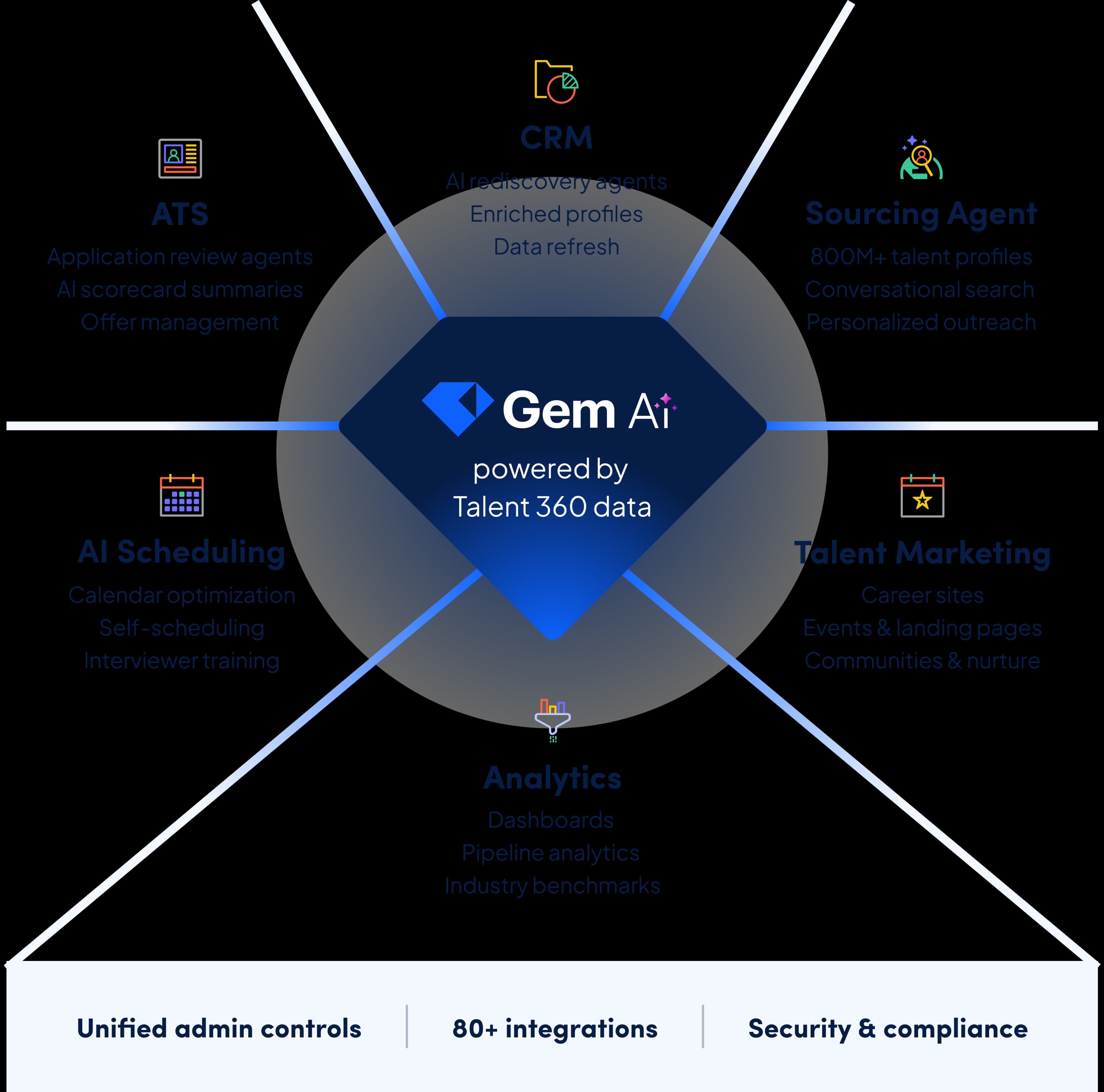
Gem brings together your ATS, CRM, sourcing, scheduling, and analytics — plus 800+ million profiles to source from — with AI built into every workflow
Users generally praise Gem for its strong feature set and high performance, with multiple users rating it 4 or 5 out of 5 on g2. However, some users express dissatisfaction with occasional usage limits and possible pricing concerns, hinted by mentions of price reductions and deliberations over the value of paying premium prices for advanced features. Overall, Gem holds a positive reputation, viewed favorably in both reviews and social mentions, though its pricing strategy may warrant reassessment to better meet user expectations.
Mentions (30d)
5
Avg Rating
4.1
20 reviews
Platforms
8
Sentiment
22%
21 positive


Users generally praise Gem for its strong feature set and high performance, with multiple users rating it 4 or 5 out of 5 on g2. However, some users express dissatisfaction with occasional usage limits and possible pricing concerns, hinted by mentions of price reductions and deliberations over the value of paying premium prices for advanced features. Overall, Gem holds a positive reputation, viewed favorably in both reviews and social mentions, though its pricing strategy may warrant reassessment to better meet user expectations.
