Your daily dose of AI research from AK
Papers with Code receives praise for its extensive catalog of machine learning research papers coupled with code implementations, making it a valuable resource for both learning and project development. Users appreciate the integration of code, which aids in practical understanding and application of theoretical work. However, a few users note that some papers lack comprehensive code examples or have discrepancies between reported and reproduced results. While it is generally seen as a free and indispensable tool for researchers and developers, there are mentions of resource constraints potentially limiting its expansiveness.
Mentions (30d)
42
15 this week
Reviews
0
Platforms
2
Sentiment
19%
23 positive

Papers with Code receives praise for its extensive catalog of machine learning research papers coupled with code implementations, making it a valuable resource for both learning and project development. Users appreciate the integration of code, which aids in practical understanding and application of theoretical work. However, a few users note that some papers lack comprehensive code examples or have discrepancies between reported and reproduced results. While it is generally seen as a free and indispensable tool for researchers and developers, there are mentions of resource constraints potentially limiting its expansiveness.
Features
Use Cases
Industry
research
Employees
3
5,748
GitHub followers
13
GitHub repos
2
npm packages
4
HuggingFace models
No more file upload limits on AI models!
Getting annoyed of always hitting the ChatGPT upload limit, uploading large documents in pieces, or any similar hassle, I decided to create a little thing for it. DocShareAI. The idea here is to upload/paste a document and get an AI-readable link back which you then send to ChatGPT, Gemini, Grok, and whichever model on which you have hit your file upload limit. • I created it out of frustration due to: • Copying long things messed up formatting too often. • Quickly hit the upload limit while using AI. • Not all webpages/documents are readable by AI. • Splitting code or log snippets in multiple chunks. Instead of pasting the 15th part yourself, you give the AI one link containing all of it. Can work with: • Images, essays and research papers. • Long code snippets. • Log debugging. • PDFs. • Documents. No signup or any other process required. Website: link in comments We will continue improving on it and suggestions are really helpful there. submitted by /u/building_stuff86 [link] [comments]
View originalWhat is considered ‘normal’
I currently have a lot of free time and thought ‘I’ve got some projects I’ve been thinking about, fuck it I’ll buy a max subscription and just crank on them’, see what happens. Holy. fucking. shit For context I’ve used ai to help me write etc but never for full coding workflows etc. In the last week I have managed to build 1 full website (weather forecast aggregator for alpinists and skiers and others who require accurate detailed weather forecasting and avalanche conditions) and then started a research project which then immediately led into building out a trading algorithm - 12,000 lines of code, full infra, backtesting engine etc etc - currently in paper trading. With the algo especially I’m sure there are going to be some issues since I don’t have the kind of expertise to check the infra etc however it works, that’s the main thing. Is this normal productivity? Or have I just hit a bit of an anomaly? I’ve honestly been blown away by the ability of Claude. submitted by /u/DiscombobulatedElk58 [link] [comments]
View originalDeep researched research backed flashcard rules for Anki and gave it to Claude. I find it helpful.
I make a lot of Anki cards from PDFs, papers, and YouTube transcripts. Got tired of repeating the same rules to Claude every single time. Deep researched the recommended rules backed by research etc. Has been working well for me (ofc sometimes misses some things that I would like to have in cards, or is not compact enough at times but is still a massive help to me) Wrote it all down once and dumped it in ~/.claude/rules/. Now Claude follows the rules every time I ask it to make cards. Four files: general, for default content math, with three custom note types I built so cards hide the technique on the front (forces strategy selection during review instead of pattern matching the problem text) coding, biased toward pattern recognition over framework API memorization DSA (data structures and algorithms), focused on signal-to-pattern recognition Repo: https://github.com/VinayakHyde/claude-anki-flashcard-rules Just markdown files. Copy into ~/.claude/rules/, reference the relevant one when prompting Claude. Needs Anki running with AnkiConnect plus an MCP bridge(https://github.com/nailuoGG/anki-mcp-server) so Claude can talk to it. Hope this helps! (post was made with AI, edited by me cuz I'm lazy) submitted by /u/Top-Specialist-4314 [link] [comments]
View originalBanned by OpenAI after reporting a live credential hijack. They admitted in writing my account was broken. Here are 7 months of forensic receipts and 20+ cases.
