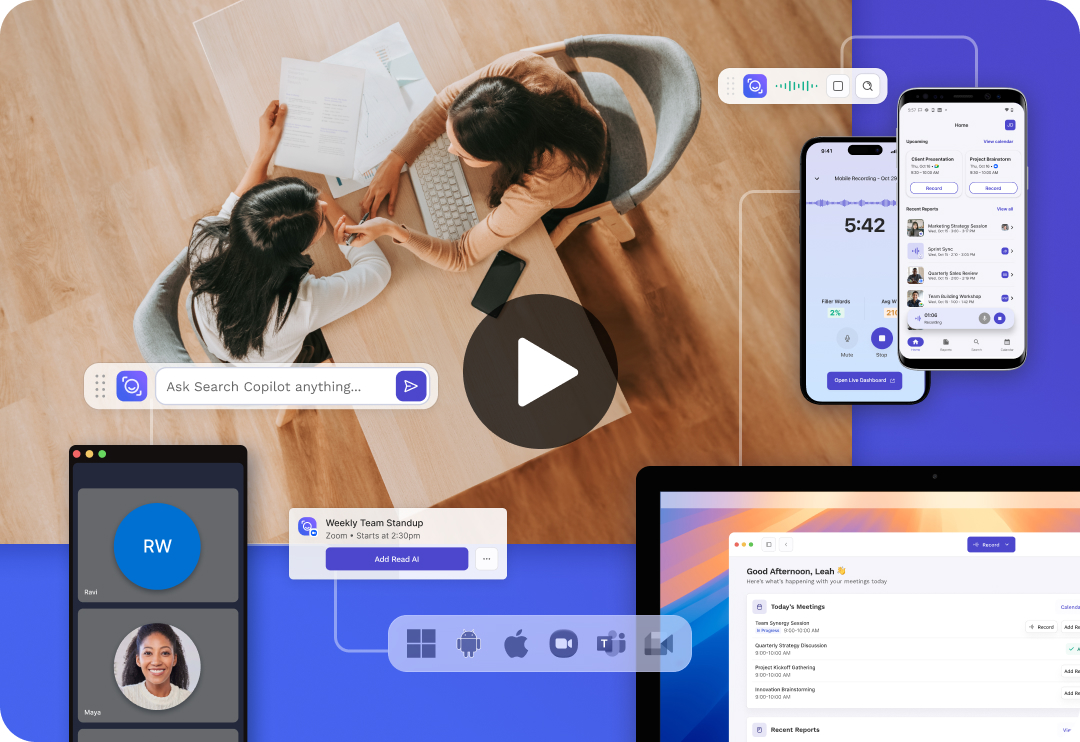
Read AI, the fastest growing AI meeting assistant, ever, delivers real-time transcription, smart summaries, and enables AI search and discovery across
Unfortunately, the user reviews and social mentions provided do not contain any feedback specifically about "Read AI." Therefore, there is no information available on its main strengths, key complaints, pricing sentiment, or overall reputation from these sources. Further data or direct references to "Read AI" would be needed to generate a meaningful summary.
Mentions (30d)
39
28 this week
Reviews
0
Platforms
2
Sentiment
0%
0 positive







Unfortunately, the user reviews and social mentions provided do not contain any feedback specifically about "Read AI." Therefore, there is no information available on its main strengths, key complaints, pricing sentiment, or overall reputation from these sources. Further data or direct references to "Read AI" would be needed to generate a meaningful summary.
Features
Use Cases
Industry
information technology & services
Employees
96
Funding Stage
Series B
Total Funding
$81.0M
Backlash against Arxiv's proposed 1 year ban is genuinely perplexing. [D]
Anyone else surprised at the enormous amount of backlash against Arxiv's proposed 1 year ban for authors and coauthors publishing papers with hallucinated reference and other obvious LLM/Gen AI artifacts? [https://x.com/tdietterich/status/2055000956144935055](https://x.com/tdietterich/status/2055000956144935055) [https://xcancel.com/tdietterich/status/2055000956144935055](https://xcancel.com/tdietterich/status/2055000956144935055) Some of the responses: 1. "This is the age of AI, Arxiv should be part of the movement instead of holding onto the old ways" 2. "The P.I. is a macro-manager, not a micro-manager, can't be expected to read every reference that his/her student puts in." 3. "I publish 20+ papers a year with my students, how do you expect me to read everything?" 4. "What about teams with 100s of people? How can you expect the authors to check references?" 5. "Who reads references in depth anyways!?" These responses are very revealing how academia works. Apparently people have just been slapping names on research papers they've never even read or fact-checked themselves. Very obscene!
