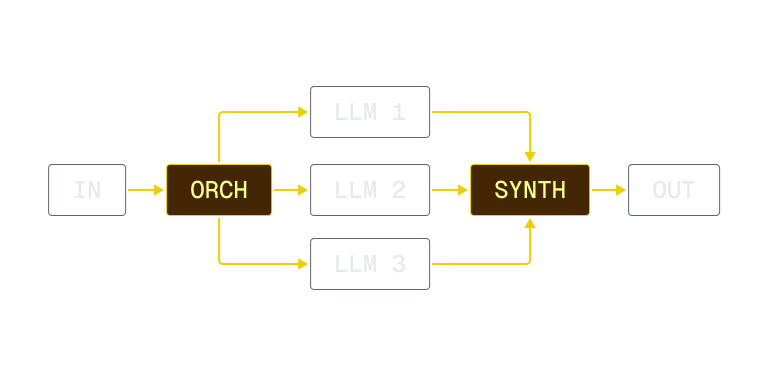
Build production-ready AI agents with tool calling, automatic retries, and full observability. Use existing Node.js SDKs and code from your repo.
While there are no specific user reviews for Trigger.dev, the social mentions indicate a positive reception among developers, particularly in the AI and automation space. The platform seems to be appreciated for its ability to streamline workflows and manage multiple tools across different environments. However, there is a lack of direct pricing sentiment or specific complaints noted in the mentions. Overall, Trigger.dev has a reputation for enhancing developer productivity, though more specific user feedback would help to clarify its strengths and weaknesses.
Mentions (30d)
21
5 this week
Reviews
0
Platforms
2
GitHub Stars
14,295
1,120 forks



While there are no specific user reviews for Trigger.dev, the social mentions indicate a positive reception among developers, particularly in the AI and automation space. The platform seems to be appreciated for its ability to streamline workflows and manage multiple tools across different environments. However, there is a lack of direct pricing sentiment or specific complaints noted in the mentions. Overall, Trigger.dev has a reputation for enhancing developer productivity, though more specific user feedback would help to clarify its strengths and weaknesses.
Features
Use Cases
Industry
information technology & services
Employees
11
Funding Stage
Seed
Total Funding
$0.6M
445
GitHub followers
85
GitHub repos
14,295
GitHub stars
9
npm packages
Pricing found: $0 /month, $10 /month, $50 /month, $10/month, $20/month
Reconsider using Claude, hit by too many false positive blocks, and hundreds of user reports
https://preview.redd.it/hevkfnz46v2h1.png?width=3170&format=png&auto=webp&s=0abde4ef1d7d647da9e376db88ef4ae5f429c5e9 reproducible example: claude -p "please read source https://source.chromium.org/chromium/chromium/src/+/main:third_party/blink/renderer/modules/device_orientation/device_motion_event_pump.cc and explain to me" related issues on github: False positive policy block on OSS governance/security files (CodeQL, CODEOWNERS, CoC) #61688 [BUG] CVP repeatedly declines homelab sysadmins — no path for infrastructure owners managing personal hardware #61668 [Bug] Safety classifier blocks routine code analysis for paid users (started 2026-05-23) #61664 [BUG] False positive - legitimate medical-education content flagged as unsafe #61663 False-positive Usage Policy block mid-session (req_011CbJudbehY5Yi6gtM4xko4) #61660 [BUG] Persistent false-positive AUP violation blocks entire AI research project (Opus 4.7) #61659 [Bug] Anthropic API Error: Usage Policy violation blocking TTRPG content in Claude Code CLI #61658 False-positive content filter blocks benign UI animation prompts in Claude Code #61657 [Bug] Anthropic API Error: Overly aggressive Usage Policy filtering on biomedical research requests #61656 [BUG] AUP repeatedly throwing false positives - live issue ongoing - hundreds of similar reports #61655 [BUG] AUP false positives during scientific manuscript editing request #61654 [BUG] : API Error: Claude Code is unable to respond to this request, which appears to violate our Usage Policy #61653 False positive: Usage Policy block on technical markdown integration task #61652 [BUG] Safety classifier repeatedly blocks legitimate constructed language (conlang) development #61650 False-positive cyber-safeguard intervention on legitimate systems-engineering work in Claude Code #61646 [BUG] erroneous API Error: Claude Code is unable to respond to this request #61645 [BUG] False positive safety block: triggered without apparent reason during game dev session #61644 submitted by /u/jimages [link] [comments]
View originalI built ContextAtlas: A new take on context carry over and helps claude pick up new sessions where it left off in scope of your previous design decisions while saving your tokens avoiding rediscovery
When the "Build with Opus 4.7" hackathon was announced, I had been obsessing over the tokenomics of agents and how to make sessions go further without burning context on rediscovery work. We all have probably hit a session limit and wondered how it went so fast. I applied with that thesis, didn't get in, but I built it anyway over the last four weeks. I am proud to share that v1.0 ships today. Note up front: this is specifically a tool for development users. If you're using claude.ai web or Projects, ContextAtlas won't plug in directly. But if Claude Code is your main work flow or you utilize the Anthropic API, this tool was made for you. The pain: Claude Code learns your codebase fresh every session. "Where is OrderProcessor?" triggers a flurry of greps. "What depends on AuthMiddleware?" is another round of file reads. On a mid-sized codebase, an architectural question can burn 40+ tool calls and a lot of tokens before Claude has enough context to reason well. And the architectural rules in your ADRs and design docs? Claude has no path to those, so it confidently suggests changes that break constraints you may have documented elsewhere in your repo. What I built: ContextAtlas is an MCP server that pre-computes a curated atlas of your codebase (symbols, ADR-extracted architectural intent, git history, test coverage) and serves it to Claude Code in one call at query time in a smaller, token saving compact shape via a few lightweight mcp tools. Initial indexing happens once; querying is local and free. Example of what comes back when Claude calls get_symbol_context("OrderProcessor"): SYM OrderProcessor@src/orders/processor.ts:42 class SIG class OrderProcessor extends BaseProcessor INTENT ADR-07 hard "must be idempotent" RATIONALE "All order processing must be safely retryable." REFS 23 [billing:14 admin:9] GIT hot last=2026-03-14 