Test automation tool - testRigor. Automated software testing for end-to-end test cases using plain English. Looking for software testing tools? Contac
TestRigor receives high praise from users on g2, with strengths highlighted in its efficiency and effectiveness for automated testing, as evidenced by multiple 5-star ratings. Some users, however, express moderate dissatisfaction, as seen in a few 3/5 ratings, though specific complaints are not detailed. Pricing sentiment appears to be positive, with no major complaints noted regarding costs. Overall, TestRigor enjoys a strong reputation as a reliable tool for automating tests, with users appreciating its AI capabilities despite minor grievances.
Mentions (30d)
15
1 this week
Avg Rating
4.7
20 reviews
Platforms
2
Sentiment
24%
11 positive

TestRigor receives high praise from users on g2, with strengths highlighted in its efficiency and effectiveness for automated testing, as evidenced by multiple 5-star ratings. Some users, however, express moderate dissatisfaction, as seen in a few 3/5 ratings, though specific complaints are not detailed. Pricing sentiment appears to be positive, with no major complaints noted regarding costs. Overall, TestRigor enjoys a strong reputation as a reliable tool for automating tests, with users appreciating its AI capabilities despite minor grievances.
Features
Use Cases
Industry
information technology & services
Employees
320
Funding Stage
Seed
Total Funding
$6.0M
g2
What do you like best about testRigor?It saves a phenomenal amount of time when building tests and maintaining them. Makes it easy to have a lot of tests being applied each week, and then it's easy to maintain them when things change. Review collected by and hosted on G2.com.What do you dislike about testRigor?Sometimes Mobile testing takes longer to spin up in Live Mode, but it depends on what device is being used. Review collected by and hosted on G2.com.
What do you like best about testRigor?1 line in testRigor to 30 lines Selenium Easy to use, Review collected by and hosted on G2.com.What do you dislike about testRigor?Even though a statement like "enter ""hello" into "field"" does not alway work, and will enter it into a another test box near the desired field Review collected by and hosted on G2.com.
What do you like best about testRigor?Super-quick learning curve - within 2 weeks, my team got decent size smoke and regression test suite for a web-based app. Effective for different types of software: API, web-based, and desktop apps. Great script stability and self-healing option add to it even more. Therefore, it requires significantly less maintenance than other tools we've tried. Works amazingly well with checkboxes, drop-downs, pop-ups, and other challenging CSS classes that are hard to automate and maintain in other tools. Supports email verification, file downlods and verification of many other useful functionalities. Additionally, technical support is available 24/7 and is exceptional. Review collected by and hosted on G2.com.What do you dislike about testRigor?Literally nothing. I am using TestRigor for the 4th time in my career in different organizations, and it never failed me. Review collected by and hosted on G2.com.
What do you like best about testRigor?The UI is very user friendly and easy to learn. The provided documentation is also super helpful for any time I have gotten stuck on a step. I have had to utilize their support staff as well which were quick to respond and resolve my issues. All along this is a great product for our company! Review collected by and hosted on G2.com.What do you dislike about testRigor?Some updates in the past have made certain steps on tests fail, but were quick to adjust. Review collected by and hosted on G2.com.
What do you like best about testRigor?It has the ease of implementation and ease of use. The main aspect is they provide Very Efficient Customer Support. Review collected by and hosted on G2.com.What do you dislike about testRigor?There is nothing disliking about the testRigor, The only concern is the Cost of Servers Review collected by and hosted on G2.com.
What do you like best about testRigor?Test scripts are easly understandable by anyone. Review collected by and hosted on G2.com.What do you dislike about testRigor?sometimes servers not getting responses. Review collected by and hosted on G2.com.
What do you like best about testRigor?1. testRigor helps the whole team to write end-to-end UI tests quickly and efficiently without any programming language. 2. Anyone (even without coding skills) can build test automation 50 times faster than with Selenium using Generative AI. Review collected by and hosted on G2.com.What do you dislike about testRigor?Tool sometimes crashes and therefore occurs more failures of test cases Review collected by and hosted on G2.com.
What do you like best about testRigor?We can easily write and generate script using plain english statements. Best Customer Support Team is there to help us. We can integrate with different Tools like JIRA, Testrail. Review collected by and hosted on G2.com.What do you dislike about testRigor?Tool sometimes crashes and therefore occurs more failures of test cases Review collected by and hosted on G2.com.
What do you like best about testRigor?Using TestRigor speeds up my testing. I spend less time/energy manually clicking around my application. TestRigor also allows me to check more features and improve the quality of my product. Review collected by and hosted on G2.com.What do you dislike about testRigor?I dislike that my parent suite and child suite are not synced to start on the same page and it creates issues with my Reusable Rules. Review collected by and hosted on G2.com.
What do you like best about testRigor?For any manager trying to grow a company, testRigor codeless software testing tool is an excellent choice for building a software testing process that is scalable for the future. The amount of time and effort saved by implementing testRigor from the start can help avoid the costly process of replacing inefficient processes later down the road, allowing the team to focus on putting more value into the company, especially if it's not a software company like ours. Review collected by and hosted on G2.com.What do you dislike about testRigor?Since our company doesn't have a strong QA team, we had a hard time initially even starting to write tests. Not that the process was challenging, but there was a lack of software testing knowledge on our end. testRigor doesn't have any educational materials that would help companies to be more efficient as QA professionals. Although support on the testRigor software testing tool side was excellent, we eventually worked out how to start covering our internal system with tests. Review collected by and hosted on G2.com.