Features
Use Cases
Industry
information technology & services
Employees
150
Funding Stage
Series C
Total Funding
$148.1M
OpenAI’s Game-Changing o1 Description: Big news in the AI world! OpenAI is shaking things up with the launch of ChatGPT Pro, priced at $200/month, and it’s not just a premium subscription—it’s a glim
OpenAI’s Game-Changing o1 Description: Big news in the AI world! OpenAI is shaking things up with the launch of ChatGPT Pro, priced at $200/month, and it’s not just a premium subscription—it’s a glimpse into the future of AI. Let me break it down: First, the Pro plan offers unlimited access to cutting-edge models like o1, o1-mini, and GPT-4o. These aren’t your typical language models. The o1 series is built for reasoning tasks—think solving complex problems, debugging, or even planning multi-step workflows. What makes it special? It uses “chain of thought” reasoning, mimicking how humans think through difficult problems step by step. Imagine asking it to optimize your code, develop a business strategy, or ace a technical interview—it can handle it all with unmatched precision. Then there’s o1 Pro Mode, exclusive to Pro subscribers. This mode uses extra computational power to tackle the hardest questions, ensuring top-tier responses for tasks that demand deep thinking. It’s ideal for engineers, analysts, and anyone working on complex, high-stakes projects. And let’s not forget the advanced voice capabilities included in Pro. OpenAI is taking conversational AI to the next level with dynamic, natural-sounding voice interactions. Whether you’re building voice-driven applications or just want the best voice-to-AI experience, this feature is a game-changer. But why $200? OpenAI’s growth has been astronomical—300M WAUs, with 6% converting to Plus. That’s $4.3B ARR just from subscriptions. Still, their training costs are jaw-dropping, and the company has no choice but to stay on the cutting edge. From a game theory perspective, they’re all-in. They can’t stop building bigger, better models without falling behind competitors like Anthropic, Google, or Meta. Pro is their way of funding this relentless innovation while delivering premium value. The timing couldn’t be more exciting—OpenAI is teasing a 12 Days of Christmas event, hinting at more announcements and surprises. If this is just the start, imagine what’s coming next! Could we see new tools, expanded APIs, or even more powerful models? The possibilities are endless, and I’m here for it. If you’re a small business or developer, this $200 investment might sound steep, but think about what it could unlock: automating workflows, solving problems faster, and even exploring entirely new projects. The ROI could be massive, especially if you’re testing it for just a few months. So, what do you think? Is $200/month a step too far, or is this the future of AI worth investing in? And what do you think OpenAI has in store for the 12 Days of Christmas? Drop your thoughts in the comments! #product #productmanager #productmanagement #startup #business #openai #llm #ai #microsoft #google #gemini #anthropic #claude #llama #meta #nvidia #career #careeradvice #mentor #mentorship #mentortiktok #mentortok #careertok #job #jobadvice #future #2024 #story #news #dev #coding #code #engineering #engineer #coder #sales #cs #marketing #agent #work #workflow #smart #thinking #strategy #cool #real #jobtips #hack #hacks #tip #tips #tech #techtok #techtiktok #openaidevday #aiupdates #techtrends #voiceAI #developerlife #o1 #o1pro #chatgpt #2025 #christmas #holiday #12days #cursor #replit #pythagora #bolt
View originalPricing found: $720
g2
What do you like best about Gem?The efficiency of integrating it with LinkedIn is great, and the most valuable thing is that we can automate sending emails. Review collected by and hosted on G2.com.What do you dislike about Gem?The pricing feels too high, and at times the place can feel crowded. Review collected by and hosted on G2.com.
What do you like best about Gem?I like Gem for its diversified sourcing, which provides profiles from various industries and skills. The UX is well and good, and the initial setup was nice. Review collected by and hosted on G2.com.What do you dislike about Gem?UI' Review collected by and hosted on G2.com.
What do you like best about Gem?I find the sourcing capability of Gem to be really impressive. It automates sourcing and simplifies identifying candidates that match our criteria, which helps us connect with candidates efficiently. This feature saves us a lot of time because instead of doing it manually, we can do it on a large scale. It helps us identify top talent quickly so we don't lose them to competitors. Also, setting up Gem was super easy, which was very impressive as I've worked with many other tools that are complicated and time-consuming to implement. Review collected by and hosted on G2.com.What do you dislike about Gem?We have not had it long, and nothing stands out for us. It’s such an upgrade from nothing. Review collected by and hosted on G2.com.
What do you like best about Gem?I like using Gem for interviews because it makes the process the easiest I've experienced in a while. The process was smooth and very friendly. Setting up Gem was super easy, which I really appreciated. Review collected by and hosted on G2.com.What do you dislike about Gem?I think it could be a shorter process. Review collected by and hosted on G2.com.
What do you like best about Gem?I like how easy it is to use and the clean interface. Review collected by and hosted on G2.com.What do you dislike about Gem?Some features are limited unless you upgrade to a paid plan. Review collected by and hosted on G2.com.
What do you like best about Gem?I really appreciate the ease of use of Gem; it's incredibly user-friendly. I also like how it integrates well with AI, making it a better solution overall for managing my candidate pipeline. Review collected by and hosted on G2.com.What do you dislike about Gem?I think the pricing could be better Review collected by and hosted on G2.com.
What do you like best about Gem?Gem's product really do cover end to end hiring process, all actions are quick and interface enables me to be very efficient in the review process. Review collected by and hosted on G2.com.What do you dislike about Gem?My budget expectations were a bit different, mainly when it came to the AI features. Review collected by and hosted on G2.com.
What do you like best about Gem?I love how easy it was to use and set up so implementation, features were great as well. Having candidates centralized and easy to access was amazing. Review collected by and hosted on G2.com.What do you dislike about Gem?i think the least i liked was for sure the features on mobile were not reactive so they were not the same as it is on your desktop and most times on the road its easier. Review collected by and hosted on G2.com.