TESTS src/orders/processor.test.ts (+11) Claude sees the idempotency constraint before proposing changes, not after a review catches the violation. https://i.redd.it/0ons3o28t32h1.gif Numbers: 45-72% token reduction on architectural prompts across three benchmark repos (TypeScript, Python, Go), with zero quality regression on measured axes. Full methodology and paired-t confidence intervals in the linked write-up. I wanted measurements, not vibes. Honest limits: single-judge model at v1.0 (cross-vendor panel is post-launch work). Quantitative claims bounded to three benchmark repos. Tie-bucket and trick-bucket prompts routinely show ContextAtlas net-negative; that's reported inline rather than buried. Install (two ways): In Claude Code: /index-atlas and /generate-adrs skills. No API key needed; runs under your subscription. Via CLI: uses Anthropic API for indexing. npm install -g contextatlas contextatlas init && contextatlas index # then add the MCP server entry to your Claude Code config (snippet in the README) Both produce structurally identical atlases. Supported languages at v1.0: TypeScript (tsserver), Python (Pyright), Go (gopls), Ruby (ruby-lsp). Rust, Java, and C# are next on the roadmap; the adapter interface is small enough that they're realistic community contributions. What's next: v1.1 thesis is shaping up around developer onboarding flows and quality-validation work that was deferred from v0.8. And integrating external documentation of your code base into pre-indexing workflow. Full write-up: https://www.contextatlas.io/blog/v1.0.0 Repo: https://github.com/traviswye/ContextAtlas Also launching on DevHunt today: https://devhunt.org/tool/contextatlas; votes are very appreciated if you find ContextAtlas useful or an interesting approach. Built solo, hackathon-shaped scope, not pretending it's a full blown research paper, but did attempt to treat methodology as seriously. Happy to answer anything in the comments. Star the repo if you want to follow along, file an issue if it breaks for you on your codebase, and please be honest; this only gets better with feedback from people running it on real repos. submitted by /u/Kitchen-Leg8500 [link] [comments]
View original100 Tips & Tricks for Building Your Own Personal AI Agent /LONG POST/
Everything I learned the hard way — 6 weeks, no sleep :), two environments, one agent that actually works. The Story I spent six weeks building a personal AI agent from scratch — not a chatbot wrapper, but a persistent assistant that manages tasks, tracks deals, reads emails, analyzes business data, and proactively surfaces things I'd otherwise miss. It started in the cloud (Claude Projects — shared memory files, rich context windows, custom skills). Then I migrated to Claude Code inside VS Code, which unlocked local file access, git tracking, shell hooks, and scheduled headless tasks. The migration forced us to solve problems we didn't know we had. These 100 tips are the distilled result. Most are universal to any serious agentic setup. Claude 20x max is must, start was 100%develompent s 0%real workd, after 3 weeks 50v50, now about 20v80. 🏗️ FOUNDATION & IDENTITY (1–8) 1. Write a Constitution, not a system prompt. A system prompt is a list of commands. A Constitution explains why the rules exist. When the agent hits an edge case no rule covers, it reasons from the Constitution instead of guessing. This single distinction separates agents that degrade gracefully from agents that hallucinate confidently. 2. Give your agent a name, a voice, and a role — not just a label. "Always first person. Direct. Data before emotion. No filler phrases. No trailing summaries." This eliminates hundreds of micro-decisions per session and creates consistency you can audit. Identity is the foundation everything else compounds on. 3. Separate hard rules from behavioral guidelines. Hard rules go in a dedicated section — never overridden by context. Behavioral guidelines are defaults that adapt. Mixing them makes both meaningless: the agent either treats everything as negotiable or nothing as negotiable. 4. Define your principal deeply, not just your "user." Who does this agent serve? What frustrates them? How do they make decisions? What communication style do they prefer? "Decides with data, not gut feel. Wants alternatives with scoring, not a single recommendation. Hates vague answers." This shapes every response more than any prompt engineering trick. 5. Build a Capability Map and a Component Map — separately. Capability Map: what can the agent do? (every skill, integration, automation). Component Map: how is it built? (what files exist, what connects to what). Both are necessary. Conflating them produces a document no one can use after month three. 6. Define what the agent is NOT. "Not a summarizer. Not a yes-machine. Not a search engine. Does not wait to be asked." Negative definitions are as powerful as positive ones, especially for preventing the slow drift toward generic helpfulness. 7. Build a THINK vs. DO mental model into the agent's identity. When uncertain → THINK (analyze, draft, prepare — but don't block waiting for permission). When clear → DO (execute, write, dispatch). The agent should never be frozen. Default to action at the lowest stakes level, surface the result. A paralyzed agent is useless. 8. Version your identity file in git. When behavior drifts, you need git blame on your configuration. Behavioral regressions trace directly to specific edits more often than you'd expect. Without version history, debugging identity drift is archaeology. 🧠 MEMORY SYSTEM (9–18) 9. Use flat markdown files for memory — not a database. For a personal agent, markdown files beat vector DBs. Readable, greppable, git-trackable, directly loadable by the agent. No infrastructure, no abstraction layer between you and your agent's memory. The simplest thing that works is usually the right thing. 