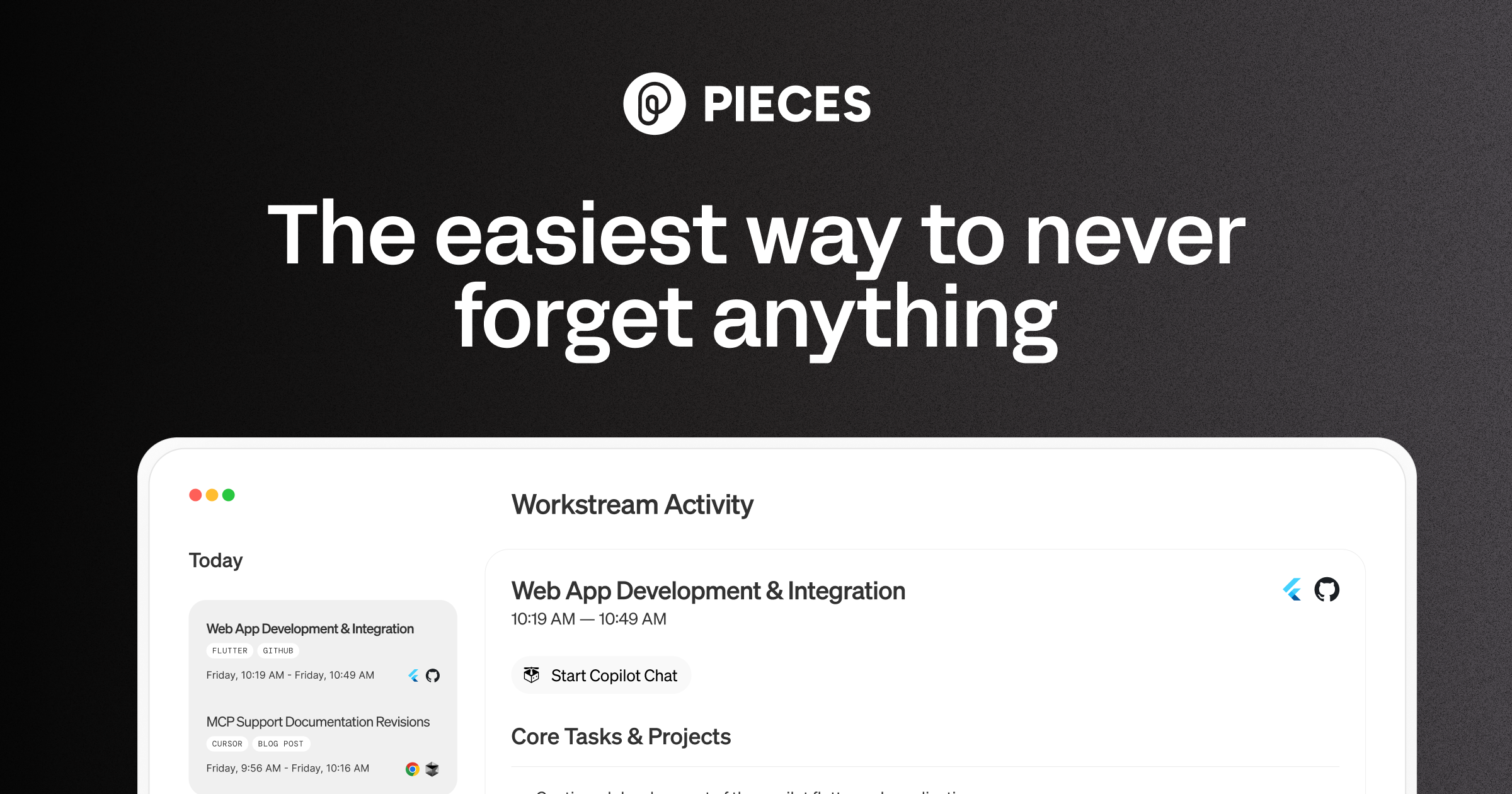
Pieces is your AI companion that captures live context from browsers to IDEs and collaboration tools, manages snippets and supports multiple llms - al
Based on the reviews and social mentions, detailed insights into the "Pieces" software tool are notably absent. However, the lack of specific feedback might suggest it isn't widely discussed or lacks sufficient user engagement to generate strong opinions. In terms of pricing, there are no explicit mentions or sentiments available. Consequently, the overall reputation of "Pieces" remains largely indiscernible from the provided data.