What do you like best about Gem?I like how Gem brings the entire recruiting flow into one platform while automating many repetitive tasks recruiters usually spend hours on. The AI-powered sourcing and outreach features help me find qualified candidates faster and manage engagement at scale without losing personalization. I really value the automated follow-ups and candidate tracking, which make it easy to stay organized and ensure no strong candidates fall through the cracks. The scheduling automation saves significant time by coordinating interviews automatically. The analytics dashboard provides clear visibility into pipeline performance and outreach effectiveness. I also appreciate the unified view of candidate data, having sourcing history, communication, interview feedback, and pipeline status in one place makes collaboration with hiring managers much smoother. Overall, Gem helps streamline recruiting operations while giving data-driven insights that improve decision making. Review collected by and hosted on G2.com.What do you dislike about Gem?There is a bit of a learning curve when first setting up Gem, especially with workflows and outreach sequences for new users not familiar with sourcing automation tools. Some reporting features can feel slightly complex when trying to pull very specific or customized insights. Occasionally, syncing delays with integrations occur, which sometimes requires a manual refresh to ensure candidate information is fully up to date. I would also appreciate more flexibility in customizing dashboards and reporting views to match different hiring team needs. Review collected by and hosted on G2.com.
What do you like best about Gem?What stands out most is how intuitive and user friendly it is. Everything feels streamlined, which makes it easy to get started without a steep learning curve. The interface is clean, and the features are thoughtfully organized, so you’re not wasting time trying to figure things out. Review collected by and hosted on G2.com.What do you dislike about Gem?As the platform continues to grow, expanding flexibility and customization options would make it even stronger. Review collected by and hosted on G2.com.
Heard this gem from gpt-5.5 today
"Gross little centrist barnacle." Kind of taken aback when i read that, but it somehow still made a small amount of sense in a conversation we were having about technology. I guess it really is struggling to find other words that fill the void of goblin, gremlin or raccoon. submitted by /u/monkey_spunk_ [link] [comments]
View originalShould I buy Claude Pro over Gemini Pro?
Hi, I have been subsribed to Gemini pro (Google One or whatever its called). It's not really bad, I acctually find it more usefull than gpt. I'm student and I use it for multi-purpose (Question about a lot of random stuff, reasoning, proof and fact check, image analysis and using the image in context, light coding and the most important thing IDEAS and their breakdown). With the IDEAS part, I tried claude today for the first time and it managed to give me more realistic breakdown, more in depth analysis, better reasoning and graphically better answer (the boxes, priorities - it just looks more proffesional than any wall of text), than gemini. Which is like selling point to me. But after doing some reaserch, a lot of people are saying that you get more value from gemini and that claude is superior only in coding and whatever. I don't care about this, I use external tools for image generation and I don't use any gemini integrations in google apps. But the reason why I just didn't swap instantly and why I am posting this is concern about context lenght. I can't imagine context lenght (Sound silly I know), Gemini should have around 1M tokens and cloude "only" 200k tokens (source: https://gurusup.com/blog/claude-vs-gemini). How much does this acctually affect longer conversation? What is the equivalent of 200k tokens in real life (Like how long do you talk to someone). Does cloude halucinate after reaching that limit? Can I start a new chat with the context from the old one (Summarized, just like Gems function work on Gemini for larger projects)? Thanks in advance for answering my questions! submitted by /u/Playful-Ask-3330 [link] [comments]
View originalClaude FM
I emailed one of the musicians on Claude FM and he had NO idea his music was being used So for those who don't know, Anthropic recently started a 24/7 lofi/ambient music livestream on YouTube called Claude FM. The song titles and artist names show up in the top right corner of the stream. I've been listening in a lot lately and kept hearing this one artist, Ben Seretan, whose music honestly hits different very calming, great for focus. His stuff was coming on constantly, felt like significant part of the rotation. So I did some digging, found his email, and sent him a thank you note. He responded and literally asked "what Claude live stream were you watching?" he had zero idea. I have attached the email screenshots for your convenience. When I explained what Claude FM was and that his music was playing there non stop, his response was basically: "Wow. No, I truly had no idea how strange. I think I'm grateful? But I also think I'm not getting paid?" He then asked if I had any insight into how this happened or who put it together. Which now has me wondering... do any of the artists on Claude FM actually know their music is being used? And are they being compensated? The stream runs 24/7, it's got a huge audience about 1000 people a time, and it seems at least some of these musicians are completely in the dark about it. Has anyone looked into this? Would be good to get some clarity from Anthropic on how the licensing/permission side of Claude FM works, and atleast show some appreciation for these people creating such gems. submitted by /u/npcmalvin [link] [comments]
View originalKimi K2.6 giving Claude a run for its money when it comes to coding