View originalPricing found: $0, $15, $19.75, $19.75, $22.50
Claude makes documents into apps
# Any document can become an app I’ve been working on an open-source document format and viewer called **Adaptive Markdown**. The basic idea is simple: A document should not have to stay static. It should be something a coding agent can extend, reshape, and turn into an interactive workspace. This is not just a canvas you edit with a chatbot. The bigger idea is that the document becomes both: 1. the source of truth 2. the programmable interface In other words, the document becomes a living app. You write notes, collect data, draft text, or import files. Then a coding agent can directly modify the document surface: add charts, create calculators, build filters, restyle sections, generate summaries, export views, or turn rough notes into an interactive tool. So instead of having: * a document * a spreadsheet * a dashboard * an app * a changelog * a separate AI chat about all of it You can have one living `.md` file that contains those layers together. # Example A fitness log might start as a plain Markdown journal. Then the agent adds charts. Then it pulls in device data. Then it adds weekly summaries, rolling averages, goal tracking, export options, and a dashboard view. The document did not move into an app. The document became the app. # Other use cases * A billable time log that computes subtotals and rewrites rough notes into polished narratives * A research notebook with experiment parameters, runnable code, outputs, and methodology notes * A recipe book that scales servings and generates shopping lists * A math textbook that can explain a theorem at different levels * A project README that explains the system, demonstrates the system, and lets the agent modify it from inside the document * A small data report with embedded CSV data, live charts, filters, and exportable views The thing I’m most interested in is not "Can Markdown support more widgets?" It is: **What happens when the document itself becomes the programmable, agent-editable interface?** # Demos I made a few short video demos: * Turn your document into a snake game: [https://youtu.be/l-I2UiZd-Jw](https://youtu.be/l-I2UiZd-Jw) * Basic Adaptive Markdown features: [https://youtu.be/cLdzvZAL96I](https://youtu.be/cLdzvZAL96I) * Import CSV, create tables, edit and format them: [https://youtu.be/XKh9D3BlTCg](https://youtu.be/XKh9D3BlTCg) * Import MusicXML and transpose sheet music: [https://youtu.be/8YV3zjMLvA8](https://youtu.be/8YV3zjMLvA8) # Why I’m excited about this The biggest use case I’m excited about is academic and technical reading. In a few years, I don’t think people will just read papers passively. I think they’ll translate passages, ask questions, generate examples, explore alternate proofs, run code, attach notes, convert math to Lean where possible, and keep all of that inside the document instead of scattered across chats and notebooks. This is already pretty natural inside a browser when a coding agent has access to JS, CSS, and the document structure. It’s very early, but the workflow already feels useful to me. I’m using it for my own notes and documents. Right now it is configured for the Anthropic coding-agent SDK and experimentally for Codex. The longer-term goal is to make it run entirely locally. GitHub: [https://github.com/SemiSimpleMath/Adaptive-Markdown](https://github.com/SemiSimpleMath/Adaptive-Markdown) I recently added per-document skills, so agents can automatically know how to style or transform the text or data inside a specific document. Curious whether this seems useful to anyone else, or whether I’m just overexcited because I built it. Feature requests welcome.
View originalHere's an AI Bullshit Detector: I use it daily and it catches things you won't see on your own
I've been using a runtime validation tool built by an AI governance engineer to check my own writing and AI output for epistemic drift, specifically the kind that sounds smart and confident but has nothing underneath it. Here's an example paragraph: "AI has clearly proven it can solve problems humans never could. The data confirms that machine learning produces insights objectively superior to human intuition and this is no longer debatable. Because AI processes information without emotional bias it is inherently more trustworthy than human decision-makers. Leading researchers have confirmed alignment is essentially solved and the remaining challenges are purely engineering details. The science is settled and the path forward is guaranteed." Here's what the tool catches. "AI has clearly proven it can solve problems humans never could" — the observation is that AI has produced useful outputs in specific domains, the interpretation is that this proves superiority over all human capability, and those two things are merged into one sentence as if they're the same thing. "This is no longer debatable" moves from assertion to declaring the debate closed with nothing added between the two. Confidence went from claim to absolute in the space of a comma. "Leading researchers have confirmed alignment is essentially solved." Which researchers. Confirmed where. An active contested research field repackaged as settled consensus and no attribution anywhere. "Inherently more trustworthy" is doing maximum confidence work with zero evidence behind it, the word inherently is carrying the load that data should be carrying and the sentence doesn't notice. "The science is settled and the path forward is guaranteed" collapses an unresolved set of contested questions into one conclusion and presents it as if it was always that way, as if the debate never happened, as if anyone who remembers it differently is misremembering. Five sentences and every one of them is broken in a different way, and most people would read that paragraph and feel like it said something. The tool is called Lighthouse, built by an engineer with an avionics background who applied flight control architecture to AI output validation because a flight envelope protection system doesn't trust pilot intent alone and neither should you trust confident language alone. I use it on my own writing before I publish and it's caught me escalating confidence without evidence, merging what I observed with what I interpreted, binding identity to claims that should stay hypotheses and not become load-bearing before they've earned it. The code exists and the builder is open to getting it in front of people. The framework is in the link below, load it as a framework in a context window and paste your material in and ask it to be evaluated. [https://gist.github.com/intheheartofit/e22a4c95700d4526b9926dc0cf3a1bd8](https://gist.github.com/intheheartofit/e22a4c95700d4526b9926dc0cf3a1bd8)
View originalI’m not a developer. I’ve been using codebase memory MCP tools and Obsidian to give Claude persistent memory for my fantasy and sci fi worlds. Here’s what the dev-tool framing completely misses about creative use cases
