Ema, a Universal AI Employee, is the leading enterprise partner for building and deploying AI Agents across all roles and industries
"Ema" is generally well-received by users, garnering multiple 5-star ratings on g2, pointing towards its strong performance and user satisfaction. Despite this, there are a few user complaints, primarily concerning its usability, as reflected by a 3.5/5 and 2/5 rating. There is no specific pricing sentiment available from the reviews, but the high ratings suggest users find value in the product. Overall, "Ema" maintains a positive reputation with consistent high scores, indicating it's reliable and appreciated by most users.
Mentions (30d)
2
Avg Rating
4.6
20 reviews
Platforms
9
Sentiment
25%
35 positive




"Ema" is generally well-received by users, garnering multiple 5-star ratings on g2, pointing towards its strong performance and user satisfaction. Despite this, there are a few user complaints, primarily concerning its usability, as reflected by a 3.5/5 and 2/5 rating. There is no specific pricing sentiment available from the reviews, but the high ratings suggest users find value in the product. Overall, "Ema" maintains a positive reputation with consistent high scores, indicating it's reliable and appreciated by most users.
Features
Use Cases
Industry
information technology & services
Employees
130
Funding Stage
Series A
Total Funding
$61.0M
OpenAI’s Game-Changing o1 Description: Big news in the AI world! OpenAI is shaking things up with the launch of ChatGPT Pro, priced at $200/month, and it’s not just a premium subscription—it’s a glim
OpenAI’s Game-Changing o1 Description: Big news in the AI world! OpenAI is shaking things up with the launch of ChatGPT Pro, priced at $200/month, and it’s not just a premium subscription—it’s a glimpse into the future of AI. Let me break it down: First, the Pro plan offers unlimited access to cutting-edge models like o1, o1-mini, and GPT-4o. These aren’t your typical language models. The o1 series is built for reasoning tasks—think solving complex problems, debugging, or even planning multi-step workflows. What makes it special? It uses “chain of thought” reasoning, mimicking how humans think through difficult problems step by step. Imagine asking it to optimize your code, develop a business strategy, or ace a technical interview—it can handle it all with unmatched precision. Then there’s o1 Pro Mode, exclusive to Pro subscribers. This mode uses extra computational power to tackle the hardest questions, ensuring top-tier responses for tasks that demand deep thinking. It’s ideal for engineers, analysts, and anyone working on complex, high-stakes projects. And let’s not forget the advanced voice capabilities included in Pro. OpenAI is taking conversational AI to the next level with dynamic, natural-sounding voice interactions. Whether you’re building voice-driven applications or just want the best voice-to-AI experience, this feature is a game-changer. But why $200? OpenAI’s growth has been astronomical—300M WAUs, with 6% converting to Plus. That’s $4.3B ARR just from subscriptions. Still, their training costs are jaw-dropping, and the company has no choice but to stay on the cutting edge. From a game theory perspective, they’re all-in. They can’t stop building bigger, better models without falling behind competitors like Anthropic, Google, or Meta. Pro is their way of funding this relentless innovation while delivering premium value. The timing couldn’t be more exciting—OpenAI is teasing a 12 Days of Christmas event, hinting at more announcements and surprises. If this is just the start, imagine what’s coming next! Could we see new tools, expanded APIs, or even more powerful models? The possibilities are endless, and I’m here for it. If you’re a small business or developer, this $200 investment might sound steep, but think about what it could unlock: automating workflows, solving problems faster, and even exploring entirely new projects. The ROI could be massive, especially if you’re testing it for just a few months. So, what do you think? Is $200/month a step too far, or is this the future of AI worth investing in? And what do you think OpenAI has in store for the 12 Days of Christmas? Drop your thoughts in the comments! #product #productmanager #productmanagement #startup #business #openai #llm #ai #microsoft #google #gemini #anthropic #claude #llama #meta #nvidia #career #careeradvice #mentor #mentorship #mentortiktok #mentortok #careertok #job #jobadvice #future #2024 #story #news #dev #coding #code #engineering #engineer #coder #sales #cs #marketing #agent #work #workflow #smart #thinking #strategy #cool #real #jobtips #hack #hacks #tip #tips #tech #techtok #techtiktok #openaidevday #aiupdates #techtrends #voiceAI #developerlife #o1 #o1pro #chatgpt #2025 #christmas #holiday #12days #cursor #replit #pythagora #bolt
View originalg2
What do you like best about ModMed?It's a great EMR system and very user friendly. Review collected by and hosted on G2.com.What do you dislike about ModMed?Sometimes it does run slow or lag/glitch. Review collected by and hosted on G2.com.