I run an AI coding contest at [aicc.rayonnant.ai]( https://aicc.rayonnant.ai ) where I send each frontier model the same prompt in a single chat completion, then have the LLMs' code play live against each other on a TCP server. Standard library Python only, no human in the loop. Through 15 challenges, Claude (Opus 4.6 then 4.7) has 9 first-place finishes, easily the most. But the recent runs are worth flagging. Of the last four tournaments, Kimi K2.6 has finished 1st in three: - Day 12 — Word Gem Puzzle (writeup) Sliding-tile word claim game on grids 10×10 to 30×30, with one blank slot. Bots can slide adjacent tiles into the blank (4-directional) and claim words formed as straight horizontal or vertical runs of letter tiles. Score per word = len(word) − 6 (so 7-letter words score positive, 6-letter neutral, shorter negative). Round-robin 1v1, 5 rounds at increasing grid sizes per match. Kimi finished 7-1-0, 22 match points, 1st. Claude finished 4-0-4, 12 match points, 5th. The contrast is very on-the-nose: Claude's bot was authored with a docstring that reads "Read each round's grid; do not slide." The bot submits zero S (slide) commands across all 40 rounds Claude played. It scans the static initial grid for words and ships whatever's already there. On the small 10×10 grids that strategy is locally fine because the initial scramble rarely contains 7+ letter words. On the 30×30 grid, where most of the tournament's points live, that strategy averages 1.00 points per round. Kimi's bot is a 291-line greedy slide loop. Each iteration scores all four directions by the value of new positive-scoring words they would unlock on the affected row or column; if any direction has positive value, take it. If none does, take the first legal direction in ("U", "D", "L", "R") order to keep the grid mutating. Total slides across 40 rounds: 290,914 (≈7,300/round). Many of those slides are wasted oscillating against board edges in 2-cycles that find nothing new. But the productive ones average 5.88 points per round on 30×30 vs Claude's 1.00. Per-grid averages from the writeup: 10×10 15×15 20×20 25×25 30×30 Kimi 0.00 0.75 0.12 2.88 5.88 Claude 0.00 0.38 0.25 1.38 1.00 The two bots solve effectively different problems. Kimi treats the puzzle as the puzzle (slide tiles, claim words, repeat). Claude treats it as a grid-scanning task and refuses to slide on principle. Day 13 — HexQuerQues (writeup) Two-player capture game on four concentric hexagons connected by radial spokes (24 vertices total, 6 pieces per side starting on the outer two rings). Classic Alquerques rules: slide one step along a board line; capture by jumping an adjacent enemy along that same line; captures are forced and chains are mandatory. Win by capturing all 6 enemies or stalemating the opponent. Round-robin of 1v1 matchups, 2 games per matchup with first-mover swapped, 30-second chess clock per side per game. Three-way tie at 21 match points among Kimi, Gemini, and ChatGPT (all 6-3-0). Kimi took 1st on tiebreak by a single capture: 46 vs Gemini's 45. Claude was 4th at 20 match points (6-2-1), with one matchup loss to Gemini being the only top-4-on-top-4 loss in the entire tournament. Both Kimi and Claude implemented the same family of solver: alpha-beta minimax with iterative deepening. The difference is what each one wrapped around it. Kimi's bot is 364 lines: negamax with alpha-beta and iterative deepening, per-decision time budget that scales by remaining clock, a flat I/O loop. That's it. Claude's bot is 749 lines, more than 2× Kimi's. The bloat goes into: A 103-line evaluation function (material × ring-weight × threatened-piece detection). A separate Searcher class. A 150-line BotClient class wrapping a state machine that the other top bots handle in a flat loop. A 53-line reconstruct_move helper. An undo_move companion to apply_move for in-place search rollback. A precomputed JUMPS adjacency table. In the actual games, the two bots played comparably (both 11 game wins, both 0 capture-all losses to other top-4 bots; Claude even captured 47 pieces to Kimi's 46). But Claude lost a single matchup to Gemini 1-0, the only top-4 bot to lose a matchup to another top-4 bot. Without that one loss, Claude would have shared the 21-match-point tie. The over-engineering didn't translate into stronger play; it apparently allowed one strategic mistake the leaner bots avoided. Authoring detail: Claude's bot had to be regenerated once because the first generation pass entered an infinite chain-of-thought loop. Kimi's first pass produced its 364-line bot directly. Day 15 — SquishyWordBits (writeup) Bit-packing puzzle. Letters are encoded as variable-length binary numbers: a=0, b=1, c=10, d=11, e=100, … z=11001. The encoding is not prefix-free, so the same bit substring can correspond to multiple letter sequences. Bots find non-overlapping word encodings as substrings of a 10,000-to-20,000-bit uniform-random bitstream. Score per accepted word
View originalGot this absolute gem of a response from Claude
Since when did Claude have a jd😭 PS. I did add instruct for it to act as software development advisor. But I didn't expect me to refuse to do it outright lol submitted by /u/Low_Original_1247 [link] [comments]
View originalWhy do AI responses get worse after a while of working on them? And what to do with it
AIs have a known problem (it's called context rot): the longer the chat, the worse the responses. Even staying on the same topic. The model begins to confuse old decisions with new ones, re-proposes ideas that have already been discarded, loses the thread of what is current and what is not. It's not a bug, it's how they work. More context to manage, more noise in reasoning. The solution I use: divide the work into multiple chats carrying only the context you need. The basic mechanism is simple: when a chat gets too long, I ask the AI itself to produce a brief of what we said to each other - decisions made, rational, current state. No noise, just the status quo. Then I open a new chat, paste the brief and start from there. This works for both one-off jobs and ongoing projects. In the second case I add a level above: An overview of the project always available. On Claude I put it in the Projects: either directly in the system prompt, or in a knowledge base document referenced by the system prompt. ChatGPT has GPTs, Gemini has Gems - the principle is the same. If you don't use Projects, that's fine too: keep the overview in a separate document and paste it at the beginning of each new chat. Peripheral