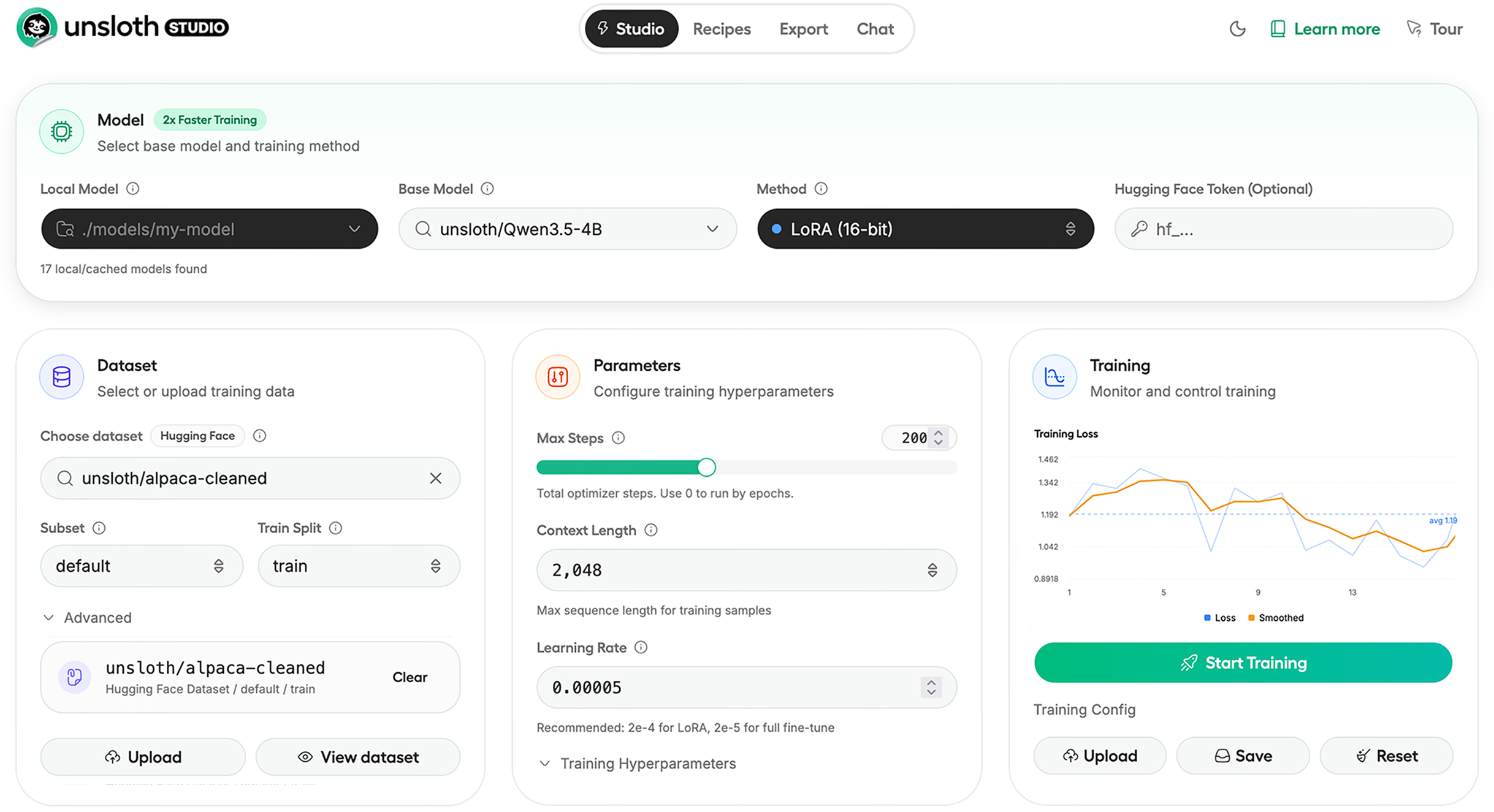
Unsloth is an open-source, no-code web UI for training, running and exporting open models in one unified local interface.
Reviews and social mentions of Unsloth suggest that its main strength lies in its integration capabilities and user-friendly interface, which attract positive feedback. However, there are few explicit user complaints or discussions about the software, indicating a potential gap in awareness or limited critical engagement among the existing user base. The lack of detailed user opinions on pricing sentiments makes it hard to assess the financial aspect, but overall, Unsloth appears to have a neutral to positive reputation largely due to its limited high-profile mentions.
Mentions (30d)
2
Reviews
0
Platforms
2
GitHub Stars
63,241
5,534 forks


Reviews and social mentions of Unsloth suggest that its main strength lies in its integration capabilities and user-friendly interface, which attract positive feedback. However, there are few explicit user complaints or discussions about the software, indicating a potential gap in awareness or limited critical engagement among the existing user base. The lack of detailed user opinions on pricing sentiments makes it hard to assess the financial aspect, but overall, Unsloth appears to have a neutral to positive reputation largely due to its limited high-profile mentions.