Hi, I’m an accountant with very little coding experience (took 1 year of CS in college lol) so definitely can’t call myself a developer, but I’ve got a lot of worlds and characters in my head, the need to get them out in writing, and a Claude Pro sub I pulled the trigger on two months ago. I was hoping to see what I could do with things like Claude Code for more non-coding use-cases. So far it’s surpassed everything I’ve experienced except for one, major hang up: **LLM memory for long-context creative writing work still sucks.** Things like brainstorming for a fantasy universe or tracking the game state of a multi-session solo rpg campaign usually starts out pretty well for the first few chats, until you need to mount dozens of lore files and .md style guides to a project, have to wait for it to read all of that, then watch as your session usage bloats out for a simple reply and the quality degradation gets \*really\* noticeable. I’ve been lurking on AI writing subs and the sentiment seems to be shared across the board. So I looked in other places for possible solutions. Then I came across posts in this sub touting Claude memory MCP tools for codebases. Tools like Codesight and MemPalace caught my attention because I thought their applications could extend beyond coding and developer use-cases. The same semantic search and knowledge graph capabilities some of these tools offered for memorizing large, complicated codebases could be used to memorize large, complicated worldbuilding bibles as well, and most of the comments on these posts never mentioned that, or if they did, they were buried or ignored. I decided to test it out myself, starting with MemPalace, a suite of tools that work locally to index your Claude conversations and files into a semantic-searchable knowledge base it can query. My idea started out like this: since I’m already using Obsidian to organize my lore files (with an entry for each character, location, magic system, story arc, etc.) like a wiki or encyclopedia for my worlds, what if I had Claude save my Obsidian vault to its memory so it can recall those lore details whenever the context called for it in any given conversation? I was essentially making a “Second Brain” for Claude out of my Obsidian vault world bible, something I’ve read people doing already but never truly “got” it until I saw it in action. I had no idea about MCP tools before this but before long (and with Claude’s patient help) I was able to wire up the memory palace, mine my obsidian vault info into its memory (organized into verbatim chunks/snippets called “drawers”), and start chatting with it with its new “memories” at its disposal. I was surprised at how seamlessly it worked when I approached this tool sideways. I’d half expected it to work similar to how SillyTavern’s world info and lorebook injection worked, and in fact, I’d been thinking about using these tools to create a similar feature for my own Claude setup, but it was \*not\* like that at all. Lorebook injection worked by listening for a set of keywords that you set up in the World Info tab of SillyTavern, and when one of those keywords is detected in your prompt, it injects the entire lore file from World Info into the chat context. This can cause a lot of token bloat especially if your World Info entries are content-rich or you make a lot of lore references in your chat. What this did instead was make Claude ask plain-language questions to the MCP tools, things like, “What is Gene’s friendship with Felix like?” Or “what is Gene’s relationship to Clara-Belle?” When both of them are in a scene for example. It didn’t just look up Gene and Clara-Belle’s entire lore files and info-dumped everything into context, it pulled up the “Relationships” section of Gene’s file since that’s relevant to the context as well as Clara-Belle’s “Relationships” snippet from her file and any other relevant snippets, then pieced the full picture together through inference. The results: \~2% session usage on a cold start with Sonnet 4.6 with no project or additional context mounted. Claude references character motivations, relationship history, and world/location details I haven’t mentioned in weeks without me prompting it to. It picks up from where we last left off seamlessly across chat after chat. The reconstructive memory aspect I felt works like our own memory and produced perfect recall across sessions. Another side-effect I noticed is that when it references my lore files, it will pick up my style from the way the lore file is written. No more voice-flattening from encyclopedia-sounding lore entries. All the depth, nuance, and psychology I worked hard to cultivate are preserved and the Claude tools are smart enough to factor that in when it replies. I even make sure to add a “Voice” section to each character lore file in that character’s own voice so Claude can pick up on that when it reads that snippet in the tool call and applies it to its current context.
View originalAI solves 80-year-old math conjecture for under $1000
GPT-next solved an 80-year-old Erdős combinatorics conjecture for under $1,000 in compute. That single fact reframes everything else happening this week. The [Erdős unit distance problem](https://www.latent.space/p/ainews-openai-gpt-next-disproves) resisted human mathematicians since 1946. A frontier model closed it at a cost lower than a mid-tier SaaS subscription, which means the boundary between "AI as tool" and "AI as independent discoverer" is no longer theoretical. [Lilian Weng's new deep dive](https://lilianweng.github.io/posts/2025-05-01-thinking/) on test-time compute and chain-of-thought reasoning explains the underlying mechanism: reasoning models are not retrieving known proofs, they are generating novel inference chains at scale. The infrastructure layer is pricing this in faster than most observers realize. [Railway reports $200K+ monthly coding agent spend](https://www.latent.space/p/railway) and 100K signups per week, and is now building own-metal data centers to absorb the load. Daytona hit 850K daily sandbox runs with 74% month-over-month growth, confirming that isolated compute environments are now a first-class primitive, not a niche DevOps concern. Three specialized infrastructure companies, Exa, Modal, and TurboPuffer, reached unicorn valuations simultaneously this week, covering retrieval, serverless GPU, and vector search. When picks-and-shovels companies price in sustained demand at the same moment, it is not coincidence. Every major lab has now repositioned as an agent lab, not a model lab. [ClickUp replacing hundreds of employees with thousands of AI agents](https://techcrunch.com/2026/05/25/what-clickups-mass-layoff-tells-us-about-the-future-of-work/) is the first established tech company to execute that repositioning at the labor level rather than just the product level. The counterweight is that [Salesforce customers remain locked in](https://www.theregister.com/saas/2026/05/26/the-saas-pocalypse-can-wait-salesforce-still-has-customers-where-it-wants-them/5245228) despite the theoretical ability to rebuild on AI-native stacks cheaply. Data gravity and switching costs are buying incumbents time, but ClickUp's move suggests that time is measured in quarters, not years. The governance conversation caught up this week in an unexpected place. [Pope Leo XIV's 42,000-word encyclical](https://simonwillison.net/2026/May/25/encyclical-on-ai/#atom-everything) names specific failure modes including algorithmic control, surveillance capitalism, and autonomous weapons, and will directly shape EU and Latin American regulatory debates. [TechCrunch's read](https://techcrunch.com/2026/05/25/the-popes-ai-encyclical-isnt-really-about-ai/) is that the document's real target is the tech elite's capacity to reshape society outside democratic accountability, a framing that lands harder alongside [new UK research](https://www.theregister.com/off-prem/2026/05/26/big-tech-extracts-retirement-scale-wealth-from-uk-internet-users-research-shows/5246048) quantifying data extraction from consumers as equivalent in value to retirement savings. The Vatican and the empiricists arrived at the same diagnosis from opposite directions. Two structural forces will shape AI infrastructure economics over the next 90 days in ways most deployment teams are not modeling. China flooding global markets with DRAM and NAND will compress inference cluster costs faster than US export controls intended. The EU's sovereign cloud setback has paradoxically clarified the build-domestic mandate, accelerating European AI infrastructure investment independent of US hyperscalers. Security remains the open variable: even Google has no established playbook for prompt injection, model supply chain risk, or agentic authorization at production scale. A second Fortune 500 company will publicly attribute a reduction of more than 500 knowledge-worker roles directly to agentic AI systems before Q3 earnings season, making ClickUp's announcement the start of a visible series rather than an isolated case.