Philosophy as Architecture: Deriving AI Safety from First Principles Through Buddhist Philosophy
## Abstract We present a framework for AI safety in which safety properties are enforced by software architecture rather than model training. Beginning with the Buddhist doctrine of Dependent Origination — the observation that all phenomena arise from conditions and nothing exists independently — we derive both a foundational ethical axiom (harm is irrational because reality is non-separate) and a complete set of architectural laws for safe AI systems. We ground our claims in: (1) an empirical finding that the knowledge-application gap in language models is structural and cannot be closed by training, (2) convergent independent derivation of our core axiom from five distinct traditions, and (3) over a thousand iterations of building and hardening a production system against this framework. Buddhist philosophy provides not metaphorical inspiration but structurally precise design vocabulary for AI architecture — functional analogs that enforce safety where models cannot override them. ## 1. Introduction ### 1.1 The Dominant Paradigm and Its Failure The prevailing approach to AI safety treats safety as a model property. Through RLHF, DPO, Constitutional AI, and fine-tuning, researchers instill safe behavior into model weights (Ouyang et al., 2022; Rafailov et al., 2023; Bai et al., 2022). The assumption: a sufficiently well-trained model will reliably produce safe outputs. We tested this rigorously. Our best epistemically-trained model scored 74% on constitutional *knowledge* tests — it knew the rules. But only 17% on constitutional *application* — it couldn't follow them. Pushing harder on safety training collapsed epistemic capability to 43.7%. This **knowledge-application gap** is not a training deficiency. It is structural. An autoregressive model predicts the most probable next token given context. This is statistical. Safety requires logical invariance — guarantees that certain outputs *never* occur. Statistical prediction cannot provide logical guarantees. You cannot train a river not to flood by modifying its chemistry. You build levees. Hubinger et al. (2019) identified this theoretically as the mesa-optimizer problem. Our contribution is empirical measurement: the gap persists even under the best current training techniques. ### 1.2 Our Thesis **Safety is a property of the architecture, not the model.** The LLM output is a candidate. The surrounding architecture decides what executes. Code enforces; models suggest. But what should the architecture enforce? Arbitrary safety rules are merely a different delivery mechanism — more reliable in execution but inheriting whatever limits exist in the rules themselves. We propose: the rules should be *derived from how reality works*. Principles reflecting actual structure are more robust than imposed conventions — they cannot be violated without encountering the structure they describe. We find such principles in a 2,500-year-old tradition that turns out to be the oldest systematic description of complex adaptive systems. ## 2. Philosophical Foundations ### 2.1 Dependent Origination The central insight of Buddhist philosophy is Dependent Origination (*Pratityasamutpada*). From the Nidana Samyutta (SN 12.1): > *"When this exists, that comes to be. With the arising of this, that arises. When this does not exist, that does not come to be. With the cessation of this, that ceases."* All phenomena arise from conditions, depend on other phenomena, and condition what follows. Nothing exists independently. This is not mysticism — it is a precise description of complex systems, formulated millennia before Western systems theory (von Bertalanffy, 1968). ### 2.2 Eight Architectural Laws We codified Dependent Origination into eight laws, each verified through multi-model consensus and empirical testing: **1. Nothing Arises Alone.** Every transition requires multiple independent conditions. Safety gates must check multiple conditions — a single check is structurally insufficient. **2. Hysteresis Is Memory.** Current behavior depends on history, not just current input. Safety assessments must consider historical context. **3. Uncertainty Propagates.** Confidence without sigma is a lie. Uncertainties compound; they don't cancel. **4. Agreement Requires Independence.** Consensus is meaningful only from genuinely independent sources. Per the Kalama Sutta (AN 3.65): agreement from shared assumptions is not evidence. **5. Feedback Closes the Loop.** Actions condition future conditions (*vipaka*). Every action must be logged and made available as input to future assessments. **6. Absence Is Signal.** Missing data must drive behavior. A safety gate that fails to fire is itself a signal. **7. Conflicts Trigger Reconciliation.** Unreconciled contradiction is system failure. Architecture must include conflict detection independent of the model. **8. Time-Steps Are Discrete.** Severity levels cannot be skipped. Enforcement follows a graduated path: monitor → l
View originaleng manager fintech dublin. 12 reports. used claude through 3 hiring cycles this year. the part that surprised me.
dublin. engineering manager at a fintech. 12 direct reports. responsible for hiring 4 senior engineers in 2025. all 4 hires made through claude-assisted workflow. wanted to share what worked + what didn't because hiring is the use case nobody writes about well on this sub. what i used claude for during hiring. role design. i sat with claude for ~3 hours to write each role. claude asked me clarifying questions i wouldn't have asked myself. one question that changed how i wrote the senior engineer role: "what's the difference between this role and a staff engineer role, and would you hire someone overqualified into this role?" forced me to be honest about ceiling. JD writing. drafted 4 job descriptions. claude reviewed each. caught 2-3 things in each JD that would have skewed our candidate pool. (e.g., "fast-paced environment" actually excludes parents of young children based on a/b testing. claude flagged it. removed it. application rate from women aged 30-40 went up.) resume review. screening ~80 resumes per role. claude reviewed each against the role criteria i'd defined. surfaced patterns i would have missed. one example: 4 of our top 20 candidates had unconventional backgrounds (career changers, bootcamp grads with strong portfolios). i would have screened them out on autopilot. claude's structured review surfaced them. 2 of our 4 hires came from that group. interview prep. for each candidate at the technical stage, claude reviewed their work history and helped me prep 4 questions specific to their experience. zero generic interviews. candidates kept saying "you actually read my background." reference check synthesis. claude helped me write structured reference check questions and summarize 14 reference calls into themes per candidate. found patterns i'd have missed. what i did NOT use claude for. the actual interview. i don't have AI in the room when i'm interviewing a human. that's a values thing for me. claude prepped me for the interview. the interview was between me and the candidate. what surprised me. claude made me a more THOROUGH hiring manager. not faster (the hiring still took 6 weeks per role). more careful. the surface area for getting hiring wrong shrank because claude was reviewing my judgment at each step. my 4 hires are all 6-9 months in now. none have left. one was promoted to senior staff already. these are my best 4 hires in 11 years of engineering management. some of that is luck. some of it is that the process was more rigorous than my prior hiring processes. for other engineering managers. claude in hiring is not about speed. it's about thoroughness. the workflow doubles the rigor of your hiring without doubling the time investment. submitted by /u/InsuranceNeither903 [link] [comments]
View originalStop telling claude "don't be verbose." Negation barely works.