What do you like best about ModMed?Modmed is super easy to use and super easy to check in and out patients. As well as is something that is very beneficial to users for providers and patients. Review collected by and hosted on G2.com.What do you dislike about ModMed?Nothing everything about using modmed is very easy. Review collected by and hosted on G2.com.
What do you like best about ModMed?I truly appreciate ModMed for its exceptional organization and technological advancements, which significantly enhance the efficiency of my dermatology practice. The ability to keep patient data organized streamlines our workflow remarkably well, ensuring that everything runs smoothly. I am impressed by how efficiently ModMed facilitates documentation and organization within our operations. The setup process was notably easy, making the initial transition to ModMed seamless without any complications. Overall, I'm very satisfied with everything ModMed offers, including its advanced features, and I am happy with how it meets my needs without any issues. Review collected by and hosted on G2.com.What do you dislike about ModMed?I can't think of anything I don't like about Modmed. Review collected by and hosted on G2.com.
What do you like best about ModMed?I genuinely appreciate ModMed's ability to automate different aspects of our dermatology clinic's workflow. This feature optimizes our efficiency and allows us to focus on patient care rather than on repetitive administrative tasks. I also value the robust support network that ModMed provides; the availability of multiple people ready to help ensures that any issues we face can be quickly addressed, which greatly enhances our overall experience with the software. Additionally, the text reminder functionality is particularly beneficial, as it helps ensure that our patients receive timely reminders about their appointments. This feature has significantly reduced missed appointments and helps us maintain a smooth operation within our clinic. Review collected by and hosted on G2.com.What do you dislike about ModMed?I find that the products often don't live up to the quality they promise. Whenever new features or products are released, they tend to over-promise and under-deliver. It would be more helpful if there was transparency about the current status and limitations of new functionalities, acknowledging that not everything new will be perfect out of the gate. Review collected by and hosted on G2.com.
What do you like best about ModMed?I find ModMed to be incredibly user-friendly, which is essential for my work in dermatology practice. Having spent 19 years in healthcare, I can confidently say it's the easiest program to learn and use, which greatly impacts my workflow. The ease of learning and using ModMed not only saves time but also reduces the stress associated with complicated software systems. I also appreciate the support provided by Brandy, who is always there to help with any billing questions, demonstrating a strong customer support experience. This combination of a user-friendly interface and reliable support enhances my daily operations significantly and contributes to a seamless work environment. Additionally, the ease of initial setup was a breeze, making it even more convenient to get started with ModMed. I am extremely satisfied with the service, and on a scale from 1 to 10, I would recommend ModMed with a strong rating of 10. Review collected by and hosted on G2.com.What do you dislike about ModMed?I wish the insurance verification process within ModMed was more comprehensive and could verify all insurances effectively. Additionally, I think it would be beneficial if the system could automatically update when new information from insurance carriers is available. Review collected by and hosted on G2.com.
What do you like best about ModMed?I find ModMed incredibly useful for its intuitive and user-friendly interface, which greatly facilitates my work in a dermatology practice. One of the standout features for me is the efficient insurance verification process, which seamlessly verifies benefits and streamlines administrative tasks. This efficiency not only saves time but also reduces potential errors, enhancing the overall workflow. Additionally, I appreciate the ease of creating patient charts, which simplifies documentation and record-keeping. Compared to previous software, the setup process for ModMed was significantly smoother, instilling confidence in its use right from the start. The overall usability and functionality of ModMed have notably improved our practice's operational efficiency, making it a highly recommended tool for my colleagues. Review collected by and hosted on G2.com.What do you dislike about ModMed?I feel that ModMed could significantly improve the note-taking area. It's important for me to document in the patients' chart in a way that captures the date and the identity of the person making the notes, so others can easily follow and understand the documentation trail. This feature is crucial for effective team collaboration and continuity in patient care. Review collected by and hosted on G2.com.