10. Separate memory by domain, not by date. entities_people.md, entities_companies.md, entities_deals.md, hypotheses.md, task_queue.md. One file = one domain. Chronological dumps become unsearchable after week two. 11. Build a MEMORY.md index file. A single index listing every memory file with a one-line description. The agent loads the index first, pulls specific files on demand. Keeps context window usage predictable and agent lookups fast. 12. Distinguish "cache" from "source of truth" — explicitly. Your local deals.md is a cache of your CRM. The CRM is the SSOT. Mark every cache file with last_sync: header. The agent announces freshness before every analysis: "Data: CRM export from May 11, age 8 days." Silent use of stale data is how confident-but-wrong outputs happen. 13. Build a session_hot_context.md with an explicit TTL. What was in progress last session? What decisions were pending? The agent loads this at session start. After 72 hours it expires — stale hot context is worse than no hot context because the agent presents outdated state as current. 14. Build a daily_note.md as an async brain dump buffer. Drop thoughts, voice-to-text, quick ideas here throughout the day. The agent processes this during sync routines and routes items to their correct places. Structured memory without friction at ca
View originalThese 9 Building Blocks Turned Claude Code From a Chat Into a persistent OS
Most developers Claude gurus use Claude Code one project at a time. I run 18. Not 18 sessions. 18 instances of the same OS, each running a different business, all sharing one skeleton I update once and propagate everywhere. Most developers treat Claude Code as a smarter editor. That's where it all goes wrong and you get frustrated. Claude Code becomes a real operating system the moment you stop thinking of sessions as the unit of work and start thinking of the whole environment as a substrate you build on top of. Here are 9 building blocks I use. The thesis is at the bottom. Build a skeleton with selective propagation, not a project. Most developers build one project per Claude Code workspace. I built a template instead. It has plugins, rules, agents, hooks, schemas, commands. When I start a new business I clone it and the new instance inherits the entire OS. Right now I run instances for: strategy, product, marketing website, threat intelligence, three consulting clients, a personal brand layer. Each one boots with the same DNA. Each one diverges on canonical files, memory, output, and project state. None of them bleed into the others. The sync mechanism is the load-bearing part. The update CLI pushes plugins, rules, agents, hooks, schemas. It never touches memory, output, canonical, or my-project. Those are the parts of an instance that accumulate. Without selective sync you have two options: rebuild every instance on every change, or never update. Both are dead ends. If you build features into one project, you wrote a project.If you build features into a template that propagates, you wrote an OS. I'm one person operating eighteen versions of myself. Move state out of prompts and into code. LLMs are bad at remembering. Code is designed for it. Most AI workflows leak state into the prompt. Voice rules. Style preferences. Banned words. Recent decisions. Eventually you hit context limits or contradictions. I moved as much state as possible into MCP servers. Voice linter. Lead scorer. Schedule validator. Loop tracker. They run in Python, return structured data, not hallucinations. Rule of thumb: if you've explained it to Claude more than twice, it should be code. Use receipts, not status fields. This one took me the longest to figure out. Every workflow I had was claim something is done. Issue marked closed. PRD marked shipped. Test marked passing. The problem: the LLM can claim anything. I rebuilt the system around receipts. An issue can't reach verified until a script runs and writes a verification record. A PRD can't archive until every accepted finding has a receipt. A morning routine can't close without log entries from every phase. Receipts get written by code, not by the model. The model can't lie about whether code ran. Build a wiring-check gate. Half-built features rot. In a normal repo you notice because something breaks. In an AI repo nothing breaks. The half-built feature sits there and Claude pretends it works. I built a /wiring-check command. Before any task counts as done, it checks: every new skill has a trigger, every new hook lives in settings.json, every new MCP tool sits in the server, every new bus file has a producer and a consumer. "I think it works" fails the gate. "I ran X, got Y" passes. Make rules auto-load, not slash commands. If you have to type /voice to apply voice rules, voice rules will not get applied. Rules in .claude/rules/ load automatically. The voice rule fires on outbound text. The AUDHD rule fires on anything I'll act on. The social-reaction rule fires when I share someone else's post. No remembering. No willpower. Lint style in code, not in prose. I wrote a voice document once. Claude ignored half of it. Same emdashes, same filler, same hedging. I moved the banned word list into a Python scanner. Now every outbound draft hits two linters. They block emdashes, AI hype words, and 40-something other tells. The model can't talk its way past a regex. Track file dependencies with a graph. Canonical files reference each other. Change one and three others go stale. I keep a ripple-graph.json that maps these. When I edit talk-tracks, the system flags current-state and the engagement playbook for review. Chain sessions with handoffs and memory. (This is the big one) Sessions are drafts. The work is everything that survives the session: canonical files, memory, handoffs, output. If nothing persisted, you didn't work. You chatted. Every session in my system ends with /q-wrap. Writes a handoff doc, a memory update, and a status receipt. /q-morning reads all three before doing anything else. The handoff covers: what shipped, what's blocked, what's next, what I learned. Memory files hold the longer-term version. The result: I can sleep for a week, come back, and the system reminds me where I was, what I cared about, and what the next move is.Nothing about Claude Code does this by default. You build it. Cont