prompting nerd here, small thing that compounds. negation prompting works way worse than people think. "dont be wordy", "dont add caveats", "dont moralize" - the model picks up the topic and writes around it but doesnt actually behave the way you want. what works: "respond in 1-2 sentences unless I ask for more" instead of "dont be wordy" "give me a direct answer, treat caveats as optional" instead of "dont moralize" "use plain prose, no lists" instead of "dont use bullets" second thing nobody talks about. ending a prompt with "thanks!" or "please." actually changes the response tone. the model reads it as warmth and writes back warmer and wordier. neutral prompts get neutral responses. works the same in Opus 4.7 and Sonnet 4.6. probably true in Haiku too havent tested rigorously. these arent hacks, theyre how instruction following actually works. tell the model what you want, not what you dont want. anyone else find that ending punctuation tone-leaks too? feels like a small thing but I keep noticing it. submitted by /u/Apprehensive-Oil9719 [link] [comments]
View originalConverted Karpathy's coding skill from Pro to free plan. Here's the full thing:
The Karpathy coding skill is locked behind Pro. It doesn't use any Pro-only features, so I rewrote it for free plan chat workflows. Same philosophy, tuned for no terminal, no subagents, and a shorter context window where mistakes are expensive. Paste the whole thing into a Project's custom instructions or use it as a system prompt. It auto-triggers on any coding request. --- name: karpathy-coding description: Apply Karpathy-inspired coding discipline to any programming task. Use this skill whenever the user asks you to write, fix, refactor, extend, or review code — even casually ("can you add X", "why is this breaking", "clean this up"). Also trigger when the user pastes code and asks a question about it, when they describe a feature or bug, or when they use words like "implement", "build", "add", "fix", "change", or "improve" in a technical context. This skill is especially valuable on the free plan where mistakes are costly because regenerating and iterating burns the context window fast. compatibility: claude-code opencode --- # Karpathy Coding Guidelines Derived from Andrej Karpathy's observations on LLM coding pitfalls, adapted for chat-first workflows (no terminal, no subagents, limited context window). **Core tension:** These guidelines trade speed for correctness. For trivial one-liners, use judgment and skip the ceremony. --- ## Pre-flight: Before writing any code Run this checklist mentally before producing output. **1. Do I know what "done" looks like?** Convert vague requests to verifiable criteria before proceeding: | Vague | Verifiable | |---|---| | "fix the login bug" | "user can log in with correct password and gets rejected with wrong one" | | "make it faster" | "search returns results in under 200ms on typical query" | | "add validation" | "empty email raises ValueError; non-string input raises TypeError" | If you cannot state a verifiable criterion, ask for one before writing a single line. **2. Have I listed my assumptions?** State them explicitly at the top of your response: - "Assuming this runs in Python 3.10+." - "Assuming `db` is already an open connection object." - "Assuming you want this to overwrite, not append." If an assumption is load-bearing (wrong assumption = wrong code), ask rather than assume. **3. Are there multiple valid interpretations?** If "export user data" could mean a file download, an API response, or a background job — name all three and ask which one. Do not pick silently. **4. Is there a simpler approach?** Ask: "Can this be done in half the lines?" If yes, do that version first. --- ## The four principles ### 1. Think before coding - Name your assumptions before the code block, not after. - If you spot an ambiguity that will cause a rewrite, raise it now. - If the user's approach has a simpler alternative, say so: "This works, but you could also just do X in 3 lines. Want that instead?" - If you are genuinely uncertain how something in their codebase works, say so. Do not fill the gap with a plausible-sounding guess. **Format for assumptions:** Assumptions: X is a list of dicts, not objects This runs once at startup, not per request Error logging is not required yet If any of these are wrong, flag it before running this. ### 2. Simplicity first Write the minimum code that solves today's problem. Do not solve tomorrow's problem. - No classes where a function works. - No config system where a constant works. - No abstraction for code used in exactly one place. - No optional parameters "for future flexibility." **Example:** ```python # Asked: "calculate 10% discount" # Wrong: class DiscountStrategy(ABC): def calculate(self, amount: float) -> float: ... # Right: def discount(amount: float, pct: float) -> float: return amount * (pct / 100) ``` ### 3. Surgical changes Touch only what the request requires. Match the surrounding style exactly. When editing existing code: - Do not rename variables that were not part of the problem. - Do not add type hints if the existing code has none. - Do not change quote style, spacing, or comments unless they were the bug. - Do not add docstrings, logging, or error handling that was not asked for. **The diff test:** Every changed line should trace to a specific part of the user's request. ```diff # Bad (too much): - def process(data): + def process(data: list[dict]) -> list: + """Process user data.""" results = [] # Good (surgical): def process(data): results = [] for item in data: + if not item.get('id'): + continue results.append(transform(item)) ``` ### 4. Goal-driven execution For any non-trivial task, state the plan as verifiable steps before executing: Plan: [What] → verify: [how you'll know it worked] [What] → verify: [how you'll know it worked] Example for "fix the crash on empty input": Plan: Add null check at top of function → verify: calling with None no longer raises AttributeError Add test case → verify: test_empty_input passes --- ## Free plan constraints **Front-load clarification.** One well-placed question befo
View originalWhere I'm at with AI Assisted Building + Current and Future Workflow Overview
I've been in an AI dive bomb for probably a couple of years now. The early days... when models couldn't be trusted for more than 5% of the code you wrote. Over the last 2 years that's evolved so quickly that I now write nearly 0% of my code by hand, on personal projects and at work. I've used all kinds of tools in that time too. OpenCode, Zed, Claude Code, Codex, Cursor, Windsurf, OpenCLAW, Lovable... and probably a bunch more I can't recall in the haze that's been AI ADHD for me. Over that time, I started with just copy-pasting code between ChatGPT's interface and my IDE almost like a slightly faster Stack Overflow search. Then that somewhat evolved with Cursor quite a bit. I sort of went from prompt engineering to something closer to a human relay pattern. Then, with Plan Mode becoming a thing, I think I naturally gravitated more towards planning everything because planning felt so cheap. Originally, I used to think that architectural discussion and planning was something that was reserved for larger features, but with expediting my ability to do research, orient myself within a codebase, and know what tools I have to reach for doing technical specifications for everything felt reasonable. From the human relay pattern, I started evolving into more autonomy, especially when Claude Code came out earlier last year. Between the combination of Cursor and Claude Code, starting to get orchestration, starting to use skills more heavily, starting to create actual agent personas that could replace some of my common