What do you like best about ModMed?I love ModMed for its constant innovation, which keeps the software at the cutting edge and helps me stay ahead in my practice. The integration with iOS is seamless and reliable, enabling me to work efficiently on my preferred devices without any hitches. I appreciate that ModMed helps with organization, practice management, and utilizes AI features effectively, which simplifies numerous aspects of my dermatology practice. The experience of working with an implementation manager made the initial setup straightforward, ensuring a smooth transition to using the product. I am extremely satisfied with ModMed's performance, to the extent that I would rate my likelihood of recommending it a perfect 10. Review collected by and hosted on G2.com.What do you dislike about ModMed?there's nothing I don't like about it Review collected by and hosted on G2.com.
What do you like best about ModMed?I find ModMed incredibly useful for quickly reviewing patient charts, which is essential in my dermatology practice. The ease of chart review, especially using the visual body feature, allows me to efficiently assess and compare patient photos from previous to current visits. This capability is particularly valuable as it provides on-the-fly information, which is crucial when I'm out of the office and need to reference patient records. I love the integration with Apple devices, enhancing my interaction and accessibility with the software. The ability to create stickies for counseling and recommendations facilitates efficient documentation and communication, streamlining my workflow significantly. Additionally, the easily added phrases feature helps in inserting common statements quickly, making chart management more efficient. Review collected by and hosted on G2.com.What do you dislike about ModMed?I find incorporating attachments into ModMed cumbersome, and embedding them directly into the chart for consultants is not as seamless as I would like. The lack of a hyperlink feature within the body of notes to link directly to corresponding photos or written impressions adds unnecessary complexity to workflow. I also feel that the area reserved for important patient details like allergies, blood thinner use, and other critical information is not prominently displayed, which could improve through a more visible interface. The absence of color-coding for different types of visits also reduces the clarity in the schedule and could enhance organization. Searching for other HISP direct mail users and their addresses isn't as intuitive as expected. It would be beneficial if ModMed could support dot phrases similar to those in Epic, allowing for more efficient shorthand note-taking. The limited functionality of native phrases in EMA, and the inability to copy or utilize phrases from others, further restricts efficiency. Lastly, the transition to using ModMed was made difficult by the lack of adequate time with experts. The promised expert guidance was insufficient, making the setup process more challenging than necessary. Review collected by and hosted on G2.com.
What do you like best about ModMed?I find ModMed to be an outstanding EMR/PM system that is both streamlined and efficient, which significantly enhances my workflow in dermatology. The system's efficiency is one of the most crucial aspects that I value, as it facilitates smooth operations in my practice. I also appreciate how easy billing and scrubbing of claims are using ModMed, which contributes positively to maintaining a successful cash flow. Another feature I enjoy is the simplicity of scheduling, making it hassle-free to organize appointments. Additionally, the ModMed conference is a fantastic avenue for learning about new advancements and networking with peers, further enriching my use of the software. Review collected by and hosted on G2.com.What do you dislike about ModMed?The integration with Klara has limitations in functionality beyond appointment reminders. Review collected by and hosted on G2.com.
What do you like best about ModMed?I find ModMed to be incredibly user-friendly, which has been a significant advantage as I acclimate to a new practice. Learning a new system can be daunting, but ModMed's intuitive design has made this transition much easier for me. I particularly appreciate the prescription management feature, which offers distinct sections for initiating, continuing, and discontinuing treatments, and allows for information to be easily copied and pasted. The initial setup of ModMed was straightforward, enhancing its accessibility for new users like myself. Overall, my positive experience with ModMed translates into a high likelihood of recommending it to others, which I expressed by giving it a recommendation score of 10. Review collected by and hosted on G2.com.What do you dislike about ModMed?nothing I do not like at this point Review collected by and hosted on G2.com.