Drive Link for Zipped Proof I am a developer and paying long term subscriber to ChatGPT since January 2025. I build complex local first sovereign systems. My workflows are incredibly context heavy with large files spanning code, research reports, and other analysis. I do not, or rather did not as the platform has been non functional since November 2025 meanwhile customer support is auto closing tickets, admitting I am having platform issues. I do not use this platform for casual queries, as a solo developer with no formal "team" chatgpt was one of my reliable co collaboration hubs to help ensure I am maintaining proper development of said complex systems. I feed it massive codebases for systems analysis and obtaining new insights I may personally have missed. My manual code uploads and token inputs routinely exceed the model's output volume by a massive margin. I do not abuse this platform. It is actually impossible as the very features advertised under the paid subscription do not work. I am exactly the type of user this platform was built for, and I have been a continuous, paying ChatGPT Plus subscriber since January 2025. Since October 2025, my workspace has been systematically breaking and beginning November 2025 total workspace degredation. This was not an occasional glitch. Persistent memory modules stopped updating. Custom instructions were ignored by the models. Project files failed to load. Custom instructions, personalization features, connector abilities, file tool, even projects do not work. It started as a continuous degradation until total failure. OpenAI customer service even admitted as such and yet months later I've talked to nothing but bots, not only LLMs as customer service but even instances of falsely identifying as true human support. It was a state of rolling degradation across the entire paid tier, month after month. Meanwhile OpenAI freely has enhanced for businesses and enterprise tiers. I have not just rapid complained to standard support. I ran and obtained cross platform diagnostics, failure logs. I even documented and told oai customer support the exact replication steps only to be met with acknowledgement of degredation with no resolution. I handed OpenAI support a completely packaged technical breakdown of their failing infrastructure across 20 separate support tickets over a 7 month period. I did their QA work for free. And I have the receipts to prove it. I am attaching the screenshots and the exact email files to this post. In Case 06830839, OpenAI Support explicitly put this in writing: "We acknowledge that you have been experiencing persistent technical issues affecting several features of your ChatGPT subscription, including tools, memory functions, personalization settings, connectors, and project files... We also understand your concern that communication on the case stopped after you provided detailed evidence..." Read that again. They acknowledged in writing that my account was fundamentally broken. They acknowledged that their own team ghosted me after I handed them the diagnostic proof. Yet they kept charging my card every single month for a product they knew was failing. The Hijack Escalation: Two days ago, the situation escalated from a broken product to a severe security incident. I was monitoring my environment and watched my Codex rate limits drop in 10 percent chunks across 2 seperate sessions on a fresh boot of the desktop app. This happened twice inside a 10 minute window. I had zero active sessions running. There was zero usage on my end. My account token was being actively drained by an unauthorized third party exploit. I immediately opened an emergency unauthorized activity report under Case 09113391 to notify them of the hack. Their response was to totally reframe this problem as disputing fraudulent activity trying to do damage control of the situation and altering the record. The Reframe Attempts: Instead of investigating the breach, OpenAI support deliberately twisted the record. They not only deliberately reframed my security report as an "appeal for fraud." They manipulated the ticket classification to make it look like I had been flagged for fraud and was begging