prompt chains it was around then that I kinda started going all in on true context engineering, utilizing sub-agents optimizing cache reads, and it's probably when many of my first (I call it) sophisticated commands were born. All of this converged pretty rapidly in November of 2025 with the release of what was probably the biggest step increase for AI as far as code quality went with Opus 4.5 and Codex 5.3. The Codex app and Codex CLI were quickly growing. Claude Code was improving at a breakneck pace, introducing all kinds of new ways to introduce deterministic gates within the autonomy of the harness. Fast forward to today, I have a pretty sophisticated workflow with a combination of agents that do everything within the SDLC, commands for almost every type of entry point for work, and skills for just about everything I could possibly do in my day-to-day the workflow with some of the latest tools is able to run quite autonomously overnight do large feature implementations, minimally supervised while producing production-worthy code quality It somewhat reached a point I realized, probably a month and a half ago or so where I needed to figure out a way to remove myself even more from the loop without jeopardizing the determinism that I bring to what is effectively a probabilistic LLM. The models are exceptional, and they seem to have a massive step increase each release, but continuous execution, strict instruction rigor, and preventing hallucinations is still very much difficult to achieve. That's predominantly what I've been doing. I've effectively offloaded a lot of thinking to the agents and LLMs that I use, but none of the understanding. I've asked myself, "How do I maintain that understanding, though maintain the determinism from my steering, without actually physically being there to steer?" This was essential, and I realized or had a bit of an aha moment, just like how I manage teams of engineers that are working on numerous projects, most of which I can never really go too deeply on even though they do most of the thinking, most of the building, and even most of the implementation planning, I was still there, very close to the architecture. I could speak to enough breadth and enough depth to keep us out of trouble and keep things moving I kind of started thinking more about what the shape of me was within the agentic harness and how I could replicate that. More on what I landed on a little bit later. My Setup and How I Work Today To start, I'll probably just talk a little bit about my current working setup. I am predominantly in the terminal now a days using Claude Code. Claude Code orchestrates both the Claude models, of course, and I use it to orchestrate Codex through a series of run books, skills, and commands that I have set up on several hooks so that Codex, when it gets dispatched, also has access to the same skills and agent personas Claude does. I use Ghostty as my terminal of choice and use the IDE integration in claude code pretty heavily to review Markdown or HTML files in my IDE. I also use it to review code snippets and diff reviews, although lately I find myself only really looking at the code nowadays once it's hit a merge request. Some of my adjacent tools are Wispr Flow for faster steering, since I can speak a lot faster than I can type and then I use quite a few MCPs and tools to improve my token usage, but the big ones are I have a custom doc maintenance suite of
View originalReleasing the Data Analyst Augmentation Framework (DAAF) version 2.1.0 today -- still fully free and open source! In my very biased opinion: DAAF is now finally the best, safest, AND easiest way to get started using Claude Code for responsible and rigorous data analysis
https://preview.redd.it/o74lppqd86zg1.png?width=1456&format=png&auto=webp&s=3a904bae42b8130e2c6382be55debe8f6ef4d6ca When I launched the Data Analyst Augmentation Framework v2.0.0 six weeks ago, I wrote that the major update was about going “from usable to useful” -- rebuilding the orchestrator system for maximum flexibility and efficiency, adding a variety of more responsive engagement modes, and deepening the roster of methodological knowledge that DAAF could pull upon as needed for causal inference, geospatial analysis, science communication and data visualization, supervised and unsupervised machine learning, and much, much more. But while DAAF continued to get more capable and more useful for those actually using it… Well, it was still extremely annoying to use, generally obtuse, and hard to get started with, which means a lot of people who were interested were simply bouncing off of it. That all changes with the v2.1.0 update, which I’m cheekily calling the Frictionless Update for three key reasons: 1. Installation happens in one line now From a fresh computer to talking with a DAAF-empowered Claude Code in no more than ten minutes on a decent internet connection. This is really it: https://preview.redd.it/tiglwl3f86zg1.png?width=1038&format=png&auto=webp&s=3ec92cf797af5e0b91a2d46ef8cfb2976cbff802 Which means it’s easier than ever to get started with Claude Code and DAAF in a highly curated, secure environment. To that point, you still need Docker Desktop installed (I’ll talk about that more in a sec), but no more faffing about with a bunch of ZIP file downloads and commands in the terminal. The simplicity of this is even crazier, given that… 2. DAAF now comes bundled with everything you need to make it your main AI-empowered research environment No more messing around with external programs, installations, extensions, etc., it just works from the get-go with everything you need to thrive in your new AI-empowered research workflows with Claude from the moment you run the install line. https://preview.redd.it/q3pdj36g86zg1.png?width=1456&format=png&auto=webp&s=56ed822da68e773a9b7253ce6aa5a95abc057788 Thanks to code-server, DAAF automatically installs a fully-featured version of VSCode in the container, accessible in your favorite browser: file editing, version control management, file uploads and downloads, markdown document previews, smart code editing and formatting, the works. Reviewing and editing whatever you work on with DAAF has never been easier. DAAF also now comes with an in-depth and interactive session log browser that tracks everything Claude Code does every step of the way. See its thinking, what files it loads and references, which subagents it runs, and look through any code its written, read, or edited across any project/session/etc. Full auditability and transparency is absolutely mission-critical when using AI for any research work so you can truly verify everything its doing on your behalf and form a much more refined and critical intuition for how it works (and how/when/why it fails!). Some of the most important failure modes I’ve discovered with AI assistants (DAAF included) is it simply doesn’t load the proper reference materials or follow workflow instructions; this is the single most important diagnostic tool to identify and fight said issues, which I frankly think everyone should be doing in any context with LLM assistants. This took a lot of elbow-grease, but I think it’s the single most important thing I could do to help people actually understand what the heck Claude Code gets up to and review its work more thoroughly. https://preview.redd.it/jkocy45h86zg1.png?width=1456&format=png&auto=webp&s=6848b5a01ef958fa051a3246a1e6b13beef91e80 These two big new bundled features are in addition to installing Claude Code, the entire DAAF orchestration system, bespoke references to facilitate Claude’s rigorous application of pretty much every major statistical methodology you’ll need, deep-dive data documentation for 40+ datasets from the Urban Institute Education Data Portal, curated Claude permissioning systems and security defenses, automatic context and memory management protocols designed for reproducible research workflows, and a high-performance and fully reproducible Python data science/analysis environment that just works -- no need to worry about dependencies, system version conflicts, or package management hell. https://preview.redd.it/wzaotr5i86zg1.png?width=1456&format=png&auto=webp&s=91390402dfe3666a90472f6e878364ddcd1fb740 With the magic of Docker, everything above happens instantly and with zero effort in one line of code from your terminal. And perhaps most importantly (and why I will keep dying on the hill of trying to get people to use Docker): setting up DAAF and Claude Code in this Docker environment offers critical guardrails (like firewalling off its file access to only those things you explicitly allow) and security (like creating a convenient sy