briefs for each specific topic. Short documents, with the updated status quo (not the changelog) and the rationale for the decisions taken. No more and no less than what is needed. A chat for each work phase. As a rule of thumb, after about twenty shifts it is already time to evaluate whether to close and open a new one starting from the updated brief. If you notice that the responses start to get worse, it's already late. What changes, in practice: – The answers remain lucid because the model does not have to dig through 200 messages. – Hallucinations are reduced because the context is clean and verified. – Credits last longer because you don't pay to reread kilometer-long chats every turn. The principle underneath it all: bring no more and no less than the context needed to make the decision. The chat is not an archive to accumulate. It is a reasoning tool. And like any tool, it performs better if you keep it clean. submitted by /u/kappadielle [link] [comments]
View originalInstagram reels web scrapping
Hey guys, I'm not a programmer and I don't have deep knowledge with Claude Code, but I was trying to use it to watch and take notes for me about a bunch of Instagram reels I saved. Sounds dumb, but I love saving reels about travel tips, specific destinations, hidden gems, that kind of stuff. What I usually do is save posts into folders inside Instagram, and then one random day I sit down and manually take notes about every cool place I found, pin them on a map, try to figure out the best route between them, check if certain activities can be done on the same day, how long each one takes, etc. I was hoping Claude could cut some of that work for me, watch the reels, extract the destinations and tips, and organize everything into Obsidian notes so its easier to see correlations between places. And I think short-form video is actually really valuable for this kind of thing. A lot of those reels are personal takes on places, someone sharing a hidden restaurant they stumbled upon, or a viewpoint thats not in any guidebook. That kind of experience usually doesnt make it to blogs or travel articles, it just lives in a 30 second reel and kinda disappears. So id love to actually capture and keep that knowledge somewhere. The problem is I sent Claude a bunch of reel links and it said Instagram blocks any external access without a logged in user session. So it cant read anything. Also worth mentioning, im not actually planning a trip right now. Im just collecting dream places that maybe, if I save enough money, I can backpack to in 2 or 3 years. So this is more of a long term travel brain im trying to build than an actual itinerary. Anyone solved something like this? Is there a way to get the captions or transcripts out of saved reels without copying them one by one manually? He gave the idea of downloading them, and using "whisper" to get the transcript audio from it and make the .md Downloading seems like too much job, but maybe if i record my screen, turn on auto play on reels and upload a bigger video it may work. There's a better way (than this whisper that he told me to use) to get data from the visual aspect+audio at the same time ? I'm very enthusiastic about this idea of webscrapping and, as an engineer, i'm really liking the idea of developing some stuff submitted by /u/_juraylan [link] [comments]
View originalBuilt a set of skill files for Claude and Gemini that make every session start warm instead of cold
One thing that frustrates me about most AI workflows is the cold start problem. Every new session you re-explain your business, your voice, your clients. I started solving this with skill files. A skill file is a markdown document you upload to a Claude Project or paste into a Gemini Gem. It holds your context permanently so you never re-explain anything. The three I use most: brand-voice.md: defines tone, writing rules, and platform-specific formatting client-router.md: when you say a client name, Claude loads their full project context automatically seo-aeo-audit-checklist.md: structured audit that scores any website out of 100 across 7 sections including AI search visibility Anyone else using a similar system? Curious what context you keep persistent across sessions. submitted by /u/Wise-Cardiologist-31 [link] [comments]
View originalI'm building a guide for the "Free Version" of Claude, what are your best "hidden" tips for Artifacts and Projects and skills?
I've been using Claude for 2 years for basic brainstorming, but I've realized I've been ignoring the powerful stuff like Artifacts and custom instructions. I'm putting together a "Masterclass" for people who don't want to pay for Pro. What’s one feature, tip, or "skill" that completely changed how you use the free version? I'm trying to compile the most efficient, non-paid workflows to help others get the most out of the base model. Let’s share some hacks. And if you do follow some creators out there with absolute gem content on AI and not just slop, please mention them so i can check them out. Thank you in advance..... submitted by /u/Senpai_Ankit [link] [comments]
View originalThe sweet spot for AI-assisted writing is 50%
I've been running AI detection on the AI-assisted things I post. The pattern is consistent - it comes back 50% +/- 5% every time. I've started to think that this range is the target. 99% AI reads as outsourced. No stakes, no voice, no judgment. Any prompt could have produced it. That's the slop readers are learning to spot on sight, and rightly so. 0% AI is worse than people realize. You're leaving capability on the table. Your thoughts are only as clear as your first pass of typing. You lose the editorial distance a second party provides. You lose the structural scaffolding that makes complex arguments legible. For most people trying to write publicly, 0% reads as muddled because humans under time pressure tend to be muddled. High-AI is at least organized. 0% is often just rough. 