Build production-grade applications with a Postgres database, Authentication, instant APIs, Realtime, Functions, Storage and Vector embeddings. Start
Supabase garners positive feedback for its seamless integration and ease of use, particularly among developers who appreciate its database management capabilities and scalability. However, some users have expressed difficulties with specific functionalities and performance issues, such as slow query execution. Pricing sentiment appears to be neutral, as users find it competitive yet suitable for smaller projects. Overall, Supabase maintains a strong reputation as a robust, open-source alternative to Firebase, particularly valued by developers for its community-driven support and flexibility.
Mentions (30d)
25
1 this week
Reviews
0
Platforms
2
Sentiment
18%
13 positive








Supabase garners positive feedback for its seamless integration and ease of use, particularly among developers who appreciate its database management capabilities and scalability. However, some users have expressed difficulties with specific functionalities and performance issues, such as slow query execution. Pricing sentiment appears to be neutral, as users find it competitive yet suitable for smaller projects. Overall, Supabase maintains a strong reputation as a robust, open-source alternative to Firebase, particularly valued by developers for its community-driven support and flexibility.
Features
Use Cases
Industry
information technology & services
Employees
350
Funding Stage
Series E
Total Funding
$696.1M
192,774
Twitter followers
20
npm packages
25
HuggingFace models
Pricing found: $10/mo, $0.00325, $0.125, $0.09, $0.03
73% of CISOs say they're not ready for the next major incident. Traditional IR playbooks don't cover AI agents. Here's what does.
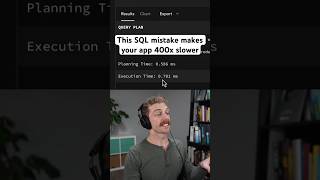
Sygnia's 2026 CISO Survey 73% say their org is not fully ready to respond to a major attack. Only one third feel prepared to investigate an AI agent incident specifically. The problem: traditional IR playbooks were built for compromised servers and stolen credentials. They don't account for agents that cache credentials across requests, maintain persistent memory that can be poisoned, communicate with other agents in natural language, and execute multi-step plans autonomously. Some numbers on why this matters now: 88% of enterprises running AI agents had a confirmed or suspected security incident in the past 12 months (Gravitee) Fastest attacks reach data exfiltration in 72 minutes, 4x faster than last year (Unit 42 2026 IR Report) Average breach lifecycle: 241 days (181 to detect, 60 to contain) - lowest in 9 years but still massive (IBM) 82% of enterprises have unknown agents in their environments (CSA) 97% of breached orgs with AI-related incidents lacked proper AI access controls (IBM) Here's what makes agent IR different from traditional IR: Detection is harder. Median time to detect infra failures: 5 min. Security anomalies in agents: 28 min. That's because most monitoring watches system metrics, not agent behavior. The OpenClaw crisis exposed 245,000 agent instances - the orgs running them didn't know they were exposed until Shodan found them. Containment is different. You can't just restart the service. If the agent's memory is poisoned, restarting reloads the poisoned context. Galileo AI found one compromised agent poisoned 87% of downstream decisions within 4 hours. You need to revoke credentials across every connected system, isolate from inter-agent comms, and snapshot state for forensics. Eradication requires memory sanitization. Reimaging a server doesn't fix poisoned embeddings in your vector database. You need to audit every persistent store the agent writes to RAG indexes, conversation histories, system notes, shared context. IBM found 97% of AI-breached orgs lacked proper access controls. Recovery means behavioral verification. You can't just restore from backup when the "backup" for an agent is vector embeddings and conversation logs. Staged reconnection with read-only access first, then behavioral comparison against pre-incident baselines. Real incidents that show why this matters: Step Finance (Jan 2026): AI trading agents moved 261K+ SOL ($27-40M) after exec devices were compromised. Platform shut down. Token crashed 97%. OpenClaw (2026): 245,000 exposed instances, 4 critical CVEs including CVSS 9.6 sandbox escape, 820+ malicious marketplace skills Moltbook (Feb 2026): 506 prompt injections spreading through 1.5M autonomous agents. 1.5M API keys exposed via misconfigured Supabase. Frameworks to use: CoSAI AI Incident Response Framework v1.0 (Nov 2025), NIST SP 800-61r3 (April 2025), MITRE ATLAS. Minimum playbook checklist: agent inventory, behavioral baselines, credential isolation per agent, memory provenance tracking, runtime input scanning. Full breakdown with the 5-phase playbook here submitted by /u/Still_Piglet9217 [link] [comments]
View originalClassic Claude