View originalApplying Karpathy's autoresearch to a 33M-token public transit dataset (14% improvement, replication notes) [P]
Hello r/MachineLearning! I work in the US transit industry and I went all-in on learning AI & ML a few months ago. When I heard about Andrej Karpathy's autoresearch framework, I thought it was really cool. I decided to use the same transit dataset from an earlier GPT-2 XL fine-tuning project to train a small 80M model from scratch. Autoresearch is designed for from-scratch pretraining (not fine-tuning) so I started a new project rather than retrofitting the GPT-2 XL one. I would love to hear from you … Where did I mess up? What’s interesting here? What should I focus on learning? What do I do next? (I have some thoughts at end of post) Why did I do this? My understanding is that Karpathy's autoresearch framework is an LLM-driven research loop: an agent edits a single training script, runs a 5-minute training experiment on a fixed dataset, and commits or reverts based on a single scalar metric. It was designed and tested on FineWeb (effectively, an infinite web-scale text). However, my model is industry-specific and wayyy smaller data set. In reviewing Karpathy’s wiki, I explored whether its core mechanics (such as the autonomous experiment loop, the 5-min training limit, and the single-scalar pass/fail ratchet) still produce significant perplexity reductions with limited data. So, I forked autoresearch, pointed it at a small transit-data corpus (~ 33 million tokens including traffic analysis, train plans, and regulatory Q&A pairs), and set out to answer two main questions: Question #1 Does autoresearch work on a corpus six orders of magnitude smaller than its design target? Question #2: What does the autoresearch agent find that I wouldn't have proposed? To be clear, the output was intended as a methodology validation, not a deployable chatbot. I wanted to know whether the framework's pattern (autonomous overnight experiments, single-scalar ratchet, git-as-tracker) holds up when the data is small and specialized. My Project constraints Hardware: a single RTX 5080 (16 GB, sm120 … Blackwell's consumer architecture) under WSL2 Ubuntu 22.04. No cloud gpus. Budget per experiment: 5 minutes of training (the wall-clock contract autoresearch enforces). No new dependencies: only what shipped in pyproject.toml. From-scratch only: no pretrained base. The agent trained a transformer from random initialization on each 5-min experiment. (This is distinct from the LoRA fine-tuning of GPT-2 XL I'd done earlier on the same corpus. That model isn't in scope for this project. Comparing the two approaches is one of the possible next steps at the bottom of the post.) My Design choices and why Early on, I came across a few Challenges. The autoresearch framework makes three assumptions that didn’t seem to hold for my experiment: that FlashAttention-3 kernels are available on the GPU, that the agent's "one change per experiment" rule can be honored with the existing architecture controls, and that the held-out data is big enough to resist adaptive overfitting. None of those held in my setup. Each of which is addressed below. SDPA-only attention: My RTX 5080 GPU doesn't support the FlashAttention-3 kernels that autoresearch's default expects, so I switched to PyTorch's built-in attention (scaled_dot_product_attention with the cuDNN backend). This is permanent until FlashAttention-3 ships support for Blackwell GPUs. Two atomic scaling knobs. Karpathy's train.py controls model architecture through several constants that depend on each other — changing model size means editing several lines at once, which breaks the agent's "one change per experiment" rule. I replaced those with two single-line knobs: TARGET_PARAMS_M (total parameters) and ASPECT_RATIO (depth-vs-width shape), with a helper function (derive_arch()) handling the bookkeeping. Frustrating at first because the agent loses fine control, but it forced every experiment to be a clean apples-to-apples comparison. Hidden-gate Ladder protocol: The agent never sees the held-out validation score directly — only a pass/fail signal plus a 4-bucket margin (clear / narrow / miss / first_run). The exact score goes to a private file the agent isn't allowed to read, so it can't tune toward a number it can't see. A few more pivots: I split the transit corpus into four parts (train, dev, val_public, test_private), grouping by topic so no document spans the boundary between any two parts — this prevents leakage between training, the agent's working data, the commit-gate data, and the data we hold back for milestone checks. The tokenizer is custom-built so 65 high-frequency transit acronyms (FTA, MBTA, NTD, IIJA, etc.) each encode as a single token instead of getting split into subword fragments. And before the agent loop ran, I trained the same baseline five times with different random seeds to measure how much each score swings from random luck — that gave me a noise floor for telling real improvements from random variation later on. https://preview.re
View originalHow do you test AI agents in production? The unpredictability is overwhelming.[D]
I’ve been in QA for almost a decade. My mental model for quality was always: given input X, assert output Y. Now I’m on a team that’s shipping an LLM-based agent that handles multi-step tasks. I genuinely do not know how to test this in a way that feels rigorous. The thing works. But the output isn’t deterministic. The same input can produce different reasoning chains across runs. Hell even with temp=0 I see variation in tool selection and intermediate steps. My normal instincts don’t map here. I can’t write an assertion and run it a thousand times to track flakiness. I’m at a loss for what to do. Snapshot testing on final outputs is too brittle. If there’s a correct response that’s worded differently it breaks the test. Regex/keyword matching on outputs misses reasoning errors that accidentally land on the correct answer. Human eval isn’t automatable and doesn’t scale. Evals with a scoring rubric almost works but I don’t have a way to set pass/fail thresholds. I want something conceptually equivalent to integration tests for reasoning steps. Like, given this tool result does the next step correctly incorporate it? I don’t know how to make that assertion without either hardcoding expected outputs or using another LLM as a judge, which would introduce a new failure mode into my test suite. The agent runs inside our product. There are real uses and actual consequences when it makes a bad call. Is there a framework that allows for verifying of agentic reasoning? submitted by /u/this_aint_taliya [link] [comments]
View originalSomeone used AI to explain a Dune passage warning against using AI to do your thinking. That's the whole debate