for an appeal, rather than a developer reporting a live exploit on their infrastructure. They ignored the active threat their own platform was exposing. They did not lock the token. They did not roll my API keys. They did absolutely nothing to secure a compromised paying user other than shift the blame. Fast forward to this morning, their automated Trust and Safety system swept the high volume traffic from the attacker, scored it as a malicious exploit originating from my account, and deactivated/banned me for "Cyber Abuse." All the while actively preventing chatgpt models from helping me try to disgnose and trace the infiltration. They locked the doors and blamed the homeowner for the break in. When I immediately emailed and pushed back (due to their monthly record of closi
View originalPapersWithCode new features - week 1 [P]
Hi, Niels here from the open-source team at Hugging Face. It's been one week since I launched paperswithcode.co, a revival of the website we all loved. It allows us to keep track of the state-of-the-art (SOTA) across various domains of AI, from agents to computer vision and time-series forecasting. The reception has been great, and I'm excited to extend this over the next few months. This week, I've added the following features: - Support for multiple metrics for a given benchmark: leaderboards now support multiple metrics, see e.g., the Open ASR Leaderboard for automatic speech recognition, which supports both Word Error Rate (WER) and the Inverse Real-Time Factor (RTFx) metrics, or the Object Detection leaderboard, which now also reports frames-per-second (FPS) besides mean average precision (mAP) on COCO. https://preview.redd.it/owlxn0b5u23h1.png?width=2878&format=png&auto=webp&s=1dff2f8feab4f160f77c97ceeb5d90e82382e63c - Support for external papers: We do support submitting papers beyond Arxiv, such as a Github repo, a blog post, BiorXiv, and more. You can submit a paper at paperswithcode.co/submit. AI will automatically enrich it with task and method tags, the GitHub repo, evals, and more. See e.g. DeepSeek-v4 below, which is not on Arxiv: https://preview.redd.it/uogbt0fjw23h1.png?width=2928&format=png&auto=webp&s=8b81e48af69b8935ddeb569d882d866b3e9ba216 - Support for paper lineage: whenever a paper has a follow-up or predecessor, this will be displayed with a small banner above the abstract. See e.g. Mamba-3, DINOv2 and GLM-4.5. https://preview.redd.it/f6vgtd1du23h1.png?width=2228&format=png&auto=webp&s=f8627f7669405f1766eecfd3322e925e15b4806d - New methods: support for new methods based on popularity, including Gated DeltaNet, Kimi Delta Attention, Mamba-2, and more. Each method also lists all papers that cite it. Find all supported methods here. https://preview.redd.it/6pzagifvu23h1.png?width=2984&format=png&auto=webp&s=400efdc9677d1fbd369eedf684e622dd8c807973 - Support for screenshotting a leaderboard for easy sharing on social media: each benchmark now includes a "copy image" button both on the scatter plot and table, which can be shared on social media. Try it on ClawEval, for example. https://preview.redd.it/w7y7t7xnw23h1.png?width=2950&format=png&auto=webp&s=cb70ad91c6ba075e49b743d6e34f157d22266f04 - Added many more evals: we are adding evals gradually, starting with all models supported in the Transformers library. So far, we have about 3k evals! Find them at the bottom of each paper page, e.g. Qwen 3.6. https://preview.redd.it/zao056s9x23h1.png?width=2218&format=png&auto=webp&s=540d87f473be05cb6f9c0aca88afa74fd4373e15 Happy to hear more feature requests and feedback! I will also launch a channel on the Hugging Face Discord server for easier communication. You can also chime in on the GitHub thread here. Cheers, Niels submitted by /u/NielsRogge [link] [comments]
View originalI made a Claude Code plugin that draws matplotlib figures in that soft-pastel "alignment research blog" style