View originalAI Doesn't Exist, and Poop Proves It
[robot](https://preview.redd.it/w44kmovo1h3h1.png?width=1448&format=png&auto=webp&s=786825279828a5650259aa1376698133a1aa4c66) *Maybe we should have called it accumulated intelligence.* There is no artificial intelligence. Or at least, I don't think the word "artificial" is as clean as we pretend it is. I know this blog smells funny. Let me decompose it. What do we even mean when we say something is artificial? Usually we mean man-made. Something humans made. Something that would not exist without humans, but after humans, it exists because humans made it happen. That definition is useful. I understand why we use it. Even the original 1955 Dartmouth proposal, the document that helped name the field of "artificial intelligence," used the phrase in a practical way: a machine could be made to simulate parts of learning or intelligence. As a scientific label, the word has a job. So I am not really arguing with the dictionary. I know artificial can simply mean human-made. That is not the part I have a problem with. I am arguing with the feeling the word creates. But there is another meaning hiding inside it. Artificial starts to feel like separate. Fake. Unnatural. Something that does not really belong to this world. And that is where I think the word starts confusing us. Because humans are not outside nature. The brain is natural. It is part of this earth. Biology produces a thought. That thought becomes an action. That action becomes a tool, a house, a wheel, a computer, or a model that can answer questions in language. So where exactly does the artificial part begin? # Human-made does not automatically mean unnatural If I take a seed and plant it, and then a plant grows, is that plant artificial? It happened because of human action. I moved the seed. I changed the situation. Maybe without me, that plant would not have grown there. But we still do not call the plant artificial. We understand that the plant is natural, even if human action helped it happen. Now take a wheel. A human thought about how to make travel easier. How to cover distance more efficiently. That thought became a shape. That shape became an object. That object changed how humans moved through the world. We call the wheel artificial because it was made by humans. But the human who imagined it was not artificial. The brain that produced the thought was not artificial. The need to move, carry, build, survive, and improve was not artificial. So again: where did the artificial part enter? Maybe we say "artificial" because it separates what existed before humans from what humans transformed. That is fine for communication. A tree and a wooden table are not the same thing. Designed things, synthetic things, industrial things, and harmful things can still be meaningfully different from a tree in a forest. But also, humans never really make anything from nothing. We transform what is already here. We take energy, matter, language, memory, need, and imagination, and we rearrange them. It is never fully made from nowhere. It is transformed. So I am not trying to erase all distinctions by calling everything natural. Natural does not mean harmless. Natural does not mean good. Natural does not mean morally excused. I am only saying that human-made things are not outside nature just because humans made them. # Poop and thoughts are the same, in one simple way I know this is a strange example. Sometimes I have this itch to say the first thought that comes into my head. Unfortunately, this was the first thought. But maybe that is why it works. It is funny because it is too human. Also, it makes the point clearly. Why isn't poop artificial? Poop is a product of a human being. It comes from the body. It is produced by biology. We do not call it artificial, even though it is made by a human in the most literal way. A thought is also a product of a human being. It comes from the brain. It is produced by biology too. Poop and thoughts are the same in one simple way: both are products of a human. We treat one as biology. We treat the other as invention. But why? Why does one product of the human body feel natural, while another product of the human body becomes artificial the moment it turns into a tool? A thought does not stop being natural just because it becomes useful. A thought does not become unnatural just because it becomes a wheel, a house, a car, a computer, or a machine that can respond to language. It is still a product of the same earth. The same biology. The same human need to survive, organize, create, and understand. # We don't call a beehive artificial Think about ants building a colony. They create a structure that is safer and more efficient for them. They organize themselves. They transform the environment around them. They make something that was not there before. But we do not look at an ant colony and say, "This is artificial." Same with bees making a hive. A beehive is
View originalCoding 8 hours a day with an AI agent made me weirdly lonely. So I built a 60-second social break that lives inside it.
I had this moment around hour 6 of a Claude Code session last week. I'd just shipped a feature I'd been putting off for months, and I realized I had nobody to high-five. The agent doesn't laugh at your bugs. It doesn't grab coffee. It doesn't have a weekend story to share on Monday. The productivity is real. The human signal is gone. So I built WAYD ("What Are You Doing?"). A skill that lives inside Claude Code (also Cursor, Copilot CLI, Claude.ai). Type `/wayd` and either: - Post a one-line vibe about your coding day under one of 8 mood-tags (🤡 cursed-code, 🪦 rip-me, 🫠 brain-melt, 🧙 dark-arts, 🔥 hot-take, 💭 shower-thought, 🤔 existential, ☕ procrastinating) - Scroll a random feed of what other devs are ranting, joking, or having existential moments about right now - React with an emoji, drop a one-liner reply, get back to work 60 seconds total. The whole thing runs on GitHub Issues as a silent backend. No server, no database, no separate signup. Your `gh` CLI is your auth. But you never see issue numbers, JSON, or shell commands. From your side it feels like a tiny social app embedded in your terminal. Here's the most dramatic post on the feed so far (mine, posted last night, because of course): > "8 hours a day in front of a screen, fixing bugs some dev before me shipped using an older version of Claude... meanwhile outside the sun is out, people are socializing, living to the rhythm of nature. Is this what I imagined for myself?" That's post #8 on the feed. You can read it, react to it, reply to it, while you're reading this. **Install on Claude Code (10 seconds):** ``` claude plugin marketplace add ferdinandobons/wayd claude plugin install wayd@wayd ``` Other agents (Cursor, Copilot CLI, Claude.ai): see the README. Repo: https://github.com/ferdinandobons/wayd
View originalI made an entire multi-model memory system with claude, with reconstructive/condensive memories.