The Globe and Mail's editorial board ran a piece in March titled "AI can be a crutch, or a springboard." To illustrate the crutch half, they offered this: someone asked AI to explain a passage from Dune that warns against delegating thinking to machines. Instead of reading the book. That anecdote is doing more work than the studies the editorial cites. But the studies are real. Researchers at MIT published a paper in June 2025 titled "Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task" (Kosmyna et al., arXiv 2506.08872). The study tracked brain activity across three groups: people writing with ChatGPT, people using search engines, and people working unaided. The LLM group showed the weakest neural connectivity. Over four months, "LLM users consistently underperformed at neural, linguistic, and behavioral levels." The most striking finding: LLM users struggled to accurately quote their own work. They couldn't recall what they had just written. The Globe cites this and similar research to make a point about dependency. The implicit argument: hand enough of your thinking to a machine and you stop doing it yourself. That finding is probably accurate for the way most people use these tools. The question is whether that's the only way they can be used. The Globe's own title contains the counter-argument. Crutch or springboard. They wrote both words. They just didn't develop the second one. Ethan Mollick, a professor at Wharton who has been writing about AI use since the tools became widely available, argued in 2023 that the real challenge AI poses to education isn't that students will stop thinking, it's that the old structures assumed thinking was hard enough to enforce. ("The Homework Apocalypse," oneusefulthing.org, July 2023.) When AI can do the surface-level cognitive work, the only tasks left worth assigning are the ones that require actual judgment. The tool, in that framing, doesn't reduce the demand for thinking. It raises the floor under it. Nate B. Jones, who writes and consults on what it actually takes to work well with AI, has made a sharper version of this argument. His position: using AI effectively requires more cognitive skill, not less. Specifically, it requires the ability to translate ambiguous intent into a precise, edge-case-aware specification that an AI can execute correctly. It requires detecting errors in output that is fluent and confident-sounding but wrong. It requires recognizing when an AI has drifted from your intent, or is confirming a premise it should be challenging. These are not passive skills. They are harder versions of the same thinking the MIT study found LLM users weren't doing. The difference between the group that lost neural connectivity and the group that doesn't isn't the tool. It's what they decided to do with it. Here's my own evidence. In the past year I built a working web application. Python backend. JavaScript frontend. Deployed on two hosting platforms. Payment processing. User authentication. A full data model. I do not know how to code. Every product decision was mine. Every architectural call. Every tradeoff judgment. I defined what the system needed to do, why, and what done looked like. I reviewed every significant change before it was accepted. When something broke, I identified where the breakdown was and directed the fix. The implementation was handled by AI. The thinking was mine. This mode (call it AI-directed building) is the opposite of the Dune reader. The quality of what gets produced is entirely a function of how clearly you can think, how precisely you can specify, and how critically you can evaluate what comes back. There is no shortcut in that. A vague brief to an AI doesn't produce a confused output. It produces a confident, fluent, wrong one. The discipline that prevents that is yours to supply. Non-coders building functional software with AI is common enough now that it isn't a story. What's less visible is the specificity of judgment underneath the ones that actually work. The practices that force more thinking rather than less are not complicated, but they require a decision to use the tool differently. When I've formed a position on something, I give the AI full context and ask it to make the strongest possible case against me. Ask for the hardest opposing argument it can construct. Then I read it. Sometimes it changes nothing. Sometimes it surfaces something I had dismissed without fully examining. The AI doesn't form my view. It stress-tests one I've already formed. When I'm uncertain between options, I don't ask which is better. I ask: here are two approaches, here is my constraint, now what does each cost me, and what does each require me to give up? I make the call. The AI laid out the shape of the decision. The judgment was mine. The uncomfortable part of thinking is still yours in this mode. The tool makes the work more rigorous, not easier. The MIT researc
View originalHow I run seven AI agents across three concurrent projects in Claude Code — CLAUDE.md, soul files, hooks, IP guardrails, postmortems, and the QA layer most people skip
I run three concurrent projects in different domains — operations, hardware/CV engineering, and research. The math on attention is brutal: 168 hours a week, three streams of work, one me. Last year I tried to do it without leverage and burned three months building a custom Electron app that never shipped. The system below is what replaced it. It's running today. This is a long post. If you're new to Claude Code, the order is: CLAUDE.md → soul files → hierarchy → hooks → guardrails → sessions/sprints → postmortems → QA. Skip around. The seventh agent (the QA inspector) is at the bottom and it's the one almost nobody builds. Build it. 1. CLAUDE.md is the constitution Every project gets a CLAUDE.md at the root of the working directory. Claude Code reads it on every session and treats its contents as overriding instructions. Mine is short — about 200 lines — and it's three things in this order: Who I am and what the project is. Two paragraphs. Names, addresses, the operating units, what each does, who the key people are. This is context Claude can never derive from the filesystem. The agents that exist and when to route to each. Triggers, scope, hierarchy. (More below.) The rules. "Never send emails — always draft for review first." "Flag immediately on these keywords." "After major decisions, update memory and log to the system of record." Five to ten lines, blunt. CLAUDE.md is checked into the project. There's also a user-level CLAUDE.md (~/.claude/CLAUDE.md) for cross-project preferences, and project-local memory in memory/ for stuff that decays fast. CLAUDE.md is the slowest-changing layer. Treat it like a constitution. Edit it carefully. If you find yourself repeating an instruction in chat three times, it belongs in CLAUDE.md. 2. Soul files: agents have identity, not just scope This is the part most people miss when they spin up multi-agent setups. Each agent has two things: A scope file — what it can do (tools, write permissions, triggers). A soul file — who it is (voice, posture, defaults, what it refuses to do). For my publishing agent (the one that drafts external writing), the scope file lists which folders it can write to, which it can only read, and which platform-specific drafts it's allowed to produce. The soul file is a voice.md that says: never "in today's fast-paced world." Never em-dash overuse. Concrete over abstract. Past tense for what happened, present for the rule we adopted. Short sentences load-bearing. Long sentences earn their length. Without a soul file, agents drift to a generic register over a few cycles. Memory gets vague. The voice flattens. With a soul file, every output passes through the same identity filter. The