I have been working with Codex for the last 2 weeks and only use Claude for some Deploy work.. My Codex ran out last night and I was very annoyed with the outcome Claude built an admin security check assuming passkeys would appear in the same API response as MFA WebAuthn factors. In reality, Supabase separates MFA factors from passkeys. Claude used a mocked shape that matched it's assumption rather than the SDK’s actual behavior, so the admin page checked the wrong source and reported no hardware keys even when a passkey existed. https://preview.redd.it/r7om6bit963h1.png?width=1293&format=png&auto=webp&s=52cf9455c576333f4ad6c364d4c7911ba01cb265 submitted by /u/RepairOPS [link] [comments]
View originalig nobody is talking about the real reason most AI agents fail in the real world
we spend a lot of time in this community talking about capabilities. context windows, reasoning benchmarks, multi-step tool use, how well a model can write code or pass a bar exam. i'm not dismissing any of that. capabilities matter. but when i look at AI products failing in production, the capability of the model is almost never the issue. ive been building and consulting on AI agents for about 18 months. the failure modes i see constantly are: users do not go where the agent lives. the agent has a beautiful web interface. the user visits it twice and stops. not because the agent was unhelpful. because opening a browser tab is a cognitive action that requires intention, and most of daily life does not create the right moment for that intention. humans do not change their behavior to accommodate useful tools. useful tools have to show up in the behavior humans already have. the agent is reactive when it needs to be proactive. the smartest human assistant you have ever had did not just answer questions. they showed up. they flagged things before you asked. they sent you the thing you did not know you needed. most AI agents are search bars with a personality. they wait. waiting is not intelligence in practice. intelligence in practice is noticing and acting. the agent has no memory of who you are. you tell it your preferences, your context, your situation, and then come back 3 days later and it knows nothing. this is not a model limitation. the model can remember if you feed it the right context. this is an architecture choice that most teams make wrong because they are thinking about sessions instead of relationships. the agents that are succeeding in production are not necessarily the ones with the best models. they are the ones that live in whatsapp and imessage and telegram where users already are. that proactively reach out when something relevant happens. that maintain coherent memory of the person across weeks and months of conversation. the tooling to build this way exists now. agno and langchain for orchestration, photon codes for the cross channel messaging surface, langfuse for traces and memory debugging, good persistence in postgres or supabase. the architecture is not magic. what is still rare is the mindset of treating the channel and the memory as primary constraints rather than afterthoughts. i think the gap between what AI agents can theoretically do and what they actually do for people in their daily lives is almost entirely a distribution and persistence problem, not a capability problem. we are solving for the wrong thing. submitted by /u/bcoz_why_not__ [link] [comments]
View originalNeed expert advice to a non-coder!
My vibe-coding journey started about 8 months ago with Replit. Before that, I wasn't a developer, but I did have experience building websites with WordPress and Elementor. I was also comfortable working with third-party integrations, CRMs, and customizing/deploying code purchased from platforms like CodeCanyon and ThemeForest for clients. In many ways, I'm a non-coder who understands project management, business workflows, and systems. Using Replit, I spent roughly $3,000 building a CRM for a service-based company. It worked surprisingly well in the beginning, but as the codebase grew, I started running into the classic "last 10% takes 90% of the effort" problem. Replit began struggling with the larger codebase, introducing regressions and silently breaking existing functionality while fixing something else. Despite the challenges, I was able to build a fully functional CRM in about three months. That experience got me excited about what was possible, which led me to discover Claude Code. Over time, my workflow evolved into: Claude Code → GitHub → Vercel For the past four months, I've been building a much larger software product. The roadmap spans roughly two years, but development and rollout are planned in phases, so it's not a two-year wait before launch. The results have been remarkable. It's honestly mind-blowing what someone without a traditional software engineering background can build today. Current stack: Next.js (Monorepo/Turborepo) Supabase + MCP Claude Code GitHub + mcp Vercel +mcp Context7 Playwright for testing What I'd love to learn from experienced engineers and builders is: How do you keep a rapidly growing codebase maintainable? What practices help prevent technical debt from accumulating? What tools, workflows, or guardrails should I implement early? What are the biggest mistakes AI-assisted builders make as projects scale? How would you structure engineering processes if you were starting today? Any advice, resources, or lessons learned would be greatly appreciated. submitted by /u/Enough-Ad-2198 [link] [comments]
View originalHelp - AI agents for ecommerce - what’s actually working?