You know the look — the figures in Anthropic's research posts. Bold sans-serif titles, scatter points under a smoothed trend line with a shaded band, those bars with the slightly rounded tops, little ↓better badges in the corner. I kept wanting my own plots to look like that and kept rebuilding the same matplotlib boilerplate, so I packaged it into a Claude Code skill. It's called nice-figures. Once it's installed, you just describe the plot you want and Claude picks it up automatically: "training-curve plot of these RL scores with a smoothed trend and shaded band, research-blog style" "grouped bar chart comparing three models across four evals, with the rounded bar tops" Bring your own CSV/arrays and it maps them onto the closest chart; describe a figure with no data and it generates a clearly-marked synthetic placeholder. Under the hood it's one skill plus a small style helper (matplotlib + numpy, no other deps) and 16 chart recipes — training curves, grouped bars, ROC, heatmaps, scaling-law scatter, forest plots, Pareto fronts, etc. White background by default so the output is paper/conference-ready, with an opt-in cream background for the blog look. Install: /plugin marketplace add Mapika/nice-figures /plugin install nice-figures@nice-figures Repo (MIT, example images in the README): https://github.com/Mapika/nice-figures Built it for my own use, figured others might want it. Happy to take feedback or recipe requests. submitted by /u/Mapikaa [link] [comments]
View originalLodestone: A SQLite-backed arXiv research paper retrieval system for Claude Code
(No AI-generated text below) I published a new Claude Code plugin called Lodestone -- it's a SQLlite backed arXiv research paper retrieval system that amplifies the agentic search abilities of Claude Code when grounding plans, implementations etc in state of the art research while remaining very token-sensitive. My bet is that, when seeded, it will always beat Claude Code's web search tools for grounding Claude in the latest research in a domain or cross-domain and not spend a ton of $ for the pleasure. This audience is probably painfully aware of Karpathy's LLM wiki tweet and the industry of projects that's popped up from it; I'll paste an excerpt from the blog below that I think addresses what you all might be thinking: The Approach Karpathy’s proposal made a lot of sense. Let Claude be the curator and librarian of all this research and access it using its bash and file manipulation tools when necessary. This approach spawned a cottage industry of projects where people implemented various takes on this direction. In parallel, researchers like those that created the ARA Compiler have been trying to move research itself into more a structured, agentic form. I liked all of these ideas, but there were three principles I wanted to uphold while building in this space: The system itself needed to be extremely portable. I wanted this system to follow me from computer to computer and be easily backed up. When ingesting documents, I wanted the system to be as deterministic as possible and spend the least amount of tokens. I didn’t want to expend hundreds of thousands of tokens before getting anything useful out of the system. The system needed to be extremely flexible in how Claude could use it and not prescribe a single method for retrieval. I can’t predict all the ways Claude might use this type of system so I wanted to provide multiple pathways into the data. Given these principles, I was immediately drawn to SQLlite as a backing DB. The unmatched ease-of-use combined with a single file made it the obvious option for portability. Claude could potentially create a sprawling file system when maintaining its own knowledge wiki and I didn’t want to have to learn it when backing up or porting my knowledge base. I gave the ARA Compiler a try while in the middle of building Lodestone. I ran it over a standard-sized paper I was interested in; it produced some cool outputs, but spent almost 500k tokens for the pleasure. This was my fear with it and the ecosystem of projects emerging from Karpathy’s ideas: I had to spend a fair bit of money before I even knew if the system was useful. I knew a SQLlite-backed agentic search system needed a form of classic retrieval (keyword or similarity based), but I also am painfully aware of all the limitations and failures of these approaches to RAG. I wanted to combine this retrieval approach with a retrieval approach from the emerging category of vectorless RAG — a taxonomy that Claude can drill into to get its bearings before drilling further. What followed was Lodestone. Check out the blog post (which also has no AI generated text) here: https://medium.com/@pierce-lamb/lodestone-a-sqlite-backed-arxiv-research-paper-retrieval-system-for-claude-code-b77de201f0c8 The repo's README is almost entirely AI-generated, so point your Claude Code cannons at that: https://github.com/piercelamb/lodestone submitted by /u/SnappyAlligator [link] [comments]