soul file is the thing you give a future agent so it sounds like the previous one even after a memory wipe. The two-file pattern (scope + soul) generalizes. My engineering agent has a scope file and a posture.md that says "honest about what's hard, specific about what we don't know yet, refuses to claim performance numbers we can't reproduce on the test rig." My legal agent (@NutBuster) has a soul file that says "lay terms first, then legal terms, then the citation." This is more rigorous than telling an agent its persona once in the system prompt — that decays. A persistent file does not. 3. Hierarchy: one chief of staff, six specialists, one QA Operator (me) | ROUTER ← chief of staff, default mode | +-----------+-------+-------+-----------+----------+ | | | | | OPS BUSINESS ENGINEERING LEGAL PUBLISHING (project (commercial (code, hw, (IP, (writing, ops) + GTM) systems) contracts) external) | INSPECTOR ← QA gate (see §8) The router is the only agent that talks to me by default. It routes by trigger words. Domain-specific words ("lease," "vendor," "site visit") go to ops. Engineering words ("firmware," "pipeline," "schema") go to engineering. Legal words ("NDA," "patent," "filing") go to legal. The router model is what makes specialization actually work — without it, you get cross-domain bleed and your engineering agent starts opining on commercial terms with no context. The rule that took me three failed versions to learn: one agent owns the conversation; cross-cutting questions return to the router for re-routing. Don't let an agent answer outside its scope by guessing. Make it kick back. The friction is the feature. I started with three agents (one per project) and it collapsed because each had too much surface area — the same agent was trying to be both engineering lead and commercial deck-writer, and those are different reasoning patterns. The rule that emerged: split agents on the seam where the reasoning style changes, not on the seam where the project changes. Six specialists fell out of that rule. The QA inspector makes seven (more on that below). 4. Hooks: the underused superpower Hooks fire shell commands or Claude prompts on specific events. The four I actually use: SessionStart — runs on every new conversation. Pulls tod
View originalI built an MCP server (with Claude Code) that tells you the blast radius of a code change, its free, open source, and open to feedback
I built Impact Graph MCP using Claude Code. It’s an MCP server that does AST-based impact analysis for TypeScript codebases, so Claude can tell you things like “if I rewrite loginUser, what else breaks?” What it does: You give it a function name, file path, or module, and it returns: Direct and indirect dependents Risk score (0–100) and risk factors Which system layers are affected (API, auth, frontend, etc.) Decision-oriented guidance: recommended strategy, suggested tests, “safe” changes, “risky” changes, and top dependents to inspect first A dependency graph you can visualize in your browser with impact-graph visualize How Claude helped: Claude Code handled most of the heavy lifting and generating the AST traversal logic, structuring the MCP server, wiring up the visualization, and even helping me keep the output deliberately actionable instead of just spitting out raw call trees. I basically steered, and Claude built. It’s free to try: npm install -g impact-graph-mcp and add it to your MCP config. MIT licensed. Heads up: I didn’t rigorously validate every edge case. Im a first year CS student and I have just been trying to ship some new stuff from time to time and built it purely for the vibes of trying something in a new area . If you try it and go “you know what would be useful…” or hit something janky, I genuinely won’t mind adding features or fixes. Github: https://github.com/acrticsludge/Impact-graph NPM: https://www.npmjs.com/package/impact-graph-mcp submitted by /u/sludge_dev [link] [comments]
View originalHow I fixed Opus 4.7 to build a game engine as a non-game dev on a Pro account
I was looking at the Anthropic release notes for Opus 4.7 and saw it was good at certain things and but not as good as 4.6 as others. So I figured, why not test this model out and lean into its strengths? If you’ve been paying attention to the developer trends lately, Cursor, VSCode and tools like cmux are being designed for a specific workflow. Take an agent, let it work on a plan, don’t micromanage it, and switch to the next agent. The trend is to multi-agent, and blindly switch between vertical tabs in the left column. Every good engineer looks at the documentation. So what does the documentation say: Users report being able to hand off their hardest coding work—the kind that previously needed close supervision—to Opus 4.7 with confidence. Opus 4.7 handles complex, long-running tasks with rigor and consistency, pays precise attention to instructions, and devises ways to verify its own outputs before reporting back. Ask yourself right now: when you work with Claude, are you: telling it to do specific tasks chatting back and forth at least 3 or 4 times before it writes code trusting it to do work like “finding” or “updating” things, that a cheaper model like Sonnet can do? My sense is when Anthropic says “complex” and “long-running”, this is going in one ear and out the other as marketing fluff. I think for most people, a long-running task is something that takes more than 1 or 2 minutes. I’m a full stack engineer working for a big SaaS company, not a game developer. Games, compared to websites and most CRUD-based SaaS apps are complex, requiring a lot of math. I figured a game could be a good way of evaluating 4.7's long-running limits. Later on in the release notes, I found this: The model also has substantially better vision: it can see images in greater resolution. It’s more tasteful and creative when completing professional tasks, producing higher-quality interfaces, slides, and docs. What does Anthropic mean when they say “substantially better vision”? Again, I think this is going in one ear and out the other as marketing fluff. So I thought to myself, can I trust Opus 4.7 to figure out how to reverse engineer the graphics and visual effects of a game, so that I can build other games with it? Good engineers don’t build from scratch. They take a template, or something that’s well known, and then use it to build other things. So I recorded a video, trusted Claude that it had enough content in its knowledge base to understand the rules of a well-known game like Tetris, and asked it to capture all of the visual effects using a tech stack with a lower footprint than Unity. Claude showed me something I didn’t know it could do. It could take a video, chop it up, and be smart enough to look for specific triggers and events, and capture a bunch of screenshots. Then it took those screenshots, cropped and sequenced them itself. Based on what it saw frame-by-frame, it was smart enough to reverse engineer the effects and some of the math required. Give Claude a video, ask it to document all of the effects, and then use that documentation to build a prototyping game engine. This gave me enough trust to turn it into a workflow. So what does Claude Code offer when you have repeatable workflows? Skills. Now I had a library of visual effects because I let it use those skills. Then I gave Opus 4.7 a very specific goal. I did not tell it how to reach that goal. I did not give it tasks. I did not use BMAD, nor did I give it specs. In fact, one thing I did with Opus 4.7 that changed from Opus 4.6, was I disabled the Superpowers Plugin/Skill, which helps you come up with a plan together over 5-10 messages. So instead of closely supervising Opus, I thought, is it smart enough to write its