Rowan Cheung
Founder at The Rundown AI
1 mention

Digits - Introducing Digits for iPhone & iPad
Mar 31, 2026
Based on 113 social mentions analyzed, 0% of sentiment is positive, 100% neutral, and 0% negative.