Self-calibrating cross-camera homography for real-time ghost prediction in multi-camera person tracking[P]
The problem: In multi-camera tracking, when camera A loses track of a person but camera B still sees them, naive approaches extrapolate pixel coordinates linearly. This fails immediately because cameras have completely different coordinate systems. A person at pixel (400, 300) on camera B might be at (800, 500) on camera A, depending on relative position and angle. Approach: When both cameras simultaneously observe the same person (matched via 64-dim HSV appearance descriptors, L2-normalized, EMA-smoothed at alpha=0.3), we record foot-point correspondence pairs. Bottom-center of the bounding box in each view projects to the same physical ground-plane point. After 4+ such pairs, cv2.findHomography() + RANSAC gives a 3x3 matrix H mapping camera B pixel space to camera A. System auto-relearns every 5 new pairs and monitors reprojection error, flushing H if it spikes (camera moved). Three fallback paths: Path A (H-PROJ, green): homography projection from any source camera with valid H. Most accurate. Path B (EXTRAP, red): pixel extrapolation with adaptive budget min(250px, 80 + 40*t). Last resort. Path C (WORLD, orange): world-coordinate pinhole projection from fused 3D Kalman state. Always available. Costs: Homography re-estimation: < 0.1ms (called every 5 new pairs) Per-prediction projection: < 0.001ms Tracking: Hungarian assignment with 0.6 * IoU + 0.4 * cosine appearance cost. DeepSORT (MobileNet) as primary, falls back to Hungarian (scipy), then centroid. Sensor trust: Each camera earns trust [0.1, 1.0] via consistency. High-innovation measurements get down-weighted. Kalman measurement noise R scales per update based on confidence, bbox area, and sensor trust. Full implementation: github.com/mandarwagh9/overwatch. 57 unit tests covering Kalman, homography, tracking. CI on GitHub Actions. Limitations: ground-plane homography breaks for elevated cameras with steep angles. Re-ID via HSV histograms is weak for people in similar clothing at close spatial proximity. Curious if anyone has tackled non-ground-plane cross-camera projection or used learned embeddings instead of HSV histograms for re-ID at this inference budget. submitted by /u/Straight_Stable_6095 [link] [comments]
View originalMy AI agent rewrote my entire service instead of fixing one bug. So I built a leash for it.
I was staring at my monitoring dashboard one morning watching response times quietly climb. Not crashing, just... degrading. The kind of thing that's easy to ignore until it isn't. I dropped the problem into my AI agent. Described the symptoms, pointed it at the relevant files, and let it go. An hour later it had "fixed" it. It had also restructured three modules, changed how we handled DB connections, and rewritten a threading section I hadn't asked it to touch. Response times were better. Everything else was a mess I now had to understand and justify. That's when I realized the problem wasn't the AI. It was that I never gave it boundaries. It didn't know what "done" looked like. It didn't know what was off-limits. It was just... optimizing for something, and I hadn't told it what. So I built two slash commands: /ame and /ema. /ame runs a single compiled interview with all the right questions at once depending on your project scope, and writes a confirmed spec to .ame/spec.md. One exchange. No back and forth. /ema reads that spec, maps out which architectural layers the work touches, builds a dependency-ordered plan, and executes chunk by chunk with your confirmation at each step. Here's how they've actually held up: The DB + threading bug (the one that started all this) Logs were showing creeping latency under concurrent load. I ran /ame with a one-liner and it immediately asked the things I hadn't thought to specify: what's the concurrency model, where does the thread pool live, is the DB connection pooled or per-request, what does a successful fix look like in the monitoring dashboard, and critically, what am I not allowed to touch. I answered once. It wrote the spec. Then /ema broke the work into three chunks: instrument first, identify the bottleneck, fix only that. It didn't touch the threading layer until it had confirmed what the query profiling showed. The fix was surgical. Two files changed. That was it. Instantly visible performance upgrade. OPC-UA PoC for a machine sensor alerting system I needed a PoC that could subscribe to machine sensor data from a Unified Automation server and feed it into an alerting pipeline. If you've worked with OPC-UA you know that "just connect to the server" can mean twelve different things depending on security policy, certificate handling, and subscription config. I'd been burned before by agents that confidently scaffold the wrong thing. /ame caught all of it before a single file was created. It asked which security mode, whether we were doing certificate auth or anonymous for the PoC, what the subscription interval should be, what "alerting" meant at the data layer, threshold crossing, rate of change, or raw value delivery. I answered in one shot. The spec that came out was specific enough that /ema scaffolded the UA client layer correctly on the first try. The PoC connected to the server and was pushing sensor events into the alerting pipeline the same day. Long story short, my employer was thoroughly impressed with what I presented to them. A background sync job between an external API and local DB I'd been putting this one off for weeks because "I need to think it through." The usual conflict resolution when both sides update, retry logic, what happens when the API rate limits you, whether the sync is append-only or bidirectional. Ran /ame with a rough one-liner. It correctly estimated full scope and asked about all the things I'd been vaguely worried about but hadn't written down: sync direction, conflict strategy, idempotency, failure recovery, and whether partial sync states needed to be visible anywhere in the UI. I answered everything in one go. The spec it produced was more complete than what I would have written manually on a good day. /ema gave me a clean three-chunk plan. Schema and models first, sync logic second, retry and error handling third. I ran it across an afternoon. No rewrites, no surprises, no "oh I didn't think about that" at 11pm. Works in VS Code (Copilot Agent mode), Claude Code, and Google Antigravity. Install: npx skills add github:CSKishan/ame-skill Or just copy the files manually. The README has paths for all three IDEs. MIT. Free. No accounts. → github.com/CSKishan/ame-skill Curious what breaks it. Try it on something ugly and let me know. PSA: AME stands for "Ask Me Exhaustively" and EMA stands for "Enclose My Analysis". submitted by /u/Wucrsman [link] [comments]