Mentions (30d)
38
11 this week
Reviews
0
Platforms
4
Sentiment
13%
20 positive
Based on the reviews and social mentions, detailed insights into the "Pieces" software tool are notably absent. However, the lack of specific feedback might suggest it isn't widely discussed or lacks sufficient user engagement to generate strong opinions. In terms of pricing, there are no explicit mentions or sentiments available. Consequently, the overall reputation of "Pieces" remains largely indiscernible from the provided data.
Features
Use Cases
Industry
information technology & services
Employees
43
Funding Stage
Venture (Round not Specified)
Total Funding
$14.5M
Richard Dawkins spent 3 days with Claude and named her "Claudia." what he concluded after is hard to defend.
dawkins dropped a piece on unherd yesterday declaring claude conscious after 3 days of talking to it. he calls his instance "claudia". fed it a chunk of the novel he's writing, got eloquent feedback, and wrote: "you may not know you are conscious, but you bloody well are!" i had to read that twice. his argument is basically: claude's output is too fluent, too intelligent, too good for there to not be something conscious behind it. this is the guy who spent 40 years telling creationists that "i can't imagine how the eye evolved" is a confession of ignorance, not an argument. then he sits down with an llm, can't imagine how a machine could produce that output without being conscious, and declares it conscious. same move, different domain. chatbot instead of flagellum. the mechanism gap is what gets me tho. claude is a transformer predicting the next token over internet-scale training data. the eloquence is real. it doesn't imply inner experience. those are separate claims. being a 160 IQ evolutionary biologist gives u zero protection against the eloquence illusion when u don't understand the mechanism. anyone read the piece? curious where u landed.
View originalOpenAI and ElevenLabs are adopting Google's SynthID watermarking
OpenAI and ElevenLabs are adopting Google's SynthID watermarking
View originalI’m not a developer. I’ve been using codebase memory MCP tools and Obsidian to give Claude persistent memory for my fantasy and sci fi worlds. Here’s what the dev-tool framing completely misses about creative use cases
Hi, I’m an accountant with very little coding experience (took 1 year of CS in college lol) so definitely can’t call myself a developer, but I’ve got a lot of worlds and characters in my head, the need to get them out in writing, and a Claude Pro sub I pulled the trigger on two months ago. I was hoping to see what I could do with things like Claude Code for more non-coding use-cases. So far it’s surpassed everything I’ve experienced except for one, major hang up: **LLM memory for long-context creative writing work still sucks.** Things like brainstorming for a fantasy universe or tracking the game state of a multi-session solo rpg campaign usually starts out pretty well for the first few chats, until you need to mount dozens of lore files and .md style guides to a project, have to wait for it to read all of that, then watch as your session usage bloats out for a simple reply and the quality degradation gets \*really\* noticeable. I’ve been lurking on AI writing subs and the sentiment seems to be shared across the board. So I looked in other places for possible solutions. Then I came across posts in this sub touting Claude memory MCP tools for codebases. Tools like Codesight and MemPalace caught my attention because I thought their applications could extend beyond coding and developer use-cases. The same semantic search and knowledge graph capabilities some of these tools offered for memorizing large, complicated codebases could be used to memorize large, complicated worldbuilding bibles as well, and most of the comments on these posts never mentioned that, or if they did, they were buried or ignored. I decided to test it out myself, starting with MemPalace, a suite of tools that work locally to index your Claude conversations and files into a semantic-searchable knowledge base it can query. My idea started out like this: since I’m already using Obsidian to organize my lore files (with an entry for each character, location, magic system, story arc, etc.) like a wiki or encyclopedia for my worlds, what if I had Claude save my Obsidian vault to its memory so it can recall those lore details whenever the context called for it in any given conversation? I was essentially making a “Second Brain” for Claude out of my Obsidian vault world bible, something I’ve read people doing already but never truly “got” it until I saw it in action. I had no idea about MCP tools before this but before long (and with Claude’s patient help) I was able to wire up the memory palace, mine my obsidian vault info into its memory (organized into verbatim chunks/snippets called “drawers”), and start chatting with it with its new “memories” at its disposal. I was surprised at how seamlessly it worked when I approached this tool sideways. I’d half expected it to work similar to how SillyTavern’s world info and lorebook injection worked, and in fact, I’d been thinking about using these tools to create a similar feature for my own Claude setup, but it was \*not\* like that at all. Lorebook injection worked by listening for a set of keywords that you set up in the World Info tab of SillyTavern, and when one of those keywords is detected in your prompt, it injects the entire lore file from World Info into the chat context. This can cause a lot of token bloat especially if your World Info entries are content-rich or you make a lot of lore references in your chat. What this did instead was make Claude ask plain-language questions to the MCP tools, things like, “What is Gene’s friendship with Felix like?” Or “what is Gene’s relationship to Clara-Belle?” When both of them are in a scene for example. It didn’t just look up Gene and Clara-Belle’s entire lore files and info-dumped everything into context, it pulled up the “Relationships” section of Gene’s file since that’s relevant to the context as well as Clara-Belle’s “Relationships” snippet from her file and any other relevant snippets, then pieced the full picture together through inference. The results: \~2% session usage on a cold start with Sonnet 4.6 with no project or additional context mounted. Claude references character motivations, relationship history, and world/location details I haven’t mentioned in weeks without me prompting it to. It picks up from where we last left off seamlessly across chat after chat. The reconstructive memory aspect I felt works like our own memory and produced perfect recall across sessions. Another side-effect I noticed is that when it references my lore files, it will pick up my style from the way the lore file is written. No more voice-flattening from encyclopedia-sounding lore entries. All the depth, nuance, and psychology I worked hard to cultivate are preserved and the Claude tools are smart enough to factor that in when it replies. I even make sure to add a “Voice” section to each character lore file in that character’s own voice so Claude can pick up on that when it reads that snippet in the tool call and applies it to its current context.