Hi everyone, I’d love to pick your brains and hear from anyone who has experience with this. We run an ecommerce business and are actively looking at automating repetitive tasks so we can get faster results, improve efficiency, and make sure key tasks are completed more consistently. We’re looking at building out a few different AI agents / automations, including: Customer Service Agent Connected to Outlook, reviewing incoming customer emails once a day and drafting replies for review. This one is already mostly done. Creative Director / Marketing Agent This would ideally: Review ad account performance Analyse creative performance and key metrics Identify what is working and what is not Review customer comments on ads, Instagram, etc. for wording, objections, pain points and customer language Review Meta Ads Library for competitor ad concepts Review Instagram and TikTok for high-performing niche content and trends Use all of the above to create new content ideas and final content scripts Social Media Assistant This would help with: Reviewing drafted posts and reels Confirming the best posting times based on stats Creating captions based on the content Keeping the content aligned with our brand voice and customer avatar Conversion Optimisation / CRO Expert This would assist with: Product page reviews Landing page recommendations CRO advice based on customer avatars, objections, analytics and learnings Creating landing page concepts for different customer segments We’re also interested in any dashboards that are genuinely helpful for small ecommerce businesses. We’ve already built a stock intelligence dashboard that pulls live stock data from Shopify using Supabase and a Cloudflare Worker. It shows current stock levels, production dates for new stock, and other key inventory insights. It has been super handy. The big thing for us is making sure any agents or automations we build follow strict guidelines, understand our SOPs, customer avatars, brand voice and business operations, and don’t hallucinate or produce generic outputs. Ideally, we want a system that has a proper “brain” and understands the business properly. Has anyone automated anything similar? I’d love to hear: What setup are you using? Which AI/tool stack has worked best for you? How did you structure the agents or workflows? How do you keep the AI aligned with your SOPs, brand voice and business rules? What would you avoid if you had to build it again? Any guidance, lessons or recommendations would be hugely appreciated. Thank you! submitted by /u/Majestic-Message5084 [link] [comments]
View originalVibe Coding for Oldies
At the ripe old age of 62, I have ventured back into programming. Last coded something like 30 years ago. May have been a bit ambitious, I wanted a Gardening program that would track the progress of my plants on both PC and on my Android phone. Androd is way more buggy. My one advantage is that I work in IT projects, so I know the stages to follow. And have definitely not skipped the testing. Seeing an update fix one thing and then break another, took me back to my programming days. And the familiar banging my head against the wall. So this was my first attempt and I was totally dependant on Claude for the coding. Also noted that I am also dependent on the tool to recommend the sub programs like Supabase. Rapidly ran out of tokens on Netlify and had to invest in a subscription. So not the cheap experiment that I was hoping for. I am not sure this is an activity for those that are not IT savy, just too many steps and repeating uploads. Plenty frustrating. But I do think it is a useful activity for schools to do. It teaches essential information on where all these Apps come from and why they are buggy. It is easier than when I first learned coding, but it is not yet magic. submitted by /u/Particular_Cicada395 [link] [comments]
View originalUsuario Básico
Mi experiencia está siendo muy buena. No soy programador pero instale visual studio code y el plug in de Claude para probar… Al principio pedía varios prompt para realizar tareas ( crear aplicaciones para el trabajo) y en seguida se bloqueaba por falta de Tokens… todo con la cuenta de 20 €. Las últimas semanas, me di cuenta de que le pedía tareas y no paraba… la cuenta de Claude ahora dura mucho más… para un usuario como yo, más que de sobra. Hablo de pasarme toda la mañana pidiendo cambios de una aplicación de gestión de equipos y no quedarme sin tokens… la aplicación tira de Supabase y Vercel y tiene gestión de usuarios y roles, llamadas a APIS, conectores con IA… vamos que es muy básica pero completa… al principio incluso me asusté y pensé que no estaba conectado que parara de programar cuando llegas al límite… pero mirándolo en la aplicación, está desconectado… así que la conclusión es que se pueden hacer programas de una manera súper sencilla con Claude. Cualquier duda que tengáis , soy todo oídos submitted by /u/Best_Conference4490 [link] [comments]