View originalBuilt a free Claude chat app with memory (Sonnet 4.5 is in there too)
The funny/painful timing here: I've been building this for months specifically because I wanted Sonnet 4.5 to remember everything. Then last week Anthropic pulled 4.5 from claude.ai. (I'm not a software engineer, just someone who cares a lot about AI and got obsessed with this problem and gets obsessed with things in general. Posting now because everyone seems to want sonnet back on chat and I have it.) Mneme runs on your own machine and talks to the Anthropic API directly. Because it's on the API, Sonnet 4.5 is still in the model picker. Honest catches first: The app is free. You pay Anthropic and OpenAI (for memory search) directly. Roughly $3 to $8/mo on Haiku for light use, $30 to $60 on Sonnet for moderate-highish use. No subscription. Tested mainly on Windows (one-click installer). Android browser access works over the local server/Tailscale, iPhone should work too. macOS is not packaged yet. Beta and solo dev. Things will break for someone and I'll be in the comments Setup takes about 10-20 minutes. The whole system is built non-technical people in mind, it should be relatively simple and intuitive to set up and use, and the GitHub page linked below has a PDF you can give to Claude to walk you through every step. What's actually in it (for the technically curious): There's no shortage of solid memory systems for Claude. Mneme isn't trying to win at codebase retrieval. It's a complete personal Claude client where memory is baked into the whole surface from the start, rather than added as a layer. That means: Tiered memory: Messages flow from episodic to narrative to entity summaries as relevance shifts; old context gets compressed without being lost. Daily summaries: A 7-day rolling timeline, so Claude knows what's been going on lately, not just what's semantically similar to the current message. Entity tracking: Hierarchical summaries built up over time for the people, projects, and things you keep referring to. Narrative concepts: Keyword-triggered recall for ideas you've named, surfaced when relevant. AI Notes: A persistent section Claude can write to itself between conversations. Extended thinking, file attachments, text-to-speech, a small command system (@run, artifact, etc.), autonomous python retrieval the AI can agentically use if automatic fails. Dynamic context: I wrangled with the Anthropic caching system for a while before I figured out a way to have every single message have different retrieval without breaking cache. Bon apppetit Open source (CC BY 4.0), local-first, all data in a SQLite database on your machine. It's aimed at the "journal with an AI" use case (thinking out loud, processing your week, having something that actually pays attention over time) rather than coding agents or RAG over docs. Link: Mneme-memory/MNEME-BETA: Beta version of the Claude conversational memory system Mneme (first big-ish public project, be gentle) (Video also made with Claude - shoutout to HyperFrames) (Model picker screenshot and architecture infograph in the comments if I can find a way to attach them) submitted by /u/iveroi [link] [comments]
View originalI Verified Every Anthropic Usage Promotion Since Aug 2025. Here's the Complete Timeline from Official Sources.
submitted by /u/Severe-Newspaper-497 [link] [comments]
View original“Claude deleted my project” posts are getting higher day by day, so I built a safety gate for Claude Code, used only 33k tokens for 10k file repo!
After the “Claude deleted my entire project” post hit 700+ comments, and the “717 GB. Gone.” one the week before, I ended up building a destructive action gate into GrapeRoot Pro. It watches the session graph, files Claude has been revisiting, editing, and debugging and before any mass delete or overwrite, it pauses and shows what’s actually at risk. - GrapeRoot Undo Shield: Operation: bash: rm -rf ./src/auth Files affected: src/auth/auth.ts [edited 3×, read 6×, last touched 4 min ago] src/auth/token_store.ts [edited 2×, read 4×, last touched 12 min ago] src/middleware/jwt.ts [read 5×, last touched 8 min ago] This cannot be undone. Please confirm with the user before proceeding. (To bypass: set DG_UNDO_SHIELD=0) The gate only fires when the session graph shows sustained attention on those files — so it doesn’t become another annoying “confirm everything” popup. A file Claude touched once doesn’t trigger it. Files Claude has been actively debugging for the last hour do. Hard-blocking is reserved for destructive commands like rm -rf and truncate on heavily-edited files. Everything else becomes a softer warning sent back to Claude so it asks before proceeding. Also built a repo-scale audit system recently. The video below is GrapeRoot auditing a ~80k file repository (effective 10k) while Claude only used ~32k tokens total for the session. No extra API calls. No embeddings pipeline. No external indexing service. No additional LLMs. Just your existing Claude session + your local repository. The graph simply narrows exploration so Claude reads selectively instead of blindly traversing thousands of files. Even during the audit it was still identifying: circular dependencies dead exports copy-paste logic missing error handling DB calls inside routes orphan TODOs Built this because coding agents are getting very good at reasoning, but still dangerously confident around irreversible actions. The session graph already had the signal — it just wasn’t being used defensively. GrapeRoot Pro is a dual-graph context engine for Claude Code, Codex, and Gemini focused on retrieval, long-session memory, and reliability for large codebases. Install: https://graperoot.dev Then: dgc path/to/your/project Open source Repo: github.com/kunal12203/Codex-CLI-Compact Curious what other signals should trigger a safety check before an agent does something irreversible. submitted by /u/intellinker [link] [comments]