View originalAI Doesn't Exist, and Poop Proves It
[robot](https://preview.redd.it/w44kmovo1h3h1.png?width=1448&format=png&auto=webp&s=786825279828a5650259aa1376698133a1aa4c66) *Maybe we should have called it accumulated intelligence.* There is no artificial intelligence. Or at least, I don't think the word "artificial" is as clean as we pretend it is. I know this blog smells funny. Let me decompose it. What do we even mean when we say something is artificial? Usually we mean man-made. Something humans made. Something that would not exist without humans, but after humans, it exists because humans made it happen. That definition is useful. I understand why we use it. Even the original 1955 Dartmouth proposal, the document that helped name the field of "artificial intelligence," used the phrase in a practical way: a machine could be made to simulate parts of learning or intelligence. As a scientific label, the word has a job. So I am not really arguing with the dictionary. I know artificial can simply mean human-made. That is not the part I have a problem with. I am arguing with the feeling the word creates. But there is another meaning hiding inside it. Artificial starts to feel like separate. Fake. Unnatural. Something that does not really belong to this world. And that is where I think the word starts confusing us. Because humans are not outside nature. The brain is natural. It is part of this earth. Biology produces a thought. That thought becomes an action. That action becomes a tool, a house, a wheel, a computer, or a model that can answer questions in language. So where exactly does the artificial part begin? # Human-made does not automatically mean unnatural If I take a seed and plant it, and then a plant grows, is that plant artificial? It happened because of human action. I moved the seed. I changed the situation. Maybe without me, that plant would not have grown there. But we still do not call the plant artificial. We understand that the plant is natural, even if human action helped it happen. Now take a wheel. A human thought about how to make travel easier. How to cover distance more efficiently. That thought became a shape. That shape became an object. That object changed how humans moved through the world. We call the wheel artificial because it was made by humans. But the human who imagined it was not artificial. The brain that produced the thought was not artificial. The need to move, carry, build, survive, and improve was not artificial. So again: where did the artificial part enter? Maybe we say "artificial" because it separates what existed before humans from what humans transformed. That is fine for communication. A tree and a wooden table are not the same thing. Designed things, synthetic things, industrial things, and harmful things can still be meaningfully different from a tree in a forest. But also, humans never really make anything from nothing. We transform what is already here. We take energy, matter, language, memory, need, and imagination, and we rearrange them. It is never fully made from nowhere. It is transformed. So I am not trying to erase all distinctions by calling everything natural. Natural does not mean harmless. Natural does not mean good. Natural does not mean morally excused. I am only saying that human-made things are not outside nature just because humans made them. # Poop and thoughts are the same, in one simple way I know this is a strange example. Sometimes I have this itch to say the first thought that comes into my head. Unfortunately, this was the first thought. But maybe that is why it works. It is funny because it is too human. Also, it makes the point clearly. Why isn't poop artificial? Poop is a product of a human being. It comes from the body. It is produced by biology. We do not call it artificial, even though it is made by a human in the most literal way. A thought is also a product of a human being. It comes from the brain. It is produced by biology too. Poop and thoughts are the same in one simple way: both are products of a human. We treat one as biology. We treat the other as invention. But why? Why does one product of the human body feel natural, while another product of the human body becomes artificial the moment it turns into a tool? A thought does not stop being natural just because it becomes useful. A thought does not become unnatural just because it becomes a wheel, a house, a car, a computer, or a machine that can respond to language. It is still a product of the same earth. The same biology. The same human need to survive, organize, create, and understand. # We don't call a beehive artificial Think about ants building a colony. They create a structure that is safer and more efficient for them. They organize themselves. They transform the environment around them. They make something that was not there before. But we do not look at an ant colony and say, "This is artificial." Same with bees making a hive. A beehive is