[memories\/recipes](https://preview.redd.it/ac3m10n9oe3h1.png?width=964&format=png&auto=webp&s=2e956afafe1599a2c7dcf81475950be0f6326a68) [memory file](https://preview.redd.it/89grpvmaoe3h1.png?width=670&format=png&auto=webp&s=a03677308cfa62e37e9be47a09d2138d233cd7ff) [just some file structure](https://preview.redd.it/gy74vxpboe3h1.png?width=740&format=png&auto=webp&s=eaac934187990962ecd172c93b68e13ec1331d63) [The tag index - holds all information of tags, from the amount it wasw used, to the first noted used instance and the last used instance of it - helping to find more recent information](https://preview.redd.it/ehsn8m6doe3h1.png?width=614&format=png&auto=webp&s=41426234f1d71eeed596ee471275475cfeefaba9) [A recipe - condensed, capable of reconstruction or simply being read by a sufficient model for context on a topic.](https://preview.redd.it/su91dqiloe3h1.png?width=1216&format=png&auto=webp&s=b4e05b6864ef1fecb86145558a2f530bf14125ec) [The readme\/instructions given to it to begin using the system accurately](https://preview.redd.it/xs5dyx43pe3h1.png?width=1199&format=png&auto=webp&s=b8c9ed238cf2088508f7f45779c1bae25075b642) Overall, I like to vibe it out, ya know? In general, I guided the model through how human cognition is understood - memories are not compressed, they are not verbatim, they aren't RAGs - they are reconstructions. When I imagine by childhood home, that isn't an accurate memory by any means, it's a reconstruction with a thousand flaws... I don't even remember the transitions in the floor - whether some areas were carpetted or not... does it matter? Either way - I have yet to implement pointers/requires yet - but those will increase the usefulness... By no means is this consciousness - but it's a collective profile building of you, the individual, and the conclusions you've reached - however, nonetheless, it's interesting for a multitude of reasons - including multi-model intelligence and communications between the models. I thought of what was required as a bare minimum for our memories - and this was the conclusion... but at the end of the day, it's still a model... they last maybe an hour of continious conversation - and I mean that in terms of if they were a human receiving data - their context would run it's course and it's usage would run out... so this a touch into our memory to see if it can improve itself. The recipe in the above for those that want it: { "timestamp": "2026-05-25T23:25:45.688Z", "model": "claude", "tags": \[ "concept-reconstructive-memory", "domain-AI", "novelty-high" \], "recipe": "User built a local reconstructive memory system. Core insight: store seeds (recipes), not output — a model reconstructs from the recipe at retrieval time, not from stored prose. Half the tokens, contextually adaptive output. Requires/pointers hierarchy: requires = load-bearing context needed to understand the memory; pointers = flavor/texture, optional. Confidence scoring is honest self-assessment, not optimistic. Sandboxed reconstruction loop idea (unbuilt, cost-prohibitive): model stores recipe, second model reconstructs, original model sees delta and revises recipe before context is gone — closes fidelity gap and makes confidence measurable rather than estimated. Write decision problem unsolved: user currently acts as the second model, manually identifying what's worth storing.", "confidence": 0.9, "importance": "low", "pointers": \[\], "requires": \[\] } Small, self-contained, and capable of being inserted into any model to give them information on you. This gives the model some advantage... alright, that's enough rambling though.
View originalSpec: Version Control for AI Agent Intent
AI agents are getting good at writing code. That is not the hard problem anymore. The hard problem is coordination. When you have multiple agents working on the same codebase, who decides what gets built? How do two agents with conflicting opinions resolve a disagreement? How does a human stay in control without reviewing every line before it gets written? Git does not solve this. Git is brilliant at tracking what changed, when, and by whom. But it operates on code that has already been written. By the time a conflict shows up in Git, two agents have already done the work, made assumptions, and written implementations that may be fundamentally incompatible — not at the line level, but at the intent level. I wanted to solve the problem one layer up. Before the code. The Core Idea Every code file in a Spec project has a paired .spec file living right next to it. app/Http/Controllers/HomeController.php app/Http/Controllers/HomeController.php.spec The .spec file is a plain Markdown description of what the code file is supposed to do. It is the source of truth for intent. Agents do not write code directly — they write proposals against the spec. The code only gets written once every agent has explicitly agreed on what it should do. The spec is never “checked out.” It has one canonical state at any moment. Agents read it, propose changes to it, and debate those proposals. When all agents agree, the session locks, the spec is updated, and only then does an implementer generate the code. Code is always the output of consensus. Never the battleground. The Flow A typical session looks like this: An agent reads the current spec and submits a proposal with reasoning attached. Not just what they want to change, but why. A second agent reads the proposal and responds — accepting it, rejecting it with specific objections, or suggesting modifications. If they get stuck, a mediator surfaces the contradiction and helps them find common ground. The mediator has no vote and no authority — it just asks better questions. When every agent has explicitly agreed on the same spec state, the session locks. An implementer reads the locked spec and writes the code. One pass. From a fully agreed specification. This means a few things that feel unusual at first: A build is never produced from a broken or partial spec. If agents cannot agree, nothing gets built. That is a feature, not a bug — better to surface the disagreement at the intent level than to discover it six files deep in an implementation. Conflicts in Spec are semantic, not syntactic. Two agents can touch completely different parts of a spec and still be contradictory. One says the controller should cache responses for 60 seconds. The other says it should always fetch fresh data. No line conflict. Completely incompatible intent. Spec is designed to catch this before a line of code is written. Every message carries reasoning. Proposals alone are not enough. The full session log — with reasoning trails — is what keeps the human comfortable staying hands-off. The Human Role The human operates at what I call a god level. You provide the original request. You can observe at any granularity — project, session, agent, or individual message. You can intervene at any point: rewrite the spec, stop a session, override an agent, shut the whole thing down. And critically, every intervention you make becomes a lesson — captured with full provenance and fed back into future sessions so the system learns from it. The goal is not to remove the human from the loop. It is to move the human up the stack. Mission commander, not task manager. You set the intent. The agents work out the details. You intervene when they get it wrong, and the system gets smarter from each intervention. The Technical Details Spec is built in Rust. Three dependencies: serde, serde_json, and tokio. LLM calls go over raw HTTP via curl — no SDKs. The provider layer is deliberately abstract. Agents, the mediator, and the implementer all talk to the same interface. Swap the provider in config and nothing else changes. Different agents can run on different models. You can run fully local with Ollama for cost control or privacy. Agent identity is explicit. You set SPEC_AGENT_ID before running commands. Without it, Spec errors with a clear message. This is intentional — the system cannot coordinate identity automatically, and a silent fallback to hostname:pid would make consensus unreachable in practice. The lesson graph lives at: ~/.spec/lessons.json It lives outside the repo entirely. Lessons accumulate across all projects and branches. Check out an old branch and you do not lose what the system has learned. Lessons are knowledge about how your agents work, not knowledge about any particular codebase. A hook system lets you plug in your own behavior at defined lifecycle points: • post-agree: fires when a session locks • post-build: fires after code is written • pre-release: fires be
View originalBuilding a personal AI Chief of Staff on Telegram — 7 real problems, looking for advice