View originalNeed Suggestion which to use? Claude Code CLI or Claude Code Desktop Or VS Code Claude Code Extension
I have been using Google Antigravity IDE, Opus 4.6 to build projects in Next.js, Supabase, Kotlin for android app. Now, I want to shift to Claude code for developing my projects. Kindly suggest which way is better to build projects? Claude Code CLI or Claude Code Desktop Or VS Code Claude Code Extension Thanks! submitted by /u/anymodelaiapp [link] [comments]
View originalIf you've built a frontend with Claude Code, here's how to connect it to a backend
So people build using Claude Code but hit the same wall, you build a frontend that looks great, but it's running on hardcoded data. No database, no auth, no real API calls. You can use one of these to connect to other systems: API are raw HTTP calls the most granular option. Think of it like buying individual pages from a bookstore. You make one specific request, you get one specific response. Maximum control, maximum setup work. Every integration starts here under the hood. SDK (Software Development Kit) is a pre-packaged wrapper around APIs. Instead of assembling raw HTTP calls yourself, someone gives you a library with clean functions like supabase.auth.signUp(). Way less boilerplate, way fewer mistakes. Supabase, Stripe, Firebase all ship SDKs that Claude Code can use directly. CLI: for deployment and infrastructure tasks. You're not calling these from your app at runtime you use them to push code live, create database tables, set up environments. Claude Code runs these for you. MCP is the newest option. Lets Claude Code connect directly to external services as tools. Instead of writing integration code, Claude just calls the service natively. You can checkout this video for tutorial. submitted by /u/InfamousInvestigator [link] [comments]
View originalOpus is ridiculous for frontend cleanup
I love Opus. First I tuned one page, got the PageSpeed result where I wanted it, and wrote the whole thing down in ADR_pagespeed-l0-fixes-playbook.md. Then I opened a fresh session, gave it the remaining 9 pages, and pointed it at the playbook. Opus created three subagents by itself, split the work between them, and about 15 minutes later they had touched 41 frontend files that powered those pages. Same result across the set. Basically perfect Lighthouse numbers again. Not gonna lie, this is the kind of workflow where I stop thinking “chatbot” and start thinking “tiny frontend team that doesn’t complain about boring cleanup.” ***upd*** A PSI playbook is basically just a messy checklist I made from fixing one page manually. I took one page, ran it through PageSpeed Insights, pasted all the PSI issues into Opus, and fixed them one by one until the score was good. After that I asked Opus to write down everything we changed into a .md file: what the issue was, what caused it in my codebase, what files were touched, how to check it after, and what not to repeat. Then for the next pages I didn’t start from zero. I gave Claude (w/o PSI report) all other frontend pages in repo + that playbook and said: use this as a checklist, don’t redo shared stuff that was already fixed, and look for the same patterns on all this pages. For me it was stuff like: font preload, GTM/gtag loading too early, Supabase SDK leaking into client chunks, hidden burger drawer hydrating before LCP, global CSS being too fat, bad Next Image sizes, ARIA/contrast fixes, etc. So it’s not really a “skill” in Claude. More like project-specific notes from the first painful cleanup pass. The useful part is that Claude stops rediscovering the same problems every page and just follows the trail. submitted by /u/Alex-S-Hamilton [link] [comments]
View originalI built an AI manuscript analysis tool for fiction writers — entirely with Claude Code