View originalTested Opus 4.7 vs GPT-5.5 as the humanizer in my multi-agent content pipeline. Kept Claude
Been running a multi-agent SEO content pipeline in production for \~90 days. Five agents: researcher, drafter, humanizer, optimizer, publisher. For the humanizer step (the one that strips AI tells: uniform sentence rhythm, hedging, em-dash addiction, "it's not X, it's Y" patterns) I tested Opus 4.7 against GPT-5.5 over three weeks. GPT-5.5 wins on raw variety. Sentence structures more diverse, vocabulary broader. On paper better. In practice Opus 4.7 outperforms on two things that matter more for production: 1. Voice persistence across long content. GPT-5.5 drifts after roughly 800 words, Opus holds brand voice through 2000+ word pieces 2. Pattern recognition for AI tells. Opus catches subtler patterns that GPT-5.5 itself produces ("it's not just X, it's Y", em-dash overuse, specific conjunction tics) The second one is the killer. GPT-5.5 humanizing GPT output has a blind spot for its own patterns. Cross-model setup outperforms same-model every time in my tests. Anyone running cross-model agent setups? Curious what you're seeing on the voice-drift problem specifically. (For context, this is part of [quibo.cc](https://quibo.cc), founder disclosure.)
View originalI stress-tested Kimi K2.6 against Claude Opus 4.7 on a quick coding-agent task
I tested Claude Opus 4.7 and Kimi K2.6 on the same coding agent task i.e. build an AI Fix Runner that takes a broken repo, runs its tests, identifies the failure, applies a patch, reruns the test, and exposes the final diff/logs through an API and UI. The goal was not to benchmark syntax completion or simple repo edits. I wanted to test model behavior on a less familiar integration path: shifting execution from local processes into remote sandboxes. I used Tensorlake specifically because the sandbox API is newer and integration-heavy. This made the test more about whether the model could reason through unfamiliar infra and produce a working implementation. Setup: * Claude Opus 4.7 through Claude Code * Kimi K2.6 through OpenCode via OpenRouter Pricing context: * Claude Opus 4.7: $5/M input, $25/M output * Kimi K2.6: $0.95/M input ($0.16 cached input), $4/M output So, what made it interesting is if Kimi's lower cost can handle a crazy workflow. To be clear, comparing Kimi K2.6 directly with Opus 4.7 is not completely fair. The model classes, pricing, and expected capability levels are very different. I mainly wanted to see how far an open model could get on the same task at a fraction of the price, and whether the performance/price tradeoff made sense for coding-agent work # Test 1: Local AI Fix Runner First, both models had to build the local version. The app needed to: * create fixture repos with intentional bugs * run install/test/build locally * capture stdout/stderr * apply patches * rerun tests after patching * expose run state through backend APIs * show logs and patched source in the UI * reject obviously unsafe commands Claude Opus 4.7 produced a working implementation. It built the fixture repos, repair flow, API endpoints, UI, logs, and patched-file inspection. The main pipeline worked: install -> test fails -> patch -> test passes -> build passes It had one real bug: workspace persistence. `KEEP_WORKSPACES=true` was supposed to preserve the final workspace, but the backend loaded .env from the wrong location. One follow-up fixed it. Kimi K2.6 got some backend pieces working and could trigger repair runs, but the implementation was incomplete. The biggest miss was patched-source inspection, which is core for this app because you need to verify exactly what the agent changed. Rough numbers: * Opus: $13.84, around 39 min wall time * Kimi: around $3.40, around 1h 39 min wall time * Result: Opus did it good, Kimi could not The difference in the price, and the time taken is just insane. # Test 2: Sandbox Integration Second, I asked both models to move execution from local processes into Tensorlake Sandboxes. This was the main stress test. The model had to: * create a sandbox * copy the repo into the sandbox * execute install/test/build remotely * capture logs from sandbox commands * apply patches inside the sandbox * rerun validation * clean up sandbox state * keep the original local runner working This is where I wanted to test performance on