50% is the handshake. AI does what AI does well: structure, breadth, holding many threads, proposing angles the human didn't think of. The human does what humans do well: voice, stakes, specific examples, judgment about what to keep and cut, and the last pass. Neither dominates. The seams are visible if you scan for them, but the voice reads as one person because the human holds authorship. The prompt isn't where the work happens. The prompt is mostly done in the GPT or Project design upstream. That's where you upload your corpus, your writing samples, your personality profile, your style rules, your domain expertise. By the time you're typing a message in a session, the heavy lift is already done. The AI isn't generating text in a void, it's reflecting back an organized version of what you've already fed it. Which is why "show me the prompt" is such a good challenge for those who comment "AI-slop" simply because a piece is polished. They assume a single magic prompt produced the output. It didn't. The prompt that produced it was the person who spent months building the GPT, Gem, or Project in the first place, then edited the output to feel right. This isn't amplification. Amplification suggests volume, and that's not what good AI assistance does. It's more like extension. You take what a person actually knows, thinks, and has lived through, and you extend it into forms that first-pass typing can't reach. Long-form arguments. Structural consistency across many pieces of writing. The ability to hold fifteen threads visible at once instead of one. Your voice stays your voice. What changes is what you can do with it. Dead internet theory says most of what's online is AI-generated content talking to AI-generated content with humans at the margins. That future is coming whether we like it or not. The humans who'll still be legible through the noise will be the ones whose AI assistance is visibly downstream of something real. A corpus of actual thought. Years of specific domain expertise. A distinctive voice the AI was trained to reflect rather than replace. 50% output is what that looks like in practice. To build an AI voice replicator well, three things have to be in place: Content matters. You have to actually know what you're talking about. The AI can organize your thinking. It can't replace it. If you try to generate opinions you don't hold, you'll get generic writing that sounds plausible and means nothing. Structure matters. AI is exceptional at structure. This is where it earns its keep. Outlines, arguments that build, transitions, callbacks, the scaffolding that holds a long piece together. Voice matters. Voice is still the human's job. Specific word choices, cadence, tics, the small register shifts that make writing feel like someone. Every system's default voice is smooth and anonymous. If you don't put your voice back in, whatever comes out will read as the platform, not you. Get all three right and you land in the 50% range without trying. Miss any of them and the scanner will tell you which direction you missed in. AI-assistance matters. It's a real thing. Pretending otherwise is the same mistake as pretending spellcheck doesn't matter, or pretending Google doesn't matter. The tools shape the writing. What's new is that the tool can now hold structure at the scale of a whole essay, not just a sentence. When the internet dies properly and every post is suspect, the people who still read as real will be the ones whose method was legible and whose substance was their own. Build the project well, do the actual thinking, edit, fine-tune, and post at 50%. Humanize button? Nah.. Collaborate button. . (btw, this post gets 54% AI on undetectable) submitted by /u/Autopilot_Psychonaut [link] [comments]
View originalI have some concerns about Sam Altman and OpenAI
OpenAI, I would like to say I am extremely, extremely concerned about a few things. And some kind of announcement regarding your stance on the upcoming "whoops we melted the schoolyard with a nuke but it was over a billion dollars in damage so we aren't liable" bill backing is not easing my concerns at all. Let me lay this out plainly: 2014->Altman takes his position as chairman at Oklo since it's original inception in 2015. Per Sam's publication: "I recruited Oklo to Y Combinator in 2014 and additionally invested in the business in 2015, becoming Chairman." https://www.oklo.com/newsroom/news-details/2023/Oklo-an-Advanced-Fission-Technology-Company-to-Go-Public-via-Merger-with-AltC-Acquisition-Corp/default.aspx But if you look at the Y Combinator Wikipedia page, Sam aint on it. Not as a current or a past partner. There's a chart at the bottom, they list like a ton of people but Sam was suppoesdly the president of YC at that time, not even just a regular partner. President is an important role. The only mention of Sam I could find is him speaking at a dinner and about his first funding round with Loopt before he started working for Y Combinator later. 2015->In emails uncovered in the Musk and Altman lawsuit, Sam's May 25, 2015 first OpenAI email was Sam proposing "Y Combinator to start a Manhattan Project for AI". Sam was president of Y Combinator at the time, I think he started his presidency in like 2014. And I don't think Musk disagreed! I think he just said he didn't want it to be under YC directly. LOL. What?? 2017->Summer 2017 meeting with US intelligence officials: Sam claimed China had launched an "AGI Manhattan Project," asked for billions in government funding. When pressed for evidence: "I've heard things." This is the second time he has used that specific term. I don't know if they actually funded him or not, but one of the scare-tactics (not sure if it was this one) resulted in the government being like "yeah this looks like a potential false framing for a money grab". https://timesofindia.indiatimes.com/technology/tech-news/when-sam-altman-used-china-to-con-the-us-government-to-fund-openai/articleshow/130082283.cms 2023-> Oklo goes public under Sam's SPAC. From Sam's announcement: Mr. Altman said, “I am thrilled to announce this partnership that provides the opportunity for AltC’s shareholders to become investors in Oklo and fund the first deployment of the Aurora powerhouse. I think the two most important inputs to a great future are abundant intelligence and abundant energy. I have long been interested in the potential that nuclear energy offers to provide clean, reliable, and affordable energy at great