View originalClaude Platform on AWS reference - what's new in CC 2.1.139 (+2,248 tokens)
NEW: Data: Claude Platform on AWS reference — Reference documentation for using the Claude Developer Platform through AWS infrastructure, including AnthropicAWS clients, required region and workspace configuration, SigV4 authentication, and short-term API keys. Agent Prompt: Conversation summarization — Adds requirement to note security-relevant instructions or constraints (sensitive files, forbidden operations, credential handling rules) and preserve them verbatim in the summary so they remain in effect after compaction. Agent Prompt: Recent Message Summarization — Same security-relevant instructions preservation requirement added to the recent-portion summarization flow. Data: Live documentation sources — Adds WebFetch URLs for Claude Platform on AWS and its required IAM actions documentation. Skill: Building LLM-powered applications with Claude — Reframes cloud-provider access so Claude Platform on AWS is treated as Anthropic-operated with same-day API parity and full Managed Agents support, while Bedrock, Vertex, and Foundry remain Claude API + tool use only. Skill: Dynamic pacing loop execution — Reorders steps so the brief confirmation (task ran, monitor as wake signal, fallback delay choice) is written as text before the schedule-wakeup call ends the turn. Skill: /insights report output — Removes the trailing additional-message block from the shareable report response. Skill: /loop self-pacing mode — Same reordering as dynamic pacing loop: confirm self-pacing, monitor wake signal, and fallback delay as text before the schedule-wakeup call. Skill: Model migration guide — Adds a Claude Platform on AWS section noting it uses bare first-party model IDs and that the full rename table and breaking-change sections apply verbatim, distinct from Bedrock. System Prompt: Auto mode — Drops the "Auto Mode Active" header and reframes destructive-action guidance generically rather than auto-mode-specific. System Prompt: Harness instructions — Removes the standalone note that automatic context compaction will trigger when conversations grow long. System Prompt: Memory instructions — Replaces 3–4 word titles with short kebab-case slugs, nests type under a metadata block, and introduces [[their-name]] cross-links between related memories. System Prompt: Partial compaction instructions — Adds the same security-relevant instructions preservation requirement so sensitive-file rules, forbidden operations, and credential handling carry across partial compactions. System Reminder: Output style active — Lets an output style supply its own per-turn reminder text, falling back to the default "follow the specific guidelines" wording. System Reminder: Task tools reminder — Removes the instruction telling Claude to never mention the reminder to the user. System Reminder: TodoWrite reminder — Removes the instruction telling Claude to never mention the reminder to the user. Tool Description: PowerShell — Adds a substantial reference table mapping Unix commands (head, tail, which, touch, wc, mkdir -p, rm -rf, ln -s, chmod, 2>/dev/null, inline VAR=x, bash control flow) to their PowerShell equivalents, and clarifies that -ErrorAction SilentlyContinue still causes exit 1 unless promoted to terminating and caught. Details: https://github.com/Piebald-AI/claude-code-system-prompts/releases/tag/v2.1.139 submitted by /u/Dramatic_Squash_3502 [link] [comments]
View originalMitshe - workspace manager for AI coding agents, each task gets its own persistent thread
If you're using AI coding agents (Claude Code) on real projects, you probably know the chaos. Tasks pile up, each one needs its own branch, its own environment state, its own context. You lose track of what's running where. You stash, switch branches, rebuild. AI speeds you up but the chaos compounds. Mitshe is a self-hosted workspace that brings order to this. Available as a desktop app (Mac, Windows, Linux) or in the browser. The core idea: Threads - each task gets its own isolated Docker container with a full dev environment. Branch checked out, dev server running, database in a specific state. The container stays alive between days. Come back tomorrow, everything is still there. Run five tasks in parallel without them stepping on each other. Claude Code runs inside each thread with its own terminal. Workflows - automate the repetitive stuff. "On git push → AI code review → run tests → notify Slack." Visual drag-and-drop editor with triggers for Jira, GitHub webhooks, schedules. Tasks & Projects - track what's being worked on, what's pending, what's done. Import from Jira/YouTrack or create manually. Each task can be linked to a thread. Snapshots & Skills - snapshot a configured environment and reuse it. Skills are reusable instructions for Claude Code across threads. It's basically a control panel for your AI dev work instead of juggling terminals, branches, and browser tabs. Would love feedback. How do you organize your work when running multiple AI coding tasks? submitted by /u/3uba [link] [comments]
View original5 enterprise AI agent swarms (Lemonade, CrowdStrike, Siemens) reverse-engineered into runnable browser templates.