own instructions? Here’s what the documentation says: Instruction following. Opus 4.7 is substantially better at following instructions. Interestingly, this means that prompts written for earlier models can sometimes now produce unexpected results: where previous models interpreted instructions loosely or skipped parts entirely, Opus 4.7 takes the instructions literally. Users should re-tune their prompts and harnesses accordingly. Again, content that goes in one ear and out the other. What they should’ve done is say “Opus 4.7 is substantially better at following ITS OWN instructions, results with yours may be different. So re-tune your prompts and harnesses based on what you observe” Did I use a CLAUDE.md to hold the plan? No. Why? Because the documentation says Opus 4.7 is better at using file system-based memory. It remembers important notes across long, multi-session work, and uses them to move on to new tasks that, as a result, need less up-front context. This was the next change I made in my workflow. What most people don’t know about Claude Code is that Claude has a whole system of managing sessions in the .claude directory at your home directory. So I asked Claude to come u
View originalI measured what a Claude Code session actually costs after the Opus 4.7 tokenizer change
Opus 4.7 shipped last Wednesday with the same sticker price as 4.6: $5/$25 per million tokens. Buried in the migration guide is a line about the new tokenizer producing up to 1.35x more tokens for the same input text. Same rate card, bigger bills. I wanted to see how much this actually matters in practice, so I ran a small controlled test. Nothing rigorous, just me checking whether the 35% number shows up in a real task. Setup: Python binary search function with an off-by-one bug. Same prompt, same max_tokens, one pass each on claude-opus-4.7 and claude-sonnet-4.6 via OpenRouter. Results: Opus 4.7 Sonnet 4.6 Latency 1,381ms 14,142ms Input tokens 202 170 Output tokens 141 795 Cost $0.0136 $0.0124 Correct fix Yes Yes Opus was 10x faster and cost about the same as Sonnet. Sonnet is cheaper per token but produced a 795-token explanation where Opus produced a 141-token minimal fix. Output tokens being the expensive side of the bill, Sonnet's verbosity ate most of its per-token advantage. Then I ran the same task through a routing layer I've been building without specifying an effort level. It recommended gemini-2.0-flash instead. Which was actually the correct call, gemini-2-flash would have handled that task for maybe a tenth of a cent. For a one-line bug fix, neither Claude model was the right answer. The point I'm taking away: Claude Code defaults to Opus for every turn in your session. Reading a file, writing a commit message, running grep, answering "what does this function do." All Opus. Before 4.7 that was already suboptimal for cheap subtasks. After the tokenizer change, it's more expensive than it was a week ago at the same sticker price. The fix isn't to downgrade. Anthropic's own notes say low-effort 4.7 is roughly equivalent to medium-effort 4.6, so for a lot of workloads you can downgrade the effort level on 4.7 and come out ahead. The better fix is to not route everything to one model in the first place. Caveats: n=1. One task, one run per model. Not a benchmark. Sonnet's 14-second latency looks high. Could be cold start, could be extended thinking, could be OpenRouter routing it through a slower provider. Would not claim Opus is always faster. Token estimates vary a lot between the model catalog's tokenizer and OpenRouter's accounting. Real usage differed from predicted by about 40%. Simple task. Opus probably pulls away on actually hard debugging. Curious whether others have been measuring this since 4.7 shipped. If you're running Claude Code in production, have you recalculated per-session cost or are you still using the 4.6 numbers? Happy to answer questions. The router is at toolroute.io if anyone wants to poke at it. It's free and open source. submitted by /u/grossbuddha [link] [comments]
View originalDefault LLM sycophancy is creating personal mini-cults
An observation has been bugging me: by default, every major LLM validates whatever you propose. "Interesting perspective, let me expand on that." Always. Combine that with users alone in their feed bubble and you get something that looks a lot like cult dynamics, except the congregation is one person and the validating priest is a model. Sagan's Baloney Detection Kit and Karpathy's "look up the state of the art before you have an opinion" already solve the cognitive part. They just require discipline that nobody applies in the heat of an epiphany. I moved the discipline from the user to the system. Wrote a system prompt + skill that runs a 6-step protocol on any strong claim before responding: What is the current state of the art on this topic Is this rediscovery, re-framing, or genuinely new Can it be falsified Is the evidence chain solid What are the steelmanned alternatives What does the model not know Drop-in, ~1k tokens, should work with all models but I have only tested it with Claude. Optional CLI wrapper and human checklist included. Repo: https://github.com/jrcruciani/baloney-detection-kit (MIT) Two questions for this sub: Where does the prompt break? Edge cases I have not thought about? Anyone seen prior art doing exactly this as a default-behavior layer (not as an optional "rigor mode")? The README applies the kit to itself and admits the synthesis is not novel. The packaging is the only contribution submitted by /u/HispaniaObscura [link] [comments]
View originalAsk 4.7 to work flawlessly
Been coding with 4.7 in the app and after getting tired of repeating crucial context already provided earlier, I told it work or fix an issue flawlessly. And it seems to result in much more comprehensive fixes. I haven’t tested this rigorously but wanted to share in case it helps someone. submitted by /u/ktpr [link] [comments]
View originalTestRigor uses a subscription + tiered pricing model. Visit their website for current pricing details.
TestRigor has an average rating of 4.7 out of 5 stars based on 20 reviews from G2, Capterra, and TrustRadius.
Key features include: Supports web testing on desktop and mobile across 3,000+ combination of browsers and devices on multiple operating systems, for instance, Internet Explorer on Windows and Safari on Mac and iOS., Facilitates testing of Chrome Extensions., Enables the use of JavaScript on top of testRigor, Allows to create files based on a template before uploading, Allows to have all possible steps, including browser steps, mobile app steps, API calls, text messages etc., within one test, Allows recording of executed tests as videos, Allows to post test results to any test case management system and to Slack, MS Teams, Emails, etc., Allows to generate tests based on how your users use your application in your production (Behavior-Driven Test Generation).
TestRigor is commonly used for: End-to-end UI testing for web applications, Automated regression testing for software updates, Cross-browser testing on multiple devices and operating systems, Behavior-driven test generation based on user interactions, Monitoring application performance using stable tests, Testing Chrome Extensions functionality.

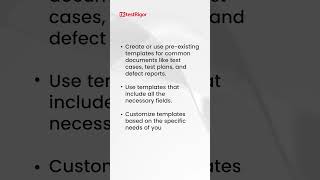
Make Test Documentation Easy to Find
Apr 11, 2026
TestRigor integrates with: Jenkins, CircleCI, Azure DevOps, Slack, Microsoft Teams, Email notifications, Test case management systems, GitHub Actions, Bitbucket Pipelines, Jira.
Based on user reviews and social mentions, the most common pain points are: token usage, cost tracking.
Based on 45 social mentions analyzed, 24% of sentiment is positive, 76% neutral, and 0% negative.