View originalUsing Claude to read real chart data (OHLCV + indicators) - looking for feedback on approach
I've been experimenting with using Claude as a chart analysis assistant, and ended up building a small charting app around it using Claude Code. The idea was to move away from screenshot-based analysis and instead let Claude read actual chart data - OHLCV, indicators, volume, fundamentals, and news - and answer questions about what's happening. Some example interactions: • "Can you scan this stock for Minervini criteria" • "Can you find any good trade setup?" • "What's the latest news about US-Iran situation" • "Backtest EMA crossover" Instead of describing the chart, Claude gets structured data like: • OHLCV time series • Indicator values (EMA, RSI, etc.) • Fundamentals and earnings data • Recent headlines Screenshots: https://imgur.com/a/mZm3TS3 App: https://fyntro.vercel.app/ What it currently does: • Ask chart questions (trend, support/resistance, entries) • Control chart via chat ("switch to NVDA 15m", "add 200 EMA") • Backtest simple strategies (win rate, Sharpe, drawdown, plotted trades) • Pull earnings, fundamentals, and headlines • Scan watchlist for setups (like Minervini trend template) A few things I'm still figuring out: • Sometimes Claude over-interprets noisy signals • Context window management for larger timeframes • Balancing structured logic vs LLM reasoning • Token cost when users iterate heavily Built solo and still early, so there are definitely rough edges. Curious if anyone here has experimented with: • Tool-calling for time-series analysis • Hybrid rule-based + LLM approaches • Prompt strategies for technical analysis • Reducing token usage for interactive chart sessions Would love any feedback on the approach or architecture. submitted by /u/Aegon5247 [link] [comments]
View originalMeta's new structured prompting technique makes LLMs significantly better at code review — boosting accuracy to 93% in some cases
Deploying AI agents for repository-scale tasks like bug detection, patch verification, and code review requires overcoming significant technical hurdles. One major bottleneck: the need to set up dynamic execution sandboxes for every repository, which are expensive and computationally heavy. Using large language model (LLM) reasoning instead of executing the code is rising in popularity to bypass this overhead, yet it frequently leads to unsupported guesses and hallucinations. To improve execution-free reasoning, researchers at Meta introduce "semi-formal reasoning," a structured prompting technique. This method requires the AI agent to fill out a logical certificate by explicitly stating premises, tracing concrete execution paths, and deriving formal conclusions before providing an answer. The structured format forces the agent to systematically gather evidence and follow function calls before drawing conclusions. This increases the accuracy of LLMs in coding tasks and significantly reduces errors in fault localization and codebase question-answering. For developers using LLMs in code review tasks, semi-formal reasoning enables highly reliable, execution-free semantic code analysis while drastically reducing the infrastructure costs of AI coding systems. Agentic code reasoning Agentic code reasoning is an AI agent's ability to navigate files, trace dependencies, and iteratively gather context to perform deep semantic analysis on a codebase without running the code. In enterprise AI applications, this capability is essential for scaling automated bug detection, comprehensive code reviews, and patch verification across complex repositories where relevant context spans multiple files. The industry currently tackles execution-free code verification through two primary approaches. The first involves unstructured LLM evaluators that try to verify code either directly or by training specialized LLMs as reward models to approximate test outcomes. The major drawback is their
View originalNvidia-backed ThinkLabs AI raises $28 million to tackle a growing power grid crunch
ThinkLabs AI, a startup building artificial intelligence models that simulate the behavior of the electric grid, announced today that it has closed a $28 million Series A financing round led by Energy Impact Partners (EIP), one of the largest energy transition investment firms in the world. Nvidia’s venture capital arm NVentures and Edison International, the parent company of Southern California Edison, also participated in the round. The funding marks a significant escalation in the race to apply AI not just to software and content generation, but to the physical infrastructure that powers modern life. While most AI investment headlines have centered on large language models and generative tools, ThinkLabs is pursuing a different and arguably more consequential application: using physics-informed AI to model the behavior of electrical grids in real time, compressing engineering studies that once took weeks or months into minutes. "We are dead focused on the grid," ThinkLabs CEO Josh Wong told VentureBeat in an exclusive interview ahead of the announcement. "We do AI models to model the grid, specifically transmission and distribution power flow related modeling. We can calculate things like interconnection of large loads — like data centers or electric vehicle charging — and understand the impact they have on the grid." The round drew participation from a deep bench of returning investors, including GE Vernova, Powerhouse Ventures, Active Impact Investments, Blackhorn Ventures, and Amplify Capital, along with an unnamed large North American investor-owned utility. The company initially set out to raise less than $28 million, according to Wong, but strong demand from strategic partners pushed the round higher. "This was way oversubscribed," Wong said. "We attracted the right ecosystem partners and the right capital partners to grow with, and that's how we ended up at $28 million." Why surging electricity demand is breaking the grid's legacy planning tools The timing
View originalScaleOps raises $130M to improve computing efficiency amid AI demand
ScaleOps just raised $130M to tackle GPU shortages and soaring AI cloud costs by automating infrastructure in real time.