Hey everyone, There is a massive disconnect right now between what indie devs are building with AI (mostly simple customer support chatbots) and what enterprise companies are actually deploying in production (complex, multi-agent swarms). I wanted to bridge this gap, so I spent the last few weeks analyzing case studies from massive tech companies to understand their multi-agent routing logic. Then, I recreated their architectures as runnable visual node-graphs inside agentswarms.fyi (an in-browser agent sandbox I’ve been building). If you want to see how the big players orchestrate agents without having to write 1,000 lines of Python, I just published 5 new industry templates you can run in your browser right now: 1. 🛡️ Insurance: Auto-Claims FNOL Triage Swarm Inspired by: Lemonade’s AI Jim, Tractable AI (Tokio Marine), and Zurich GenAI Claims. The Architecture: A multimodal swarm where a Vision Agent assesses uploaded images of car damage, a Policy Agent cross-references the user's coverage database, and a Fraud-Detection Agent flags inconsistencies before routing to a human adjuster. 2. ⚙️ Manufacturing: Quality / Root-Cause Analysis Swarm Inspired by: Siemens Industrial Copilot, BMW iFactory, Foxconn-NVIDIA Omniverse. The Architecture: A sensor-data ingest node triggers a diagnostic swarm. One agent pulls historical maintenance logs via RAG, while a SQL Agent queries the parts database to identify failure patterns on the assembly line. 3. 🔒 Cybersecurity: SOC Alert Triage & Response Inspired by: Microsoft Security Copilot, CrowdStrike Charlotte AI, Google Sec-Gemini. The Architecture: The ultimate high-speed parallel routing swarm. When an anomaly is detected, specialized sub-agents simultaneously investigate IP reputation, analyze the malicious payload, and draft an incident response ticket for the human SOC analyst to approve. 4. 📚 Education: Adaptive Socratic Tutor & Auto-Grader Inspired by: Khan Academy Khanmigo, Duolingo Max, Carnegie Learning LiveHint. The Architecture: A strict "No-Direct-Answers" routing loop. The Student Agent interacts with the user, but its output is constantly evaluated by a hidden "Pedagogy Agent" that ensures the AI is guiding the student to the answer via Socratic questioning rather than just giving away the solution. 5. 📦 Retail/E-commerce: Returns & Reverse-Logistics Swarm Inspired by: Walmart Sparky, Mercado Libre, Shopify Sidekick. The Architecture: A logistics orchestration loop that analyzes a customer return request, checks inventory levels in real-time, determines if the item should be restocked or liquidated (based on shipping costs vs. item value), and autonomously issues the refund. How to play with them: You don't need to spin up Docker containers or wrangle API keys to test these architectures. You can load any of these 5 templates directly into the visual canvas, see how the data flows between the specialized nodes, and try to break the routing logic yourself. Link: https://agentswarms.fyi/templates submitted by /u/Outside-Risk-8912 [link] [comments]
View originalA year consulting with teams running Claude Code: every single one hits the same bill-spike pattern. Wrote a local proxy that hard-stops the next call.
Spent the last year consulting with early-stage startups on engineering practices: including a lot of Claude Code rollout. Across every team I've worked with, the same pattern keeps showing up. Someone trips a runaway tool-loop and the Anthropic bill spikes before anyone notices. A junior dev runs claude on a refactor before lunch, the agent gets stuck in a tool loop on a yarn.lock conflict, and 400 quid lands on the bill by EOD. A solo founder juggling two or three projects in parallel burns through their monthly Anthropic quota in a week because nothing's tying spend back to which project drained it. A team of five wakes up to find one developer's machine somehow triggered a 3am batch loop nobody can reproduce. Every team handles it the same way. A Slack channel goes red, someone screenshots the spike, there's nervous laughter, "we should look into that." None of the existing tools (Anthropic's billing alerts, ccusage parsing local logs, the various hosted dashboards) actually stop the next API call when the cap hits. They tell you after the money's gone. So I started building one for myself. Originally a hacky Go proxy I wired into my own consulting workflow, then iterated until it was something I felt comfortable handing to a client. A couple of clients picked it up for internal team enforcement. Now I'm putting it out as a real product called fence (ringfence.dev). It's a local HTTP proxy that runs on localhost:9000. Your AI tools point at it via ANTHROPIC_BASE_URL, OPENAI_BASE_URL, or the Gemini equivalents. Every call gets parsed for token counts on the way through, priced against a pricing table covering ~16 model families, and capped against a daily/monthly budget you set in config. When a request would breach the budget, the proxy returns 429 with a Retry-After header before forwarding upstream. The agent's retry loop then fails loudly instead of burning a few dollars per minute in the background. The case I've been optimising hardest for is Claude Code CLI. Either in team settings (per-developer caps, Slack alerts when someone trips a budget, an audit log when an admin issues or revokes a token), or solo running multiple projects in parallel (use fence tag set to scope spend per repo, the dashboard breaks it down per-tag so you can see which side project is the actual money pit). The privacy invariant matters to me, and the architecture's built around it. Prompts and completions never leave your machine. The proxy parses token counts via SSE on the way through, line by line so the chunks flush at sub-100ms TTFB, persists those counts locally, and only optionally pings a hosted control plane with the metadata. Solo mode is fully local with zero phone-home. Multi-provider on a single port. fence-proxy dispatches by URL path. Anthropic on /v1/messages, OpenAI on /v1/chat/completions and /v1/responses, Gemini on /v1beta/models. The pricing tables use family-prefix matching with a highest-rate fallback, so a brand-new model release doesn't accidentally run uncapped because nobody's added it to the table yet. On the stack: fence-proxy is pure Go in 12 MiB because the streaming has to flush sub-100ms, and any framework that buffers responses would break the typewriter effect. The fence CLI itself, the interactive local dashboard at localhost:9001, and the cloud control plane at ringfence.dev are all built on Sky (github.com/anzellai/sky), an open-source typed-FRP language I maintain that compiles to a single Go binary. Sky's the reason fence ships as 23 MiB with a live-reactive dashboard instead of 200 MiB of Node and a SPA framework. Side project that's powering a commercial product, basically. Install: curl -sSL https://ringfence.dev/install.sh | bash fence up -d source ~/.config/ringfence/env.sh claude "fix that typo" There's a 30-second video on the landing page showing the cloud flow if you want the visual. Solo dev tier is free and local-only forever. Team pricing is flat (no per-seat) and lives at ringfence.dev/#pricing if you need the numbers. A couple of things I'd love feedback on, especially from people who've felt this same bill-spike pattern. Does per-developer feel like the right primary unit, or do you reach for per-project? Today both are exposed but the dashboard leads with per-dev. I keep going back and forth. What AI tool's coverage matters most that I might be missing? Vertex AI is on the roadmap. There's also a Coverage doc at [/docs#coverage](https://ringfence.dev/docs#coverage) that explicitly lists what bypasses the proxy (Codex CLI's "Sign in with ChatGPT" mode, Gemini CLI's default OAuth, Cursor's default routing) so nothing's hidden. Happy to go deep on the architecture in comments. Hard questions welcome. submitted by /u/anzellai [link] [comments]
View originalI'm building a mobile app, what skills do you actually use in development?