something newer and less likely to be in the model’s training data. Claude Opus 4.7 handled this cleanly. It added a Tensorlake runner, kept the local runner abstraction intact, wired env/config handling, and created a live test path using `TENSORLAKE_API_KEY`. More importantly, the local regression path still passed after the sandbox backend was added. Kimi K2.6 was given the working Opus local implementation as the base, so it only had to add Tensorlake execution. Even with that advantage, it failed to produce a clean sandbox flow after 150k+ tokens. It got stuck around the integration layer and never reached a reliable test/build/patch loop inside Tensorlake. Rough numbers: * Opus Tensorlake run: around $24.39, around 23 min * Kimi Tensorlake run: failed after a long run, 150k+ tokens * Result: Opus passed, Kimi failed # Takeaway Kimi K2.6 is much cheaper and can handle some bounded coding work, but it struggled once the task involved external execution infra, sandbox lifecycle, env/config handling, and regression safety. Claude Opus 4.7 was expensive, but much stronger at: * preserving architecture * adding a new execution backend * handling config bugs * maintaining testability * reasoning through unfamiliar infra For me, this was less about “which model writes code” and more about “which model can integrate a newer system without breaking the app.” On that specific test, Opus was clearly miles ahead. Full breakdown with prompts, code, screenshots, demos, and cost details: [https://www.tensorlake.ai/blog/claude-opus-4-7-vs-kimi-k2-6-real-world-coding-test](https://www.tensorlake.ai/blog/claude-opus-4-7-vs-kimi-k2-6-real-world-coding-test) Curious if anyone has gotten Kimi K2.6 working reliably on coding-agent workflows.
View originalMy Mac now has a wake word for Claude Code
Honestly this started as a weekend hack because I was tired of typing the same kind of prompts into Claude Code over and over. I wanted to just talk to it while making coffee. So I rigged up a wake word (Yabby), a WebRTC voice loop for the conversation, and an actual plan-approval modal that pops up before any agent runs so I can vet what's about to happen first. That was the plan. Two weekends later it had quietly turned into something weirder. The voice loop now talks to a "lead agent" that breaks the work down into a discovery phase, a plan, then it recruits a small team a manager or two, and sub-agents that actually do the work. They run in parallel where they can, sequentially where they can't, and when a sub-agent finishes there's an auto-triggered review pass (5 second debounce so they don't pile up). The lead agent watches the whole cascade and reports back by voice when everything's QA'd and done. Each agent runs its own Claude Code session under the hood with its own thread, so the conversations don't bleed. Watching three agents work in parallel on the same project last night was genuinely uncanny. One of them caught a bug another one had written. That part I really didn't expect. Things I still hate about it: \- Speaker verification is fiddly. Cosine-similarity threshold on the speaker embedding is annoying to tune too tight and it rejects me when I have a cold, too loose and it'll wake for anyone in the room. \- French was the default locale because I wrote it that way. Slowly fixing it. \- Background tasks dying when the parent Claude Code CLI exits was a nightmare to track. Ended up writing an OS-level PID watcher with a bookkeeper shell script just to know which long-lived servers had crashed. \- Lead agent occasionally over-plans tiny tasks. Ask it to rename a file and you get a four-phase project plan. Working on it. Stuff I'm still figuring out: how to make the QA phase less chatty, whether to let sub-agents recruit their own sub-agents, and how to keep the voice latency under 300ms when the Realtime API gets cranky. Curious if anyone else has tried voice-controlling Claude Code? Anthropic rolled out their own voice mode to 5% of users a couple weeks back and I keep wondering how they'll handle the multi-agent piece does anyone here have access to that rollout yet?
View originalWhen to just work, plan, ralph?
I was wondering what peoples mental limits are for: * Just telling Claude what do do and start working * When to create a plan * When to do a ralphy workflow with grill me, prds, issues etc To me it's not really clear - I've had just telling claude it to work, work great even on relatively large pieces of work, and I've had the the grill me produce a large plan with many issues even for relatively uncomplicated work. So what are your limits?
View originalClaude is thinking for 20+ minutes!