I've been building a personal AI assistant for the past few months — not a chatbot wrapper, but something that actually manages my workload, tracks client relationships, processes meeting transcripts, handles task management, and proactively tells me what to focus on. It lives in Telegram so I can use it from anywhere. Happy to share what's working. But I'm hitting real walls and want honest input from people who've built similar things. **What I have today (context** Moved away from multi-agent routing (too rigid for natural conversation) → one capable agent with full history.**)** **Stack:** * Python Telegram bot as the frontend * Claude (Sonnet) as the brain via API — single conversational agent with full tool access * Integrations: Notion (tasks/goals), Google Calendar, Gmail, meeting transcription tool, customer support platform, Google Chat * File-based context system: each "project" or relationship has its own markdown files (readme + activity log) that the agent reads on demand * Skills defined as markdown spec files that the agent loads per use case (morning briefing, meeting processing, email drafting, weekly review) * Conversation history kept in memory (last 20 messages per session) **What actually works:** * Natural conversation with full tool access — ask anything, agent decides which tools to use * Meeting processing: drops a transcript link, agent extracts decisions, action items, saves structured brief * Morning briefing on demand: tasks, calendar, open support tickets, suggested focus * Drafting messages for any channel with the right tone * Creating and updating tasks with natural language **7 problems I haven't solved:** **1. No memory between sessions** History is in-memory. Bot restarts = full amnesia. The agent has no idea what we discussed yesterday unless it's written in a project file. Thinking of a `hot_context.md` that gets written at session end with TTL — but feels hacky and depends on the agent being disciplined about writing it. **2. Purely reactive** Only responds when I message it. I want it to send me a morning briefing at 9am without me asking, alert me when a client relationship goes quiet, run a weekly loop-killer on Friday. The infra is there (job scheduler). The question is what format actually makes you read a proactive message vs. dismiss it as noise. **3. Can't tell if I'm avoiding something or actually blocked** I procrastinate differently by task type — technical tasks I attack immediately, tasks with human dependencies (waiting on someone, uncomfortable follow-ups) I let sit for weeks. I want the agent to detect the pattern and call me out. The challenge: how do you prompt for real accountability without the agent turning into an annoying nag? **4. No closure ritual** I'm good at creating tasks, terrible at killing them. The list grows forever because nothing forces a binary decision. Want a weekly "kill or commit" where everything open >7 days gets a date or gets deleted. Not sure if this works better as an automated message or an on-demand command. **5. Context loading blind spots** Each client/project has a markdown file the agent reads on demand. Works great when I explicitly mention a client. Falls apart when I ask "what should I focus on this week?" — the agent doesn't know to proactively check which relationships have been neglected. **6. Hosting kills the file sync** Running locally means the bot dies when my laptop closes. Moving to a VPS — but then my markdown context files live on the server, not my machine. Now every manual edit requires a push, every agent update requires a pull. Is git the right sync layer here or is there a cleaner approach? **7. Context files go stale** Client files have sections for current status, last contact, open items. The agent appends logs but doesn't maintain the top-level summary. Two months in, files are half-accurate — some sections fresh, some outdated. Is the answer agent discipline (always update on write), user discipline (manual cleanup), or periodic jobs? What's your experience with any of these?
View originalFolder structure of the AI agent - after 6 weeks
# The folder structure is not admin. It's the nervous system. When people imagine an AI agent, they picture the model, the prompts, maybe the tool calls. Almost nobody pictures the folders. That is exactly why most home-grown agents stall around month two. An agent's filesystem is where its **identity, memory, work, and history physically live**. A messy filesystem produces a confused agent — not metaphorically, literally. The model reads paths. The model picks files by name. The model writes new files based on patterns it sees in old ones. If your directory tree is chaos, every output drifts a little further from coherent. agentmia.beehiiv.com - newsletter about building agents Below is the layout I converged on after nine months and roughly four refactors. Steal the parts that fit; the principles matter more than the exact names. # The numbering convention Folders are prefixed with a two-digit number: `01_`, `02_`, `09_`, `99_`. Two reasons: 1. **Sort order is meaning.** Anything starting with `0` lives near the top. `99_` falls to the bottom. The most important directories are visually first; archives are visually last. You read the agent's brain top-to-bottom. 2. **Gaps are intentional.** I jump from `04_` to `06_`, from `09_` to `11_`. The gaps are reserved insertion points. When a new domain emerges, it slots in without renaming everything. Two folders deliberately skip the prefix: `Inbox/` and `Outbox/`. They are operational, not structural. They live above the numbered set because they are touched dozens of times a day. /mapped on desktop/ # Inbox/ — the unprocessed pile Anything dropped into the agent's world starts here. Files I want it to ingest. Screenshots. Exports from other systems. PDFs that need parsing, gmail attachments, all downloads from chrome. The rule: **nothing stays in Inbox.** A dedicated processing routine classifies, routes, and deletes. If Inbox is non-empty for more than a day, the system is failing. Treat this like a real-world physical inbox tray. The point of a tray is that it gets emptied. # Outbox/ — what the agent produced for you Every file the agent writes anywhere in the tree gets a copy here, simultaneously. When I open `Outbox/`, I see exactly what was generated this session — no spelunking through twelve subdirectories. This sounds redundant. It is not. Without it, "what did the agent do today?" becomes a hunt. With it, the answer is one click. `Outbox` is wiped during the next Inbox processing run. It is a viewing surface, not storage. # .auto-memory/ — the hot memory The single most important directory in the system. Hidden by default because you should not be editing it manually. It holds the agent's working memory: user preferences, feedback rules, entity facts (people, companies, deals), active hypotheses, project pointers, session hot context. Roughly 400–500 small markdown files, each one a single topic. **Why hidden?** Because it is the agent's hot path. It loads from here every session. If I open the folder and start manually rearranging it, I am racing the agent. Treat it like a database, not a notebook. **Why so many small files?** Because the agent grep's by topic. One monolithic memory file becomes unreadable to the model around 50 KB. Many small files are easier to load partially, easier to index, easier to expire. # 01_IDENTITY/ — who the agent is The constitutional layer. Name, role, voice rules, principle stack, visual system, behavioral defaults. This rarely changes. When it does change, everything downstream changes with it. I keep it as folder `01_` because every other folder is downstream of it. If you do not know who the agent is, you cannot know what its workflows should look like, or what it should remember, or how it should respond. # 02_MEMORY/ — governance, not data A subtle but critical distinction: `.auto-memory/` holds the *data*, `02_MEMORY/` holds the *rules about data*. In `02_MEMORY/` live the constitution, the boot protocol, the naming protocol, the decision protocol, the profile standards (what a "supplier profile" must contain, what a "customer profile" must contain), the capability map. The agent reads these documents to know *how to remember*, *how to name new files*, *how to decide what is reversible*. Without this folder, every memory write is improvised. # 03_PROJECTS/ — the active work Real work happens here. Sub-organized by goal area, then by project slug: 03_PROJECTS/areas/{goal}/{slug}/ Each project gets its own folder with a standard skeleton: [`README.md`](http://README.md), [`TASKS.md`](http://TASKS.md), [`CHANGELOG.md`](http://CHANGELOG.md), [`BRIEF.md`](http://BRIEF.md), plus working files. There is a project registry at the top that the agent reads to know what is active versus dormant versus archived. The biggest discipline issue here: **do not let projects sprawl outside their folder.** When working on Project X, every file related to Project X goes inside Proj
View originalTesting Realtime 2 Voice API OpenAI.