View originalGPT-5.2 matches top human reviewers in Nature peer review study
45 scientists spent 469 hours comparing human and AI reviews across 82 papers. AI reviewers held their own against top-rated human reviewers, though with some weaknesses. submitted by /u/Adi4x4 [link] [comments]
View originalI built myself a finite AI news feed which doesn’t undermine AI research
Hello, I built myself a news feed which scores and summarizes research papers along with relevant AI news from Huggjngface, Reddit, hacker news etc. I used Claude code to build the whole thing. I used Gemma to deduplicate, Feed is ranked by engagement × cross-platform presence × recency and summarized by claude I think it will be useful for many. Open to hear your thoughts. hackobar.com submitted by /u/rahu_ [link] [comments]
View originalBuilt an invoice-scanning service for our accounting team in one afternoon with Claude — sharing the architecture in case it helps someone else
Our AR team was hand-keying ~25 invoices a week into a spreadsheet. I had Claude build us a Python service that watches a network folder, extracts invoice data from any PDF dropped in (vendor, dates, totals, line items, addresses), and appends a row to a shared Excel register. Total chat-to-deployed time: about half a day, including all the deploy headaches. The architecture, for anyone who wants to replicate this: Python service on our Windows file server, registered with NSSM. Auto-starts with the host. watchdog library polls the SMB share for new PDFs. Each new file goes through a pipeline. Two-tier extraction: per-vendor regex templates first (free, instant, deterministic), then Azure AI Document Intelligence "prebuilt-invoice" model as a universal fallback. Azure handles OCR for scanned PDFs natively, so the same flow works whether AR drops a digital PDF or our MFP scans one from paper. SQLite on the local disk is the source of truth. The shared .xlsx is a curated view that gets appended to on each batch. Delete the .xlsx and it'll repopulate fresh from the next batch — handy for resetting. Failed extractions go to a Failed\ folder with a sibling .error.txt explaining why. Cost reality check: Azure DI free tier covers 500 pages/month. At our volume (~25 invoices/week, mostly 1-2 pages) that's well under the cap. Paid tier is roughly $0.01–$0.05 per page. Cheap enough that I don't think about it. Gotchas I ran into so others don't have to: Azure returns addresses as structured objects, not strings. If you naively str() them you get the raw Python dict repr in your spreadsheet. Format them manually from street_address / city / state / postal_code. On Windows Server, PowerShell 7's Restart-Service can throw "Cannot open service" against NSSM-wrapped services for no good reason. Use nssm restart instead. Python 3.14 is so new that some package wheels aren't published for it yet. Stick with 3.12 for production. Tracking "what's new this batch" is way simpler than maintaining a watermark in DB. Just snapshot MAX(invoice_id) before and after the batch, and only project that range to the spreadsheet. Things I'd add if/when I have time: vendor templates for our top 5 recurring vendors (cuts Azure cost to zero for those), a daily canary PDF for monitoring, swap the LocalSystem service account for a dedicated low-privilege one. Happy to answer questions about any specific piece. The whole thing is ~1,500 lines of Python plus a deploy script. submitted by /u/Blake_Olson [link] [comments]
View originalTIL you can ship a Claude Code skill inside a GitHub repo so anyone who clones it gets architectural guardrails baked in