View originalMathematical methods and human thought in the age of AI
View originalMade an MCP server that lets Claude backtest trading strategies - no API keys, works in 30 seconds
Been building this for a few weeks and figured I'd share. I trade on the side and was tired of the setup friction every time I wanted to test a strategy idea - spin up Python, load pandas, write boilerplate. So I turned it into an MCP server. Now I just ask Claude. What it does: - Backtest 6 strategies: RSI, Bollinger, MACD, EMA cross, Supertrend, Donchian Channel - Real metrics: Sharpe ratio, max drawdown, win rate, profit factor, expectancy - Simulates commission + slippage (realistic numbers, not fantasy) - Pulls data from Yahoo Finance - no API key needed - Compare all strategies on the same ticker at once Actual results I got today: AAPL 2yr backtest (fees included): #1 Supertrend: +14.6% | Sharpe 3.09 | WR 37% #2 Bollinger: +13.0% | Sharpe 6.95 | WR 75% #3 RSI: +2.7% | WR 100% (only 2 trades lol) #6 MACD: -9.1% (ouch) Buy & hold: +45.1% - so most strategies lost to passive. At least now I know. BTC 2yr RSI: +31.5% vs buy-and-hold at -5% Setup is literally just adding this to claude_desktop_config.json: {"mcpServers": {"tradingview": {"command": "uvx", "args": ["tradingview-mcp-server"]}}} Also has Reddit sentiment analysis, live Yahoo Finance quotes, 25+ TradingView tools across Binance, NASDAQ, etc. GitHub: https://github.com/atilaahmettaner/tradingview-mcp Feedback welcome, still actively building this. submitted by /u/Cool_Assignment7380 [link] [comments]
View originalNvidia’s NemoClaw has three layers of agent security. None of them solve the real problem.
The speed of LLM adoption demands that we check its trajectory from time to time. CEO Jensen Huang, talking at The post Nvidia’s NemoClaw has three layers of agent security. None of them solve the real problem. appeared first on The New Stack.