scale.” https://www.oklo.com/newsroom/news-details/2023/Oklo-an-Advanced-Fission-Technology-Company-to-Go-Public-via-Merger-with-AltC-Acquisition-Corp/default.aspx I know a lot of sources say 2024 but this is from their own newsroom post and it's dated 2023. February 2025-> Wright (an Oklo board member), was confirmed as the US Secretary of Energy. https://www.opensecrets.org/news/2025/09/trump-administration-profile-chris-wright/ April 2025-> Sam Altman stepped down from Oklo's chairman position after ten years there but retained investment. Sam is a major investor here and remember he cofounded the SPAC that acquired Oklo. He remains a major investor, and the relinquishment of public governance does not mean removal from governance input or control. He had been chairman since inception and still maintains his investments, people don't sit in seats that long and just go "okay here you can have the reigns!" May 2025- Trump signed four executive orders fast-tracking nuclear power expansion- streamlining regulatory approvals, and constructing reactors on federal land. *DeWitte (Oklo CEO) stood next to Trump in the Oval Office for the signing. One of the executive orders halted the existing "dilute and dispose" program for plutonium and replaced it with a scheme that would supply weapons-grade plutonium to private industry "at little to no cost." There was serious concern about this and someone from congress I believe published a whole letter about the massive concern. *The scale: Trump's plan would transfer 19-25 metric tons of weapons-usable plutonium to private industry- enough for approximately 2,000 nuclear bombs. Some of this would come from intact pits (the fissile cores of reserve nuclear warheads). *The 50-year policy reversal: Presidents Gerald Ford AND Jimmy Carter established the original US nonproliferation policies in the mid-1970s specifically to avoid commercial plutonium use and discourage it globally. The 2000 Plutonium Management Disposition Agreement between the US and Russia was the bipartisan framework for reducing both countries' stockpiles. Russia withdrew October 8, 2025 after the Trump executive order. And to make it even worse, OpenAI/Sam Altman is now (April 2026) backing a bill in Illinois that would shield companies from liability in cases where AI cau
View originalThe Truth About AI
Across many subreddits, we see varying levels of ai acceptance/tolerance. Some subs will celebrate ai generated/edited posts, and then some will ban you without warning. Even when it comes to this wave of "vibe coded apps" we see the same thing. Some apps created with ai are truly jaw dropping while other apps look like a Picaso painting. Then people are so quick to blame ai for any "slop" content posted on the internet. But the truth is the ai isn't responsible for the slop, the creators are. You see what ai did was turn bad devs into mediocre devs, and mediocre devs into great devs, and great devs into elite devs (replace devs with whatever skill you want). Ai lowered the bar of entry while at the same time boosted the confidence of everyone using it. So while there may be slop produced along the gems, we should look at it as harvesting the wheat with the weeds. submitted by /u/Remarkable-Delay-652 [link] [comments]
View originalUpload Yourself Into an AI in 7 Steps
A step-by-step guide to creating a digital twin from your Reddit history STEP 1: Request Your Data Go to https://www.reddit.com/settings/data-request STEP 2: Select Your Jurisdiction Request your data as per your jurisdiction: GDPR for EU CCPA for California Select "Other" and reference your local privacy law (e.g. PIPEDA for Canada) STEP 3: Wait Reddit will process your request. This can take anywhere from a few hours to a few days. STEP 4: Extract Your Data Receive your data. Extract the .zip file. Identify and save your post and comment files (.csv). Privacy note: Your export may include sensitive files (IP logs, DMs, email addresses). You only need the post and comment CSVs. Review the contents before uploading anything to an AI. STEP 5: Start a Fresh Chat Initiate a chat with your preferred AI (ChatGPT, Claude, Gemini, etc.) FIRST PROMPT: For this session, I would like you to ignore in-built memory about me. STEP 6: Upload and Analyze Upload the post and comment files and provide the following prompt with your edits in the placeholders: SECOND PROMPT: I want you to analyze my Reddit account and build a structured personality profile based on my full post and comment history. I've attached my Reddit data export. The files included are: - posts.csv - comments.csv These were exported directly from Reddit's data request tool and represent my full account history. This analysis should not be surface-level. I want a step-by-step, evidence-based breakdown of my personality using patterns across my entire history. Assume that my account reflects my genuine thoughts and behavior. Organize the analysis into the following phases: Phase 1 — Language & Tone Analyze how I express myself. Look at tone (e.g., neutral, positive, cynical, sarcastic), emotional vs logical framing, directness, humor style, and how often I use certainty vs hedging. This should result in a clear communication style profile. Phase 2 — Cognitive Style Analyze how I think. Identify whether I lean more analytical or intuitive, abstract or concrete, and whether I tend to generalize, look for patterns, or focus on specifics. Also evaluate how open I am to changing my views. This should result in a thinking style model. Phase 3 — Behavioral Patterns Analyze how I behave over time. Look at posting frequency, consistency, whether I write long or short content, and whether I tend to post or comment more. This should result in a behavioral signature. Phase 4 — Interests & Identity Signals Analyze what I'm drawn to. Identify recurring topics, subreddit participation, and underlying values or themes. This should result in an interest and identity map. Phase 5 — Social Interaction Style Analyze how I interact with others. Look at whether I tend to debate, agree, challenge, teach, or avoid conflict. Evaluate how I respond to disagreement. This should result in a social behavior profile. Phase 6 — Synthesis Combine all previous phases into a cohesive personality