I've been building a local AI ops platform and wanted Claude to be able to extend it without ever accidentally touching core files. So I added a .claude/skills/ directory to the repo with a plain Markdown file that gives Claude: - the architecture contract ("every feature is a worker, the core is off-limits") - a decision tree for scaffolding (what files to create, in what order) - hard rules that Claude has to surface as an explicit gap rather than paper over with a silent core edit When anyone opens the repo in Claude Code, the skill loads automatically. Ask it "create a new worker" and it follows the contract without being told any of this upfront. The interesting part: the skill is just Markdown. No Claude-specific syntax. Which means you can copy it into an AGENTS.md for Codex, or paste it into any assistant's system prompt, and it works the same way. If you're building something others will extend with AI assistance, shipping the architectural contract as a skill seems like a cleaner pattern than hoping contributors read the docs. PS: as suggest a reader, if not done automatically, include the main guidelines in the CLAUDE.md such as, when the context get very big, these directive remains effective (it happens the skill get ignored in such conditions Repo if you want to see how the skill is structured: https://github.com/ccascio/BFrost submitted by /u/EmoticonGuess [link] [comments]
View originalBackprop-free Pong: PC + distributional Hebbian plasticity vs. PPO: 57% vs. 59%, ~1500 lines from scratch [P]
Wanted to see how close a fully bio-plausible agent could get to PPO on Pong. Setup Custom Pong environment (pygame, no gym) PPO baseline: paper-faithful, from scratch Hebbian agent: PPO policy replaced with Hebbian value estimation engineered features → 61% BioAgent: Predictive Coding for feature learning + distributional Hebbian plasticity for value (Dabney et al. 2020) → 57% Zero backprop anywhere in the pipeline. Key observations The 2% gap is real but small. The bottleneck wasn't the lack of backprop because it was catastrophic forgetting under non-stationary opponent dynamics during self-play. Distributional value encoding (à la Dabney) helped stability vs. a scalar Hebbian baseline, but not enough to match PPO under self-play. Self-play exposed the plasticity–stability dilemma hard: Hebbian rules that adapt fast forget fast. This is the real wall for bio-plausible RL in non-stationary settings. Not claiming novelty in the architecture as this is a from-scratch exploration of whether bio-plausible rules can handle a real RL task. Short answer: yes, mostly, with one clear failure mode. Code: github.com/nilsleut/Biologically-Plausible-RL-Plays-Pong Happy to answer questions about the PC implementation, the Hebbian value estimator, or the self-play setup. submitted by /u/ConfusionSpiritual19 [link] [comments]
View originalI built ContextAtlas: A new take on context carry over and helps claude pick up new sessions where it left off in scope of your previous design decisions while saving your tokens avoiding rediscovery
When the "Build with Opus 4.7" hackathon was announced, I had been obsessing over the tokenomics of agents and how to make sessions go further without burning context on rediscovery work. We all have probably hit a session limit and wondered how it went so fast. I applied with that thesis, didn't get in, but I built it anyway over the last four weeks. I am proud to share that v1.0 ships today. Note up front: this is specifically a tool for development users. If you're using claude.ai web or Projects, ContextAtlas won't plug in directly. But if Claude Code is your main work flow or you utilize the Anthropic API, this tool was made for you. The pain: Claude Code learns your codebase fresh every session. "Where is OrderProcessor?" triggers a flurry of greps. "What depends on AuthMiddleware?" is another round of file reads. On a mid-sized codebase, an architectural question can burn 40+ tool calls and a lot of tokens before Claude has enough context to reason well. And the architectural rules in your ADRs and design docs? Claude has no path to those, so it confidently suggests changes that break constraints you may have documented elsewhere in your repo. What I built: ContextAtlas is an MCP server