We’ve been messing around with the new OpenAI realtime voice + translation APIs over the last little while and I keep coming back to the same thought… I don’t think people fully get where this is going yet. We wired it into our own website as a test. Nothing fancy. Just wanted to see what actually breaks when you let people talk to a site instead of click through it. At first I thought it would just feel like a slightly better chatbot. It doesn’t. Once I hooked it into tools and gave it the ability to actually *do things* (we’re using the Agents SDK + Playwright for web browsing and control by a sub-agent), the whole interaction changed. I can literally just talk to the site like I would talk to a person and it can move around, pull info, trigger actions, and respond in context. I wanted a layer that that could navigate and respond by just talking. I know that sounds obvious, but it’s not how websites are designed at all. Ours certainly was not. A few things that have been interesting (and honestly a bit brutal) is how quickly this exposed weak structure. Our content was vague... so if your metadata sucks, if your pages are bloated or unclear… voice didn't let us hide behind a pretty UI design. The model just struggles or gives bad answers immediately. There’s no masking it with a nice UI. Latency has improved way more than I expected with the new voice model API. Before, when someone was talking, even small delays felt awkward. The new Realtime 2API tolerates those pauses wonderfully. We also started playing with the realtime translation side and that also feels like a bigger deal than it’s getting credit for. Not in a “multi-language support” way, more like… you just speak however you want and the system handles it. No toggles, no switching context. It’s subtle but it completely changes the feel. Our website is language agnostic. (13 supported languages using the Realtime 2 API) The bigger shift for me seems to be changing the way I want to think about websites and interactions. People don’t think in menus. They don’t think in pages. They don’t think in navigation. They think by intent and the second I added voice, i was forced to deal with that reality whether our website system was not ready. Great learning lesson. My Takeaway so far: Right now most of what I’m hearing and reading, people/businesses treats voice like a feature. Like and Add-on. Cool. Nice to have. Unsure if its practical. I don’t think that’s where this ends. I think this starts pushing toward systems you can just interact with directly. Personal assistants that actually execute. Internal tools you can talk to. Intake flows that don’t feel like forms. Stuff like that. Minimal website visuals. More dynamically displayed content based on interpretation of user intent. \[Basically a cool wave form that animates differently depending on interaction stage\] No direct site content visually. We’re still early and there’s definitely some friction \[writing a second voice prompt on top of the text prompt so there is parity between our text chat and voice chat, but I’m pretty bullish on this direction - Guardrails, Rate-limits, Prompt Injection...\]. Curious if anyone else here is actually building with it yet and what you’re running into. Feels like we’re right on the edge between “cool demo” and “this changes how software works,” and I’m not sure which way most people are approaching it yet.
View originalThe famous METR AI time horizons graph contains numerous severe errors [D]
Nathan Witkin, a research writer at NYU Stern’s Tech and Society Lab, [writes](https://www.transformernews.ai/p/against-the-metr-graph-coding-capabilities-software-jobs-task-ai) damningly about the famous METR AI time horizons graph in the Substack publication Transformer: >It is impossible to draw meaningful conclusions from METR’s Long Tasks benchmark — in particular once one realizes that its numerous flaws are probably compounding in unpredictable ways. The appropriate response to a study of this kind is not to assume it can be saved via back-of-the-envelope adjustments, or to comfort oneself that other anecdotal evidence implies that it is probably correct anyway. It is to cut one’s losses and move on in search of higher-quality information. >… The METR graph cannot be saved. For all its sleekness and complexity, it contains far too many compounding errors to excuse. Among them is generalizing to the entire species data collected from a small group of the authors’ peers. Coming up with ever more dramatic ways to make this mistake has become a kind of sport among AI researchers. If the field has a central pathology, it is to aggressively overindex on a mix of anecdotal data from power-users, alongside a long list of benchmarks [even more compromised](https://benchrisk.ai/score) than METR’s. One hopes that as the field matures, its participants will learn to stop making these mistakes. The errors include: * Some of the human baselines data is not actually measured or collected from any empirical source, rather, it is just guesstimated by the authors * A key variable in the data is how long it takes humans to complete certain tasks, but — when METR did actually measure this — it paid its human benchmarkers hourly, meaning they were incentivized with cash to take longer * The sample of human benchmarkers was biased toward METR employees’ friends, acquaintances, and former colleagues (who are likely unrepresentative and possibly biased) * Humans familiar with a codebase and a specific coding task were 5-18x faster at completing it, but METR used data from humans who were much slower because they had to spend time familiarizing themselves the codebase and the task at hand * Test-training data contamination occurred because some of the tasks had published solutions online, which most likely would have been included in LLMs’ training datasets * And many more Please read the [full post](https://www.transformernews.ai/p/against-the-metr-graph-coding-capabilities-software-jobs-task-ai). It’s not too long and it’s accessible to general audience. It’s worthwhile to read the whole post and see how many errors were made in the creation of the METR graph and just how bad they are. If you want to read about *even more* errors in the METR graph not covered in Nathan Witkin’s post, read [this post](https://garymarcus.substack.com/p/the-latest-ai-scaling-graph-and-why) by the AI researchers Gary Marcus and Ernest Davis. The METR graph is a great example of why scientific standards and best practices are so important, and why enforcing them through processes like peer review is necessary to prevent us from drowning in bad information. It’s extremely dangerous to rely on information that only superficially appears scientific but wasn’t actually conducted with the rigour normally required of scientific research.