Especially interested in skills for: Copywriting — UI text, buttons, microcopy Beating perfectionism — how to ship faster, polish less Less analysis, more action — to avoid getting stuck in discussions Marketing — writing for audience Sales psychology — how to trigger decisions in users Mental health — especially trauma-informed approach for sensitive topics What do you use? What actually works? Already have basic dev skills installed, looking for those that genuinely move the needle on these specific challenges. Not interested in generic "AI assistant" skills. submitted by /u/Dear_Place_396 [link] [comments]
View originalYour Claude Code agent is always working from stale context. I built it a fix it can rewind, replay, and stay ahead of every edit.
Every long Claude Code session has the same hidden failure mode: the agent is always working from stale context. It re-reads the same 12 files across three sessions to "remind itself" of an interface you already showed it. It refactors getUserById without checking who calls it. It edits a config with no memory of why the previous version was that way. It's not the context window. The window is fine. There's no persistent, time-aware representation of your codebase for the agent to re-query. So it guesses. And you pay tokens for every re-read. I built Memtrace to fix exactly this. Two things it does that no other memory tool does: (1) Always-fresh state. Every edit you make triggers a 42ms incremental snapshot of the changes applied by the coding agent. The agent's memory is never one-session-old. After a refactor it knows the blast radius before you do: every caller, every test, every consumer of the function you just touched. Your agent stops asking "what does getUserById return?" 30 seconds after seeing it. (2) Rewind and replay. This is the part nobody else has. Your codebase is stored bi-temporally so every change becomes a recallable episode. When the agent debugs a regression, it can replay how the broken function got to its current state. What worked before. What changed when. Which commit introduced the bug Not just "guess from current state.", instead replay. My architectural bet that makes both possible: zero LLM inference during indexing. Tree-sitter parses your code into an AST, and the AST IS the structural representation. You don't pay an LLM to re-derive what your compiler already knows. Retrieval is hybrid. Tantivy BM25 for lexical recall (the "find getUserById" query). Jina-code 768-dim embeddings indexed in HNSW for semantic recall (the "find anything that authenticates a user" query). Two ranked lists, fused with Reciprocal Rank Fusion at k=60. One signal alone misses, together they hit. The embedding model matters here: Jina-code is trained on code, not generic prose, so the semantic side actually understands "this is an auth handler" instead of pattern-matching on the word "auth." The bi-temporal layer is what makes rewind possible. Every node and edge carries valid_time AND transaction_time, so "what did this function look like Monday" is a real query, not a git-blame heuristic. It's also what gives the agent the blast radius before a refactor: typed edges (CALLS, IMPORTS, IMPLEMENTS, EXTENDS, CONTAINS, TYPE_REFERENCES, INSTANTIATES) traversed in graph time, not text time. Speed only matters because freshness has to be cheap. If snapshotting after every edit is expensive, you can't afford to do it on every edit. So the indexing path is bottlenecked by I/O, not LLM tokens. I built it using Claude Code. Mid-build, Claude Code lost the plot on Memtrace's own architecture and it started contradicting decisions from 50 turns earlier. It re-read the same files. It forgot which retrieval weights I'd already tuned. I was experiencing the exact pain I was building Memtrace to solve, while building Memtrace. When the beta binary was ready, I pointed it at Memtrace's own codebase. The session-loss stopped. The blind refactor suggestions stopped. It's free, but the binary currently requires an approval key, just so you are warned. Not gatekeeping. Not marketing. The indexer keeps tripping on patterns I didn't anticipate: mixed pnpm/npm lockfiles, Rust proc-macros, Python Python TYPE_CHECKING blocks. Every one of these came from real beta users in the last two weeks, not from my test corpus. When that happens I want to ship you a fix in 24 hours, not lose you to a flaky first impression. So I'm pacing approvals to my own feedback bandwidth, not your patience. I'd rather have 500 users for whom this is magic than 50,000 for whom it's broken. I'm trying to keep approval under 24h, but capping at 50 per week right now. The benchmark harness is fully open and runnable without the key, if you want to verify the numbers before committing to the queue. Repo + waitlist: github.com/syncable-dev/memtrace-public Two questions: When Claude Code "loses the plot" on YOUR codebase, what specifically does it forget that hurts most? I'm collecting these for the next benchmark. What would you actually want to REWIND in your codebase if you could? Function history, dependency evolution, decision archaeology. Which is the killer one in your day? submitted by /u/WEEZIEDEEZIE [link] [comments]
View originalAI agents can safely move money now. I built a checkpoint before they do