that pre-computes a curated atlas of your codebase (symbols, ADR-extracted architectural intent, git history, test coverage) and serves it to Claude Code in one call at query time in a smaller, token saving compact shape via a few lightweight mcp tools. Initial indexing happens once; querying is local and free. Example of what comes back when Claude calls get_symbol_context("OrderProcessor"): SYM OrderProcessor@src/orders/processor.ts:42 class SIG class OrderProcessor extends BaseProcessor INTENT ADR-07 hard "must be idempotent" RATIONALE "All order processing must be safely retryable." REFS 23 [billing:14 admin:9] GIT hot last=2026-03-14 TESTS src/orders/processor.test.ts (+11) Claude sees the idempotency constraint before proposing changes, not after a review catches the violation. https://i.redd.it/0ons3o28t32h1.gif Numbers: 45-72% token reduction on architectural prompts across three benchmark repos (TypeScript, Python, Go), with zero quality regression on measured axes. Full methodology and paired-t confidence intervals in the linked write-up. I wanted measurements, not vibes. Honest limits: single-judge model at v1.0 (cross-vendor panel is post-launch work). Quantitative claims bounded to three benchmark repos. Tie-bucket and trick-bucket prompts routinely show ContextAtlas net-negative; that's reported inline rather than buried. Install (two ways): In Claude Code: /index-atlas and /generate-adrs skills. No API key needed; runs under your subscription. Via CLI: uses Anthropic API for indexing. npm install -g contextatlas contextatlas init && contextatlas index # then add the MCP server entry to your Claude Code config (snippet in the README) Both produce structurally identical atlases. Supported languages at v1.0: TypeScript (tsserver), Python (Pyright), Go (gopls), Ruby (ruby-lsp). Rust, Java, and C# are next on the roadmap; the adapter interface is small enough that they're realistic community contributions. What's next: v1.1 thesis is shaping up around developer onboarding flows and quality-validation work that was deferred from v0.8. And integrating external documentation of your code base into pre-indexing workflow. Full write-up: https://www.contextatlas.io/blog/v1.0.0 Repo: https://github.com/traviswye/ContextAtlas Also launching on DevHunt today: https://devhunt.org/tool/contextatlas; votes are very appreciated if you find ContextAtlas useful or an interesting approach. Built solo, hackathon-shaped scope, not pretending it's a full blown research paper, but did attempt to treat methodology as seriously. Happy to answer anything in the comments. Star the repo if you want to follow along, file an issue if it breaks for you on your codebase, and please be honest; this only gets better with feedback from people running it on real repos. submitted by /u/Kitchen-Leg8500 [link] [comments]
View originalAnthropic just bought the company that generates most production MCP servers
Anthropic acquired Stainless on Monday for a reported $300M+. Most coverage is framing this as a developer tools acquisition. Stainless is best known for generating the official Python and Node SDKs that ship with OpenAI, Google, Meta, Cloudflare, and Anthropic. The SDK story is real. The MCP side is the part that matters here. Stainless was one of the first vendors to extend their compiler to produce MCP servers from the same OpenAPI specs that produce their SDKs. MCP hit ~97M monthly SDK downloads by December 2025 and around 10,000 production servers by early 2026. A lot of that production code was Stainless-generated. Anthropic now owns the dominant MCP server generator. What actually changed hands on Monday: The engineering team. Roughly 40-50 people including founder Alex Rattray, who previously built Stripe's patented SDK generation system. Now reporting to Katelyn Lesse in Anthropic's Platform Engineering org. The technology. The generator, the templates, the language-specific runtimes, the OpenAPI extensions Stainless invented for SDK-specific edge cases. The hosted product is winding down. New signups stopped Monday. New SDK and MCP server generations stopped Monday. Existing customers keep what they've already generated but the pipeline