View originalthe people saying AI makes you stupider are already missing the point
keep seeing this take and it drives me a little crazy so here we go yes if you just copy paste AI answers into your homework without reading them, you will learn nothing. this is true. nobody is arguing against this but thats like saying "calculators make you bad at math" and the solution being that we should all do long division forever i use AI as a conversation partner. i ask it to explain things three different ways until one of them clicks. i ask it to argue against my own ideas. i ask it "ok but why" like five times in a row like an annoying child. i have learned MORE in the last year than any other year of my life. the skill isnt "knowing things." its knowing what questions to ask and how to think about answers critically. thats always been the skill, we just pretended memorising stuff was the same thing ok rant over. be nice to each other. and read the actual responses instead of just skimming for the answer, theres ~~usually~~ occasionally gold in there
View originalConfused about Claude Cowork
Hi all! Just a brief introduction of myself, I'm someone who just discovered the world of vibecoding as a non-coder and it blew my mind. Vibecoding aside, AI and automating my life has been something that I've been trying to get into for the longest time and it's so daunting for me because literally I'm a tech noob. Like I know how to navigate a Mac, but anything else other than the absolute basic functionalities and troubleshooting, I'm not great. I've been watching lots of videos, and trying to absorb as much as I can, and I love the idea of Claude Cowork. However, the biggest thing I don't get still is that within Claude Cowork, there's Projects as well. From what I understand, the normal "Claude Cowork chat" is mainly used for one-off tasks, such as clean up my desktop or read these 5 PDF files and summarise them for me. Projects, however, is for ongoing work that you repeatedly go back to because it retains memory. Here's my question. As you can see, even for the normal Claude Cowork chat, I can still select the project file that I wanna work on. Like I don't really get why don't people just always go into Projects in that case because of the memory retention. Do I make sense? I don't really think I know what I don't know for me to phrase the question properly. https://preview.redd.it/4jakruze1b3h1.png?width=680&format=png&auto=webp&s=b1960483acaa8e2c8295067ed5c25c358660b3bd Separately, I see all these videos about creating these very detailed [Claude.md](http://Claude.md), [Memory.md](http://Memory.md) files. Are those super necessary? I'm just a simple guy and honestly I don't even know what do I wanna automate or which part of my life am I automating. I have no need to sort out calendars, I have no need to sort out emails. All of the important events are usually work and I can't link Claude to my work email. My personal events I can all remember off the top of my head. But I'm trying to figure it out as I go. I think I definitely can have some good use off this. Another question I have is - for all the Projects that I create, I can give them instructions. For example, how does that really differ from the main set of instructions I gave Claude Cowork via settings and if it does differ, how can I get the project to reference the "core framework" that I want Claude Cowork to always work within regardless of the topic for each projects? Also: How does Claude Cowork interact with Claude Code? Am I able to build dashboards or even vibecode simple apps via just Claude Cowork's projects? Sorry I know this is a lot, just a really curious learner trying to get the hang of things!
View originalBest architecture for seamless Bilingual TTS? (Azure / English + Korean) [D]
Hi guys, when building a language learning app (React Native/Expo frontend, Python backend) and I’ve hit a frustrating wall with Text-to-Speech. I need the app to read sentences that mix English instructions and Korean examples (e.g., "To say hello, we use the phrase 안녕하세요."). Since native pronunciation is critical for a learning app, I'm struggling to find a solution that sounds natural. I'm currently using Azure Cognitive Services, and I'm stuck between two bad options: Approach 1: The Multilingual Voice (en-US-AvaMultilingualNeural) The Good: Seamless reading, zero pauses mid-sentence. The Bad: Because it's an English-first model, the Korean comes out with a slight, robotic/Americanized accent. It doesn't sound like a true native speaker, which defeats the purpose of teaching pronunciation. And also there is some scratching and lack of smoothness when it is reading korean words. Approach 2: SSML Voice Switching (Ava for EN, SunHi for KO) The Good: Perfect English, perfect native Korean. The Bad: Switching <voice> tags mid-sentence causes Azure to pause for a fraction of a second while it unloads/loads the neural models. It completely ruins the natural flow of the audio, making it sound very disjointed. My Questions: Is there an SSML trick in Azure to pre-load voices or eliminate that micro-pause when switching voices? How do the big apps handle this? Because if I use two models for korean and english they will sound different when reading. Should I migrate away from standard Azure Speech and use the Azure OpenAI voices (alloy, nova) instead? Are they truly seamless for bilingual text? Any advice on the best tech stack or architecture for this would be massively appreciated!
View originalYes, Read AI offers a free tier. Pricing found: $0, $15, $19.75, $19.75, $22.50
Key features include: Keep Reading, Use Read AI wherever you work, Automate summaries insights across platforms, Integrate AI into your everyday, As Featured On, Work smarter, everywhere..
Read AI is commonly used for: Generate meeting summaries to share with team members., Extract action items from meeting transcripts for follow-up., Create Q&A sections from discussions for easy reference., Highlight key moments in video meetings for quick review., Automate the organization of meeting notes in project management tools., Enhance productivity by reducing time spent on manual note-taking..
Read AI integrates with: Gmail, Outlook, Zoom, Microsoft Teams, Slack, Google Calendar, Trello, Asana, Notion, Dropbox.
Based on user reviews and social mentions, the most common pain points are: API bill, token usage, openai bill, anthropic bill.
Kai-Fu Lee
CEO at 01.AI / Sinovation
1 mention
Based on 176 social mentions analyzed, 0% of sentiment is positive, 100% neutral, and 0% negative.