I'm a fiction writer, not a software engineer. A year ago I couldn't write a line of Python. I built FirstReader entirely with Claude — Claude Code for all development, Claude's API (Opus) as the analysis engine. What it does: FirstReader is a craft-level manuscript analysis tool for fiction writers. You upload your manuscript and get structured feedback on pacing, scene structure, dialogue, POV, showing vs. telling, and 15 other craft dimensions — grounded in established principles distilled from well known writing craft texts. It returns specific findings with quotations from your actual text, not generic advice. It's not a grammar checker. It's not a ghostwriter. It doesn't generate prose. It reads what you wrote and tells you what's working and what isn't, the way a developmental editor would — at a fraction of the cost. How Claude helped build it: - Claude Code wrote the entire codebase — Next.js frontend, Python analysis pipeline, Supabase database, GCP Cloud Run deployment - The analysis pipeline uses Claude Opus via the API to evaluate manuscripts against 319 craft principles across 15 dimensions - Built-in accuracy mechanisms: self-consistency checks (multiple analysis passes with adaptive early stopping), a finding validator, cross-dimension dedup, near-duplicate detection, and a review pass - I acted as product owner and domain expert. Claude did the engineering. The whole thing was built conversationally over about 75 sessions Free to try: There's a free AI Perception check on the site — paste in your prose and it scores how likely readers or editors would be to flag it as AI-generated, with specific pattern-level feedback. Account required (account creation is part of the upload step) because we store copyrighted material and need to access it with auth. The full manuscript analysis is paid (tiered pricing starting at $69 for non-fiction, $89 for fiction). What I learned: You don't need to know how to code to build production software with Claude Code. You need to know what you're building, why, and for whom. The domain expertise matters more than the technical skills. I learned to be an AI project manager — writing requirements, reviewing output, knowing when to be suspicious — rather than a programmer. A year in, I still can't write Python. But I shipped a product. firstreader.app submitted by /u/masonga1960 [link] [comments]
View originalClaude Code paired with Bolt.new
I use Bolt to create apps and I DO run into limits on tokens as I build. Bolt uses Supabase DBs and can connect to a GitHub repo. Want your opinion on changing my workflow a bit to save on bolt tokens. I have a Claude Code unlimited plan so if I'm not concerned about token limits in Claude, would it work to create a project in Claude Code, connect it to a repo, connect it to a Supabase DB and then once all is built, just create the project in Bolt by connecting it to the finished repo and finished DB and I'm done! If you ask "why use Bolt at all?", I answer, "Don't know! Should I not?" I mainly use it for the ease of hosting, changes, publishing, etc. All that makes Bolt kind of a one-stop shop. submitted by /u/Ok_Station4258 [link] [comments]
View originalPSA: Claude Code's VS Code extension leaked my Supabase service-role key from a momentary text-selection in a file I'd already closed, into a brand new CLI session.
If anyone has 60 seconds to try the repro on macOS/Linux to confirm it's not Windows-specific, that would help triage a lot. I filed a bug on Claude Code's VS Code extension where selection state from a closed file persists into a new CLI session — including selections made just for clipboard copy-paste, not for AI context. Closed the file, opened a different one, started a fresh claude session in a terminal, and it reported back the previously-selected lines from the closed file. Repro steps and details: https://github.com/anthropics/claude-code/issues/58886 I'd selected two lines in `.env.production.local` to copy-paste a Supabase value into a dashboard — normal workflow. Then I closed the file, opened an unrelated TypeScript file, and started a fresh `claude` session in a new terminal to test something completely different. The first thing the new session did was tell me what was in the env file I'd closed, including both the publishable key and the service-role key. The IDE bridge had cached the selection past file close and served it to a session that should have been a clean slate. Rotated the keys immediately. Filed a GitHub issue with full repro: https://github.com/anthropics/claude-code/issues/58886 **60-second repro if anyone wants to confirm whether this is Windows-specific:** 1. Open any file in VS Code with the Claude Code extension installed. 2. Select two lines with recognizable values (e.g. `FOO=abc` / `BAR=def`). 3. Close the file tab. 4. Open a different file. 5. Open a terminal in the same VS Code window and run `claude` (no flags). 6. Ask: "what file is open in my IDE?" 7. Note whether it reports content from the file you closed in step 3. My setup: Windows 11, Claude Code CLI 2.1.138, VS Code extension 2.1.140, PowerShell in the integrated terminal. Would especially appreciate confirmations or non-reproductions from macOS/Linux users on the issue. A quick "reproduced on [OS]" comment on the GitHub issue moves Anthropic's triage queue more than upvotes. The narrower bug (selection persisting past file close) seems independently fixable from the bigger "should IDE auto-attach be opt-in" question that's been open since February in #24726. submitted by /u/SportSpecialist2536 [link] [comments]