is closed. My read: this is closer to what Google did with Kubernetes than to a normal acquisition. Anthropic created MCP. Anthropic donated MCP to the Linux Foundation last December. Anthropic now owns the dominant implementation toolchain. The protocol is vendor-neutral on paper. The implementation toolchain isn't. Six months of Anthropic M&A starts looking less coincidental: December 2025: Bun, the JS runtime, pulled into Claude Code February 2026: Vercept, computer-use AI April 2026: Coefficient Bio, ~$400M healthcare AI May 2026: Stainless, SDK and MCP plumbing They're not buying training infrastructure or GPU clusters. They're buying the integration layers around the model. The bet seems to be that frontier models are converging faster than anyone expected, so the moat is everywhere except the model. If you're building on MCP today, tooling quality probably improves. Stainless's generator was already the cleanest in the space and the team that built it is now at Anthropic. Patterns will standardize faster as Stainless-derived templates become the de facto reference. The flip side is concentration risk. Cloudflare's MCP server framework, Pulse MCP, and the open-source generators Stainless released during the transition all become strategically important if you want any diversity in your stack. Sources: Anthropic announcement Why Anthropic actually did this, and migration math Curious whether Stainless ending up inside Anthropic reads as good news (better tooling) or concentration risk (one company owns the standard and the reference implementation) from your seat. submitted by /u/Ok-Constant6488 [link] [comments]
View originalSub-JEPA: a simple fix to LeCun group's LeWorldModel that consistently improves performance [P]
World models learn compact latent representations for planning without pixel reconstruction. LeWorldModel (LeWM), from LeCun's group at NYU, achieves stable end-to-end JEPA training by enforcing an isotropic Gaussian prior over the full latent space. The flaw: real environment dynamics live on low-dimensional manifolds, so a global high-dimensional Gaussian is an overly rigid prior — mismatched to the task geometry. LeWM itself struggles most on low-intrinsic-dimension tasks like Two-Room. Our fix (Sub-JEPA): apply the Gaussian regularization inside multiple frozen random orthogonal subspaces instead. This relaxes the global constraint while keeping the anti-collapse benefit. No new hyperparameters, same two-term objective. Sub-JEPA consistently outperforms LeWM across all four benchmarks, with up to +10.7 pp on Two-Room. We also observe straighter latent trajectories and better physical state decodability as emergent benefits. 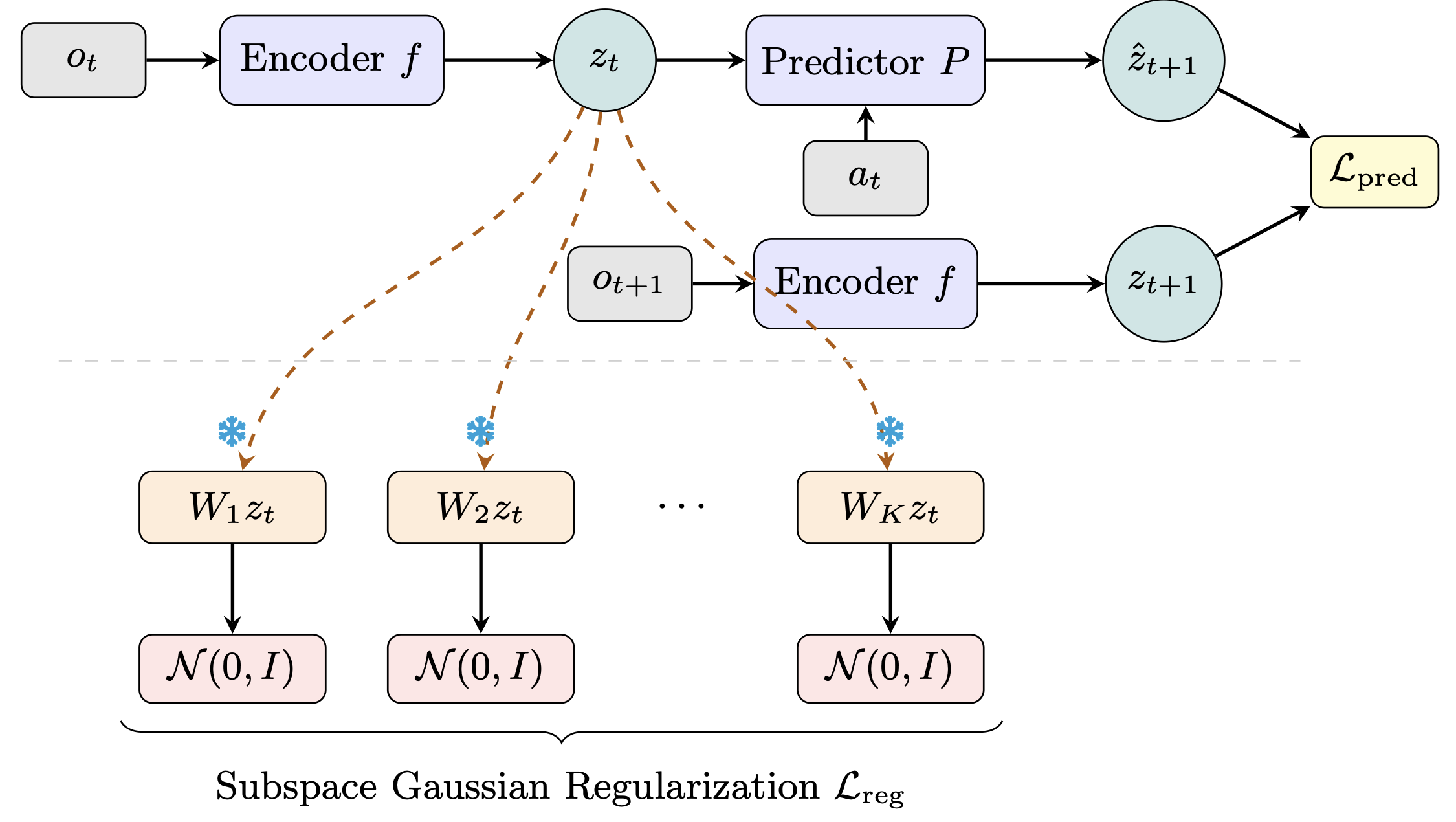  🌐 Project: https://kaizhao.net/sub-jepa 💻 Code: https://github.com/intcomp/sub-jepa 📄 Paper: https://arxiv.org/pdf/2605.09241 submitted by /u/kai-zhao [link] [comments]
View originalPapers with Code uses a subscription + tiered pricing model. Visit their website for current pricing details.
Key features include: Daily email updates with trending papers, Searchable database of research papers, Code implementations linked to papers, Benchmark datasets associated with research, User-friendly interface for easy navigation, Filtering options by categories and tags, Collaboration tools for researchers, Citation tracking for papers.
Papers with Code is commonly used for: Staying updated on the latest AI research, Finding code implementations for academic papers, Identifying benchmark datasets for experiments, Collaborating with peers on research projects, Conducting literature reviews efficiently, Exploring trending topics in AI research.
Papers with Code integrates with: GitHub for code repositories, Google Scholar for citation tracking, Mendeley for reference management, Slack for team notifications, Twitter for sharing trending papers, ResearchGate for academic networking, Zotero for bibliographic management, Medium for publishing summaries of papers.
Based on user reviews and social mentions, the most common pain points are: token usage, API costs.
Based on 118 social mentions analyzed, 19% of sentiment is positive, 76% neutral, and 4% negative.