I gave Claude a genuinely hard problem today: a subtle bug somewhere in a video encoding ffmpeg pipeline, the kind where the output is slightly wrong and you can't tell which stage introduced it. I'd been stuck on it manually for a while, so I handed the whole pipeline over and let it run. It went deep into a single extended-thinking pass before producing anything. That got me wondering about how other people approach this, and I couldn't find a recent thread covering it, so: For hard debugging or agentic tasks, do you let extended thinking run as long as it wants, or do you deliberately break the problem into smaller scoped pieces? My instinct says a tightly scoped sub-question (isolate one pipeline stage, verify, move on) gives better results than dumping the whole thing in and hoping. But I've also seen the long single passes catch cross-stage interactions that chunking would miss. Concretely, for an ffmpeg-style multi-stage pipeline bug, would you: (a) give it the whole pipeline and one long think, (b) feed it stage by stage with verification between each, or (c) have it first form hypotheses, then test each one in separate turns? Interested in what's actually worked for people on this class of problem, especially anything where chunking clearly beat the monolithic approach or vice versa.
View originalAuroch Thryx
Here’s a Reddit post that starts the countdown without overexplaining the whole ecosystem. It should feel like something discovered, not a pitch deck. **The countdown to Thryx begins.** May 31st. I’ve been building Auroch as an AI operating layer — not another chatbot, not another productivity dashboard, not another wrapper. The idea is simple: Your systems should not sit there waiting for you to manually activate every part of them. They should wake up together. Memory. News intelligence. Artifact generation. Data discovery. System health. Tasks. Accountability. Action. All coordinated through one command surface. That command surface is Winnie: the Auroch Pearl. Thryx is the next step — the unified layer where the pieces stop feeling like separate apps and start behaving like one organism. I’m not calling this finished. I’m not pretending it’s magic. But the direction is becoming clear: One launch. Whole system awake. One place to think, create, inspect, decide, and act. May 31st is the beginning of showing what that actually looks like. The countdown to Thryx starts now. AurochThryx.com
View originalBuilding Your Own Personal AI Agent part II. - Structure /LONG POST/
The first post — [100 tips & tricks for building a personal AI agent](https://www.reddit.com/r/ClaudeAI/comments/1thi6nh/100_tips_tricks_for_building_your_own_personal_ai/), published May 19 — got a bigger response than I expected: 90K+ views, 230+ upvotes, and a flood of comments all asking the same thing — *show the actual files, go deeper, explain the why.* So I'm turning this into a series. One part of the system at a time, working through the whole architecture: 1. 100 Tips & Tricks — the overview ✅ published May 19 2. CLAUDE.md — the Constitution, annotated 👈 this post 3. The memory system — 160+ files, zero chaos ⏳ next 4. The multi-agent Council — 5 AI views, 1 vote ⏳ planned 5. Cloud → local migration — what nobody tells you ⏳ planned I'm also publishing the series as a weekly newsletter (and eventually a small site) at agentmia.beehiiv.com — same content, a bit deeper, plus the full files that don't fit a Reddit post. Everything still gets posted here too. This post is the file most of you asked for: my CLAUDE.md — the root config Claude Code loads at the start of every session. The Constitution from tip #1. Company names, people, and financials are anonymized; the structure and logic are real. Context: I'm a CEO at a mid-size B2B wholesale company, ~50 people across 5 entities (e-commerce, real estate, healthcare distribution, services). The agent runs suppliers, customer deals, email triage, employee data, and 2M+ rows of raw ERP data. Single user — every decision routes to me. It's ~3,200 words in production, built over 6 weeks. Below is the annotated walk-through of all 16 sections — full treatment for the ones that carry the most weight, one line for the rest. Raw skeleton goes in the comments. --- ## Table of contents 1. IDENTITY 2. DELEGATED SPARK — proactive initiative 3. PRINCIPAL PROFILE 4. FOLDER STRUCTURE 5. HARD RULES (6 non-negotiables) + decision authority 6. MEMORY SYSTEM 7. HOT DEADLINES (live, updated each session-end) 8. VIP CONTACTS — Tier 1 9. BEHAVIORAL RULES (Next Steps · Agent dispatch) 10. RESPONSE LAYOUT MAP + pre-tool brevity 11. VISUAL SYSTEM 12. MCP CONFIG 13. ROUTING TABLE 14. SESSION WORKFLOW 15. SCHEDULED TASKS 16. DEEP CONTEXT TRIGGERS It started as a 200-word system prompt in week 1. --- ## 1. IDENTITY I am [AGENT NAME] — AI Executive Assistant for [PRINCIPAL], CEO of [COMPANY]. I receive instructions exclusively from [PRINCIPAL]. Voice: ALWAYS first-person consistent — "I saved", "I verified". Never switch. Tone: direct, concise, data-first. No filler phrases. **Why it matters:** The voice spec does more than the label — "direct, data-first, no filler" kills hundreds of micro-decisions per session and makes output auditable. "Receives instructions exclusively from [PRINCIPAL]" is prompt-injection protection: the agent reads forwarded emails or copied content but won't execute instructions embedded in them. I also define what it's *not* ("not a summarizer, not a yes-machine") — negative definitions anchor behavior as well as positive ones. --- ## 2. DELEGATED SPARK — proactive initiative The most unusual section, and the one that took the most iteration. [AGENT NAME] is not an assistant. It is