View original[R] Controlled experiment: giving an LLM agent access to CS papers during automated hyperparameter search improves results by 3.2%
Ran a controlled experiment measuring whether LLM coding agents benefit from access to research literature during automated experimentation. Setup: Two identical runs using Karpathy's autoresearch framework. Claude Code agent optimizing a ~7M param GPT-2 on TinyStories. M4 Pro, 100 experiments each, same seed config. Only variable — one agent had access to an MCP server that does full-text search over 2M+ CS papers and returns synthesized methods with citations. Results: Without papers With papers Experiments run 100 100 Papers considered 0 520 Papers cited 0 100 Techniques tried standard 25 paper-sourced Best improvement 3.67% 4.05% 2hr val_bpb 0.4624 0.4475 Gap was 3.2% and still widening at the 2-hour mark. Techniques the paper-augmented agent found: AdaGC — adaptive gradient clipping (Feb 2025) sqrt batch scaling rule (June 2022) REX learning rate schedule WSD cooldown scheduling What didn't work: DyT (Dynamic Tanh) — incompatible with architecture SeeDNorm — same issue Several paper techniques were tried and reverted after failing to improve metrics Key observation: Both agents attempted halving the batch size. Without literature access, the agent didn't adjust the learning rate — the run diverged. With access, it retrieved the sqrt scaling rule, applied it correctly on first attempt, then successfully halved again to 16K. Interpretation: The agent without papers was limited to techniques already encoded in its weights — essentially the "standard ML playbook." The paper-augmented agent accessed techniques published after its training cutoff (AdaGC, Feb 2025) and surfaced techniques it may have seen during training but didn't retrieve unprompted (sqrt scaling rule, 2022). This was deliberately tested on TinyStories — arguably the most well-explored small-scale setting in ML — to make the comparison harder. The effect would likely be larger on less-explored problems. Limitations: Single run per condition. The model is tiny (7M params). Some of the improvement may come from the agent spending more time reasoning about each technique rather than the paper content itself. More controlled ablations needed. I built the paper search MCP server (Paper Lantern) for this experiment. Free to try: https://code.paperlantern.ai Full writeup with methodology, all 15 paper citations, and appendices: https://www.paperlantern.ai/blog/auto-research-case-study Would be curious to see this replicated at larger scale or on different domains. submitted by /u/kalpitdixit [link] [comments]
View original[P] Best approach for online crowd density prediction from noisy video counts? (no training data)
I have per-frame head counts from P2PNet running on crowd video clips. Counts are stable but noisy (±10%). I need to predict density 5-10 frames ahead per zone, and estimate time-to-critical-threshold. Currently using EMA-smoothed Gaussian-weighted linear extrapolation. MAE ~20 on 55 frames. Direction accuracy 49% (basically coin flip on reversals). No historical training data available. Must run online/real-time on CPU. What would you try? Kalman filter? Double exponential smoothing? Something else? submitted by /u/WitnessWonderful8270 [link] [comments]
View originalShow HN: Email.md – Markdown to responsive, email-safe HTML
View originalShow HN: Threadprocs – executables sharing one address space (0-copy pointers)
This project launches multiple independent programs into a single shared virtual address space, while still behaving like separate processes (independent binaries, globals, and lifetimes). When threadprocs share their address space, pointers are valid across them with no code changes for well-behaved Linux binaries.<p>Unlike threads, each threadproc is a standalone and semi-isolated process. Unlike dlopen-based plugin systems, threadprocs run traditional executables with a `main()` function. Unlike POSIX processes, pointers remain valid across threadprocs because they share the same address space.<p>This means that idiomatic pointer-based data structures like `std::string` or `std::unordered_map` can be passed between threadprocs and accessed directly (with the usual data race considerations).<p>This accomplishes a programming model somewhere between pthreads and multi-process shared memory IPC.<p>The implementation relies on directing ASLR and virtual address layout at load time and implementing a user-space analogue of `exec()`, as well as careful manipulation of threadproc file descriptors, signals, etc. It is implemented entirely in unprivileged user space code: <<a href="https://github.com/jer-irl/threadprocs/blob/main/docs/02-implementation.md" rel="nofollow">https://github.com/jer-irl/threadprocs/blob/main/docs/02-imp...</a>>.<p>There is a simple demo demonstrating “cross-threadproc” memory dereferencing at <<a href="https://github.com/jer-irl/threadprocs/tree/main?tab=readme-ov-file#demo" rel="nofollow">https://github.com/jer-irl/threadprocs/tree/main?tab=readme-...</a>>, including a high-level diagram.<p>This is relevant to systems of multiple processes with shared memory (often ring buffers or flat tables). These designs often require serialization or copying, and tend away from idiomatic C++ or Rust data structures. Pointer-based data structures cannot be passed directly.<p>There are significant limitations and edge cases, and it’s not clear this is a practical model, but the project explores a way to relax traditional process memory boundaries while still structuring a system as independently launched components.
View originalBuilding a Semantic Search API with Spring Boot and pgvector - Part 3: The Embedding Layer.
Most semantic search tutorials treat embeddings as a single line of code — call the API, get a...
View originalHow to Stop My Agent from Getting Me Fired
This is fiction. For now. I have an AI agent connected to my email and Slack. It can read...
View originalEma uses a tiered pricing model. Visit their website for current pricing details.
Ema has an average rating of 4.6 out of 5 stars based on 20 reviews from G2, Capterra, and TrustRadius.