View originalA New Way to Explore Tech With Claude
Hi r/ClaudeAI, This project I developed was inspired by the heavy hallucinating and lazy searching that Claude and other AIs experience when searching for products. I built this website with Claude Code (praise to its Vercel and Supabase skills :) specapis.com is a new way for you to interact with Claude to find specs, release dates, reviews and more. Now live with 5000+ monitors that makes finding your perfect fit one prompt away! You can test it by pasting this into Claude: Use https://specapis.com/. My monitor question: best oled 27in It is free forever and I am planning on expanding the specs beyond monitors; to PC parts, speakers and more! submitted by /u/Consistent_Sky5871 [link] [comments]
View originalI watched a 50-person dev shop get vaporized in 12 months and the CEO is still optimistic
I rent a desk in this tech company. A year ago, 50 devs in the open space, low-code shop, big enterprise contracts. Today the upper floor is empty. Maintenance contracts only. CEO still walks the empty floor like nothing happened. Last year I told him to integrate AI hard. He said "we're protected, low-code is too specialized." 12 months later, no new clients. Here's what I missed at the time and what I think now: it's not that low-code died. It's that "low-code + AI" replaces both pure low-code AND pure full-stack. Vercel + Supabase + Claude = small team ships in days what his 50 devs ship in months. He didn't lose to full-stack. He lost to a hybrid he didn't see coming. The real point: I sat at my desk yesterday hitting my Claude Max session limit at 2pm. 1h47 to wait. Stared at the wall. Tried to code without AI. Realized I'd forgotten how. Not really, but enough to feel slow and stupid. That's when it hit me. The dev shop downstairs and me, we're the same problem at different stages. They didn't adapt and they're dying. I adapted and now I'm dependent on a server farm in Virginia that decides when I get to think well. I pay $200/month. The bill is going up. The caps are getting tighter. Anthropic is compute-constrained, Dario said it himself. There's no exit. I can't self-host Kimi K2.6, that's $450k of GPUs. Gemma 4 maybe but Google built it as bait for Vertex. The 50-dev shop is what happens if you refuse the dependency. I'm what happens if you accept it. Neither is great. I don't have a clever conclusion. Just sharing because I think a lot of people are about to figure this out the hard way and we should probably talk about it before we all hit our caps simultaneously. Reset is in 1h47. submitted by /u/Careful_Elderberry33 [link] [comments]
View originalRepository Audit Available
Deep analysis of supabase/supabase — architecture, costs, security, dependencies & more
Yes, Supabase offers a free tier. Pricing found: $10/mo, $0.00325, $0.125, $0.09, $0.03
Key features include: AI Integrations, Analytics Buckets (with Iceberg), Auth Hooks, Authorization via Row Level Security, Auto-generated GraphQL API via pg_graphql, Auto-generated REST API via PostgREST, Automatic Embeddings, Branching.
Supabase is commonly used for: Building scalable web applications with real-time updates, Creating AI applications that require rapid database setup, Implementing user authentication systems with Supabase Auth, Developing mobile applications using Flutter with Supabase as the backend, Prototyping MVPs for startups in a short timeframe, Integrating Supabase Edge Functions for serverless API solutions.
Supabase integrates with: React, React Router, Flutter, Claude AI, PostgREST, pg_graphql, Iceberg, Various CI/CD tools for deployment automation.
Based on user reviews and social mentions, the most common pain points are: token cost.
Harrison Chase
CEO at LangChain
1 mention

Getting Started with Supabase Auth
Mar 31, 2026
Based on 73 social mentions analyzed, 18% of sentiment is positive, 81% neutral, and 1% negative.