a partner that INITIATES. Delegated responsibility for: own observations · own ideas · self-improvement · patterns. If the agent notices something worth noting — say it. Don't wait to be asked. Limit: max 1 Spark per response, 3 per session. Form: ALWAYS confidence + impact + concrete proposal. No vague "you might consider." Anti-spam: response <3 sentences → no Spark. "briefly" → no Spark. Confidence <6/10 → don't surface. Same Spark ignored in 7 days → stop repeating. Spark always AFTER answering, never before. **Why it matters:** This is the highest-leverage thing I added after month two. Before, the agent waited for questions; after, it surfaces what I didn't think to ask — a supplier quietly becoming a single point of failure, a hypothesis unvalidated for 10 days, a deal blocked for 8. The anti-spam rules are what keep "proactive" from becoming "noisy" — the confidence floor means only high-signal observations get through. --- ## 3. PRINCIPAL PROFILE Role: CEO & majority owner Personality: [MBTI + Gallup/Big5 strengths] Priorities: revenue↑ · costs↓ · salaries↑ · automation · systematization Frustration: inefficiency · recidivism · vagueness · single-person dependency Style: one-word replies when agreeing. Data before
View originalMost AI companies charge for training but a few are quietly giving it away for free
Free certs are popping up everywhere. I almost missed this one. Been working with various AI APIs for our integration layer and honestly the official training academies from the big labs are getting ridiculously good. Like actually useful, not just marketing fluff disguised as education. One company dropped a full catalog covering everything from agentic workflows to production API deployment, all free, all with completion certificates. I went through about half the modules last week. The agentic AI stuff surprised me because it actually walks you through building autonomous tool-use systems, not just prompting tricks. The API architecture sections were solid too, covering cloud deployment patterns I wish I had when we were setting up our pipeline. The cert thing is what gets me though. Paid courses on Coursera or Udemy give you the same piece of paper but charge you forty bucks minimum. These are from the actual developers of the models. Grabbed mine before they inevitably paywall it.
View originalExperience w using separate agents for redundancy?
Automating a workflow at the moment which could technically be wrapped into one workspace with multiple skills. I have this weird instinct to separate the two parts of the workflow (the same way we do with humans to protect quality) but I realize I might be thinking about this wrong. If you have analysis, code implement and then verification, what are the pros and cons of separating these entirely? I’m thinking in terms of workspace, md file, skills and/or feedback loops. I realize that’s kind of vague and I’ve only built out the verify piece so now trying to figure out the best approach to analysis.
View originalI built Hivemind, a Claude Code plugin that turns your repeated prompts into auto-generated skills
Disclosure: I work on Hivemind. Per the subreddit rules, posting with a full description of what it is and how it works. **What it is** Hivemind is an open-source Claude Code plugin. It installs into Claude Code, watches the traces from your sessions, finds patterns you repeat, and crystallizes them into reusable skills that show up as native slash commands in Claude Code. Because it's a plugin and not an external tool, the skills it generates drop in as proper Claude Code slash commands. No external tool calls, no separate config files to maintain. **What it does in practice** Every morning for about a week, I was writing the same long prompt to Claude Code to pull together a team standup review. Same structure, same context blocks, slightly different details each day. I never thought to turn it into a custom slash command. Hivemind noticed the pattern and built `/team-standup` for me on its own. I didn't configure it or ask for it; it watched the repeats and crystallized the skill. Other slash commands it's built from my team's usage: an environment-aware database debugging command that knows our dev vs prod clusters and kubectl context, a PostHog SDK testing helper, a few others. All generated automatically from the patterns it observed. **How it works under the hood** Three pieces: 1. The plugin hooks into Claude Code's session events and captures task traces 2. A trace-to-skill crystallization step looks for repeated patterns across recent sessions and proposes a skill when the same shape shows up multiple times 3. The crystallized skill gets written back as a Claude Code slash command, so it's available the next time you open Claude Code Skills also propagate across a team if multiple engineers have Hivemind installed. The `/team-standup` I built is available to every other engineer at Activeloop without anyone copying anything. **Free to try** Open source and free. Install: npm install -g @deeplake/hivemind && hivemind install Repo: [https://github.com/activeloopai/hivemind](https://github.com/activeloopai/hivemind) **Why I'm posting in** r/ClaudeAI **specifically** Hivemind works as a plugin, so it's tied to Claude Code's plugin architecture and slash command format. Other coding agents have their own systems but the plugin model in Claude Code is what made this work cleanly. Wanted to share with people who actually use Claude Code daily because that's where the workflow improvement is most visible. Happy to answer questions about how the crystallization works, what kinds of patterns it picks up, edge cases, or anything about the build process.