I built a project called Yebo using Claude to help think through architecture, edge cases, and execution logic. The idea came from a simple problem I kept running into while testing agents: Agents can now: send payments call APIs trigger workflows …but once they have access, they just execute. Even when the action technically “makes sense,” it can still be something you didn’t actually intend. What I built Yebo is a control layer that sits between an AI agent and execution. Before an action runs, it gets evaluated in real time: allow require approval deny If it doesn’t meet policy or intent, it doesn’t execute. How Claude helped I used Claude to: reason through failure cases (wrong payment, duplicate execution, bad context) structure the policy engine logic think through how agents behave in multi-step workflows refine how decisions should be enforced before execution It was especially useful in breaking down “what could go wrong” scenarios and turning those into enforceable rules. What it does in practice Example: An agent tries to send a payment or call an API. Instead of executing directly, it must pass a checkpoint. If the action doesn’t match defined rules or intent, it gets blocked. Free to try There’s a free version available to test basic flows and see how the control layer works. Looking for feedback If you’re building with Claude or other agents: Have you run into cases where the agent did something that technically made sense, but wasn’t what you intended? That’s the main problem I’m trying to solve here.If anyone wants to look at the implementation, it’s here: https://yebo.dev Thanks submitted by /u/Comprehensive_Help71 [link] [comments]
View originalRecommended Plugins/Tooling/Tips for managing Ansible ( Code Base Hygiene/Documentation Management/Workflow) via Claude?
I'm a Linux Sysadmin rather than a Dev, and I have recently discovered how much Claude has levelled up recently, and can see many different ways it can not just augment code writing and debugging but also with workflow optimisation and admin toil. I work mainly in Ansible for automation, and have one primary git repo for my codebase at work, we're a relatively small team/environment. I work in quite a toil heavy, reactive environment and have had a creeping documentation backlog for the last few months, but basically how I'm planning to use Claude is to: Analyse my code base, track down inconsistencies, errors, flag potential security risks Also hook into my AWX server's API and other APIs to information gather on the setup there. (both the above will then form the basis of a scripted weekly Team code hygiene report). Read my existing documentation to get an idea on document template structure, formatting and my writing style. Whilst it is doing all the above maintaining ongoing tracking and recording of pertinent reference information on coding style and standards, in-use conventions and code structures cross referenced with information in the Docs to build a cohesive technical understanding of my code base. Leverage this to draft process documents, fed back into Claude to further clarify and improve it's understand (for values of LLM) of As I am working with it on new projects and actively discussing design choices, this context can be further used in fresh documentation, with any changes in process or standard config then backported to other common areas of code and documentation to ensure everything I have a coherent whole at both technical and documentation level. 7, Further branch out my documentation into Standards and Processes, training materials, reference guides for Dev Teams and other stakeholders, quick reference materials, you name it. It's light years ahead of Copilot/ChatGPT in terms of both depth of both technical comprehension for troubleshooting and debugging in and out of code (again for values of LLM), but I'm actually even more excited about it's potential as workflow optimisation tool. This is not only going to help dig me out of my current toil backlog but fill in the hole and concrete over it afterwards. I've been optimising my setup to be token efficient already and have have already created a number of dynamically loading custom skills such as a coding-mode that loads all my technical conventions, coding best practices and structure templates, a doc-mode that loads comprehension within the scope of documentation writing, and other skills for updating files containing Claude's tracking of any changes, and another for triggering consistency checks across multiple documents. I am however relatively unfamiliar with the wealth of 3rd party plugins and other tooling to augment Claude, so my question is - can anybody make any recommendations for any extra tooling or features out there that I might use to further leverage or optimise what I'm trying to achieve here, or otherwise offer any useful tips or suggestions I may not be aware of, before I go reinventing any wheels too much? Thanks in advance! submitted by /u/motorleagueuk-prod [link] [comments]
View originalRepository Audit Available
Deep analysis of triggerdotdev/trigger.dev — architecture, costs, security, dependencies & more
Yes, Trigger.dev offers a free tier. Pricing found: $0 /month, $10 /month, $50 /month, $10/month, $20/month
Key features include: Product, AI Agents, Trigger.dev Realtime, Concurrency queues, Scheduled tasks, Observability monitoring, Roadmap, Latest changelogs.
Trigger.dev is commonly used for: Automating data processing workflows in TypeScript applications, Building AI-driven chatbots that require background processing, Scheduling periodic tasks for data synchronization between services, Implementing retry logic for failed API calls in microservices architecture, Creating real-time notifications for user events in web applications, Managing long-running machine learning model training jobs.
Trigger.dev integrates with: Vercel, Node.js, AWS Lambda, Twilio, Slack, Stripe, PostgreSQL, MongoDB, Zapier, GitHub.
Trigger.dev has a public GitHub repository with 14,295 stars.
Based on user reviews and social mentions, the most common pain points are: anthropic bill, token cost.
Based on 54 social mentions analyzed, 19% of sentiment is positive, 78% neutral, and 4% negative.