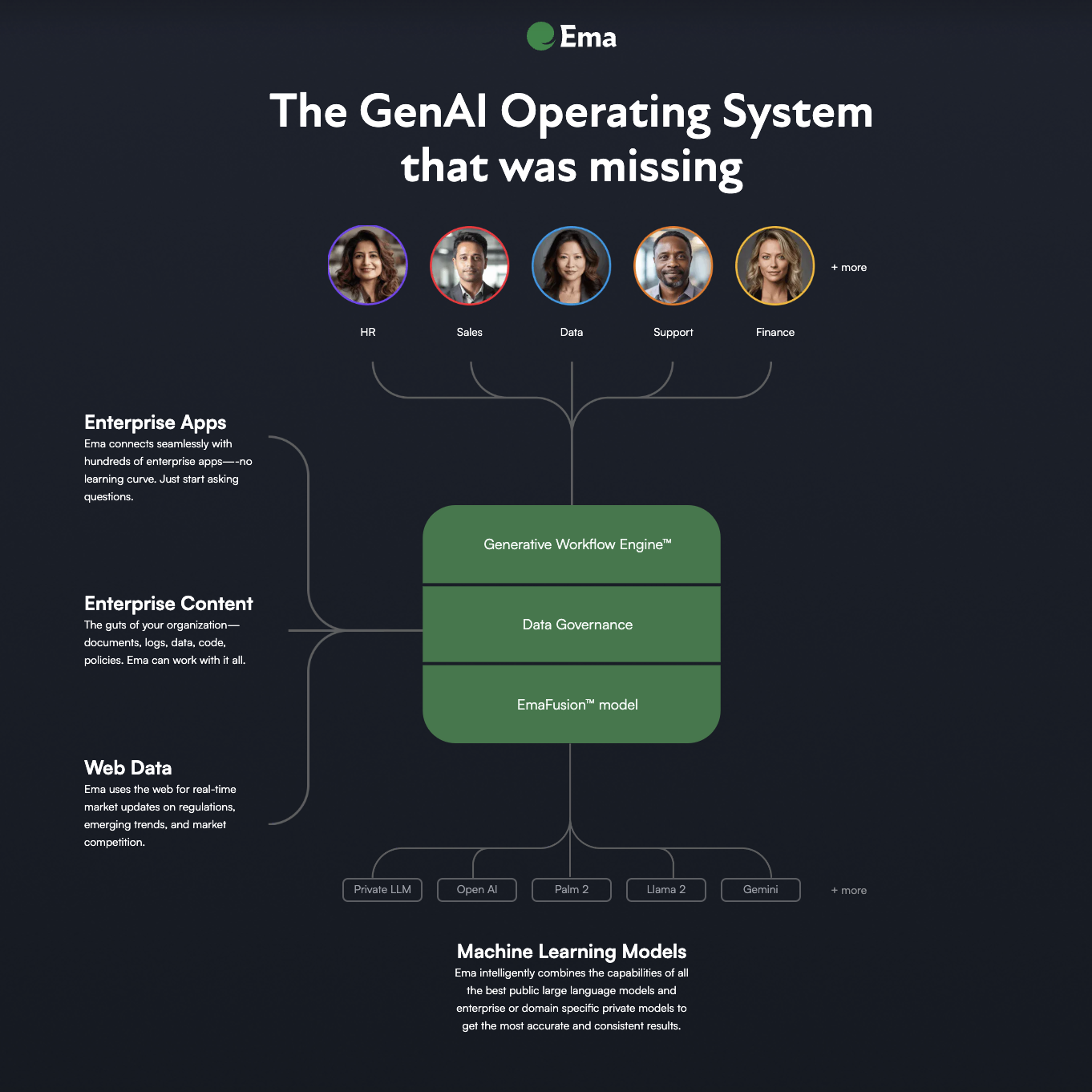
Key features include: Employee Experience, Customer Experience, Finance Operations, Why Hire Ema, HOW EMA WORKS.
Ema is commonly used for: Automating the recruitment process for new hires, Streamlining employee onboarding procedures, Managing employee benefits and compensation, Enhancing customer service through conversational AI, Interpreting financial data for decision-making, Automating compliance with data governance standards.
Ema integrates with: Workday, ADP, Salesforce, Slack, Microsoft Teams, QuickBooks, SAP, Oracle, Google Workspace, Zoom.
Creator at Math & AI YouTube
3 mentions
Based on user reviews and social mentions, the most common pain points are: token usage, token cost, large language model, llm.
Based on 138 social mentions analyzed, 25% of sentiment is positive, 61% neutral, and 14% negative.