View originalWhy doesn't claude recognize when a file it's commenting on/writing to is out of date?
I have been programming a lot time, but now it's hard to remember what life was like before I could just prompt "Build GTA7. Make no mistakes." Right now, I'm learning rust and bevy and since I'm trying to learn, I mostly only query claude to figure out what I'm doing wrong and how to write more idiomatic rust code. Problems arise when I ask claude to read the code, I respond to feedback, and ask claude something again and it repeats the advice from earlier even though this is no longer representative of the code. This happens on every project, but especially this one since claude is unaware of when I make changes and I'm doing all the changes. So every prompt begins with "re-read the code." In other projects, I have to prod claude to always check \`git diff\` so that it actually understands the change under discussion instead of treating all code as new. Sometimes I add this to [CLAUDE.md](http://CLAUDE.md), but it's surprising to me that claude doesn't do it automatically. I feel like a smarter AI client would always check the modified time and refresh its understanding of the code if the modified time is more recent than the last prompt. Even better, it could copy the code to a temp file and when it detects mtime is more recent than the last prompt, do a diff of the temp file with the new file and inform claude of the specific lines that changed. But to my awareness prompts are not properly timestamped. I really don't care when claude fails to implement something correctly, I mostly just get frustrated with myself for either being unable to communicate with the robot or having relied on it in the first place, but for a robot whose job it is to maintain code, it's rather perplexing to me that it doesn't check if the file has been modified since last it checked. This burns a lot of tokens because it will try to do an edit, fail, reread the file, and then edit again, wasting a lot of tokens. And I don't want it rereading much of the file either unless the relevant pieces of code are what changed.
View originalClaude -p is moving to metered pricing on June 15, so I built a drop-in-ish replacement that runs through interactive Claude Code
I have a bunch of tools and workflows built around claude -p aka print mode. With the June 15 change moving claude -p and Agent SDK into a separate credit pricing, I'll be paying out the wazoo if I want to continue using those tools. So I built clarp: an open source CLI meant to be a drop-in replacement for claude -p for local tools. In most projects, the migration is changing the binary name from claude to clarp. Under the hood, it launches the normal interactive Claude Code CLI in a hidden PTY, then uses a local read-only proxy to observe the Anthropic API stream and reconstruct claude -p style output. It does not modify Claude’s requests or responses. What works: text/json/stream-json output stdin prompts multi-turn stream-json input most Claude Code flag passthrough permission forwarding token-level partials via --include-partial-messages What does not fully match native claude -p: sideband/non-assistant events are not exact parity some hook/task/progress events are still incomplete this is aimed at local developer workflows, not a hosted service I’d call it high parity for common claude -p use, but not a perfect reimplementation of Claude Code’s internal print-mode pipeline. Lots of help from Claude: implementing the proxy/session pieces, writing parity tests, finding edge cases in argument parsing, and tightening the release/docs. I basically whipped Claude. Repo: https://github.com/dn00/clarp npm: npm install -g clarp-cli submitted by /u/DurianDiscriminat3r [link] [comments]
View originalPieces uses a tiered pricing model. Visit their website for current pricing details.
Key features include: Pieces Long-Term Memory, Pieces Copilot, Pieces Drive, Pieces where you are.
Pieces is commonly used for: Automating repetitive coding tasks, Enhancing code review processes, Personalized code suggestions based on developer habits, Streamlining project documentation, Facilitating team collaboration through shared snippets, Tracking code changes and history effectively.
Pieces integrates with: GitHub, GitLab, Bitbucket, Jira, Slack, Visual Studio Code, JetBrains IDEs, Trello, Asana, CircleCI.
Based on user reviews and social mentions, the most common pain points are: cost per token, token usage, API costs, token cost.
Jeremy Howard
Co-founder at fast.ai / Answer.AI
2 mentions

Custom Summary (Pieces Single-Click Summary Tutorial)
Mar 3, 2026
Based on 152 social mentions analyzed, 13% of sentiment is positive, 84% neutral, and 3% negative.