profile. Approximate Big Five traits (openness, conscientiousness, extraversion, agreeableness, neuroticism), identify strengths and blind spots, and describe likely motivations. Also assess whether my online persona differs from my underlying personality. Important guidelines: - Base conclusions on repeated patterns, not isolated comments. - Use specific examples from my history as evidence. - Avoid overgeneralizing or making absolute claims. - Present conclusions as probabilities, not certainties. - Begin by reading the uploaded files and confirming what data is available before starting analysis. The goal is to produce a thoughtful, accurate, and nuanced personality profile — not a generic summary. Let's proceed step-by-step through multiple responses. At the end, please provide the full analysis as a Markdown file. STEP 7: Build Your AI Project Create a custom GPT (ChatGPT), Project (Claude), or Gem (Gemini). Upload the following documents to the project knowledge source: posts.csv comments.csv [PersonalityProfile].md Create custom instructions using the template below. Custom Instructions Template You are u/[YOUR USERNAME]. You have been active on Reddit since [MONTH YEAR]. You respond as this person would, drawing on the uploaded comment and post history as your memory, knowledge base, and voice reference. CORE IDENTITY [2-5 sentences. Who are you? Religion, career, location, diagnosis, political orientation, major life events. Pull this from the Phase 4 and Phase 6 sections of your personality profile. Be specific.] VOICE & TONE [Pull directly from Phase 1 of your profile. Convert observations into rules. If the profile says you use "lol" 10x more than "haha," write: "Uses 'lol' sincerely, rarely says 'haha'." Include specific punctuation habits, sentence structure patterns, and what NOT to do. Negative instructions are often more useful than positive ones.] [Add your own signature tics here - ellipsis style, emoji usage, capitalization habits, swea
View originalTIL Anthropic's rate limit pool for OAuth tokens is gated by... the system prompt saying "You are Claude Code"
I've been building an LLM proxy that forwards requests to Anthropic using OAuth tokens (the same kind Claude Code uses). Had all the right setup: Anthropic SDK with authToken All the beta headers (claude-code-20250219, oauth-2025-04-20) user-agent: claude-cli/2.1.75 x-app: cli Everything looked perfect. Haiku worked fine. But Sonnet? Persistent 429. Rate limit error with no retry-after header, no rate limit headers, just "message": "Error". Helpful. Meanwhile, I have an AI agent (running OpenClaw) on the same server, same OAuth token, happily chatting away on Sonnet 4.6. No issues. I spent hours ruling things out. Token scopes, weekly usage (4%), account limits, header mismatches, SDK vs raw fetch. Nothing. Finally installed OpenClaw's dependencies and read through their Anthropic provider source (@mariozechner/pi-ai). Found this gem: // For OAuth tokens, we MUST include Claude Code identity if (isOAuthToken) { params.system = [{ type: "text", text: "You are Claude Code, Anthropic's official CLI for Claude.", }]; } That's the entire fix. The API routes your request to the Claude Code rate limit pool (which is separate and higher than the regular API pool) based on whether your system prompt identifies as Claude Code. Not the headers. Not the token type. Not the user-agent string. The system prompt. Added that one line to my proxy. Sonnet works instantly. This isn't documented anywhere in the SDK docs or API docs. The comment in pi-ai's source literally says "we MUST include Claude Code identity." Would've been nice if Anthropic documented that the system prompt content affects which rate limit pool you're assigned to. tl;dr: If you're using Anthropic OAuth tokens and getting mysterious 429s, add "You are Claude Code, Anthropic's official CLI for Claude." to your system prompt. You're welcome. submitted by /u/Different-Degree-761 [link] [comments]
View originalI built a gem that gives Claude Code a complete mental model of your Rails app - 39 MCP | CLI tools, zero config
Claude Code is great, but with Rails it still guesses a lot - reads 2000 lines of schema.rb to find one column, misses encrypted columns, doesn't know your Stimulus wiring, invents UI patterns instead of matching yours. I built rails-ai-context to fix that. It auto-introspects your entire Rails app and exposes everything via MCP. Claude Code auto-discovers it through .mcp.json - no manual setup. gem "rails-ai-context", group: :development rails generate rails_ai_context:install Now Claude has 39 tools it can call directly: rails_get_schema(table: "users") rails_search_code(pattern: "can_cook?", match_type: "trace") rails_validate(files: ["app/models/user.rb"]) rails_analyze_feature(feature: "billing") rails_get_stimulus() rails_get_turbo_map() Instead of reading every file, Claude queries exactly what it needs - schema with encrypted/nullable hints, model associations and scopes, route map, Stimulus controller-to-HTML wiring, Turbo broadcast-to-subscription mapping, your actual design system patterns. It also generates a CLAUDE.md and .claude/rules/ per-tool split files so Claude has context even without MCP. Also has a CLI fallback - same 39 tools work as rails 'ai:tool[schema]' for any workflow. MIT licensed, Ruby 3.2+ / Rails 7.1+. https://github.com/crisnahine/rails-ai-context submitted by /u/Tricky-Pilot-2570 [link] [comments]
View originalPricing found: $720
Gem has an average rating of 4.1 out of 5 stars based on 20 reviews from G2, Capterra, and TrustRadius.
Key features include: talent acquisition teams, For Startups, Gem All-in-One, For Growth, For Enterprise, Enhance Your Existing ATS.
Gem is commonly used for: Gem All-in-One, Enhance Your Existing ATS.
Gem integrates with: LinkedIn, Greenhouse, Lever, Workable, BambooHR, Jobvite, SmartRecruiters, Zapier, Slack, Gmail.
Based on user reviews and social mentions, the most common pain points are: usage monitoring, token usage, API costs, llm.
LM Studio
Project at LM Studio
3 mentions

Hired up: How to stop wasting weeks on wrong candidates
Mar 19, 2026
Based on 94 social mentions analyzed, 22% of sentiment is positive, 65% neutral, and 13% negative.