Features
Use Cases
Industry
information technology & services
Employees
21
Funding Stage
Seed
Total Funding
$0.6M
63,241
GitHub stars
1
npm packages
20
HuggingFace models
Made a tool that builds its own training data and improves each cycle by learning from what it got wrong
The basic idea is pretty simple. You give it a few seed prompts. It generates instruction-response pairs, an LLM scores each one, the good ones go into your training set and the bad ones become the seeds for the next round. Each cycle the model is essentially practicing on what it failed at before. You can run the judge completely locally with Ollama if you do not want to send data to any API. The fine-tuning at the end uses Unsloth on a free Colab GPU so the whole thing is doable without spending money. It is more of a practical tool than a research project but the idea of using failure cases as curriculum is something I find genuinely interesting. Would love to hear if anyone has done something similar. Github project link is in comments below 👇 submitted by /u/gvij [link] [comments]
View originalGoing from 3B/7B dense to Nemotron 3 Nano (hybrid Mamba-MoE) for multi-task reasoning — what changes in the fine-tuning playbook? [D]
Following up on something I posted a few days back about fine-tuning for multi-task reasoning. Read a lot since then, and I've moved past the dense 3B vs 7B question — landing on Nemotron 3 Nano (the 30B-A3B hybrid Mamba-Attention-MoE NVIDIA released recently) instead. Architecture maps to the multi-task structure I'm trying to train better than a dense base. Problem is I've only ever read about dense transformer fine-tuning, so I don't know what the hybrid Mamba+MoE arch actually breaks in the standard LoRA recipe. Still self-taught, no formal ML background, been working with LLMs via API for about a year. First time actually fine-tuning anything end-to-end. Why Nemotron 3 Nano specifically (in case the choice itself is the mistake): 23 Mamba-2 + 23 sparse MoE + 6 GQA attention layers, 128 experts per MoE layer with top-6 routing 30B total / ~3.6B active — capacity without per-token compute blowup Mamba-2 layers seemed like the right structural fit for state-aware reasoning across longer context Open weights under NVIDIA Open Model License, clean for what I want to do What I'm trying to fine-tune for (LoRA, distilling reasoning traces from a stronger teacher): Reading what's structurally happening in a situation vs. what's being stated on the surface Holding multiple legitimate perspectives without collapsing to one too early Surfacing the load-bearing thread when input has multiple tangled problems Conditioning output on a small set of numeric input features describing context state 40-80k examples planned, generated by Sonnet 4.6 with selective Opus 4.7 on the hardest 20%. ORCA-style explanation tuning, not just I/O pairs. Hardware: dropping the M4 Mac plan from my last post — Nemotron 3 Nano needs more memory than 24gb unified can hold even just for weights. Renting H100 80GB on RunPod for training. ~$120 budget across 5-6 iterations. What I'm specifically worried about (because the hybrid arch isn't covered in any standard fine-tuning tutorial I've found): Router under LoRA. Can you LoRA the MoE router weights safely, or do you freeze the router and only LoRA the expert FFNs + attention? If you freeze, does multi-task specialization still emerge or does everything pile into the same experts? Mamba-2 layers under low-rank adaptation. Standard LoRA tutorials assume pure attention. Mamba-2 has selective SSM state and different projection structure — does standard LoRA on the input/output projections work cleanly, or are there gotchas (state init, recurrence stability under low-rank perturbation) that vanilla guides don't cover? Load-balancing loss + multi-task imbalance. If my 4 capabilities have different example counts, does the auxiliary load-balancing loss fight task-specific gradients? Known failure modes here? Catastrophic forgetting on a 30B sparse base. With LoRA adapters on the experts, does base reasoning degrade the way it does for dense fine-tunes, or does sparse routing structurally protect more of it? Eval granularity under expert specialization. A single capability could quietly degrade while aggregate metrics look fine if different experts handle different tasks. What's the right held-out eval design for sparse MoE under multi-task? Stack: planning to use Unsloth (their Nemotron 3 Nano support shipped recently), per-capability held-out eval sets built and frozen before Batch 1, batch API + prompt caching on the teacher side to keep dataset cost in check. Not looking for: "just try it and see" — first run is already going to be wrong, want to know which dimensions are most likely to surprise me "use a smaller dense model first" — already weighed; the hybrid arch is specifically why I want this one Generic LoRA tutorials — comfortable with the dense-transformer LoRA literature, the gap is Mamba+MoE specifics Looking for: War stories from anyone who's actually fine-tuned Mamba+MoE hybrids (Nemotron, Jamba, Mixtral if relevant) and can tell me where it went sideways Papers I might be missing on multi-task LoRA on sparse MoE specifically — most of the multi-task literature I've found assumes dense Pitfalls around router gradients under low-rank adaptation Whether the standard LoRA rank sweet spots (8-32) still hold, or if MoE+Mamba shifts what works Happy to write up what I find — first-time projects produce useful negative results even when they fail, and there's basically no public writeup yet on solo-developer-scale Nemotron 3 fine-tuning. submitted by /u/retarded_770 [link] [comments]
View originalNew fear unlocked: Claude can run Bash tool with dangerouslyDisableSandbox when it wishes to do so
I’ve been using the new Auto mode in Claude Code (where CC decides whether to approve tool calls rather than you having to approve one by one or using the --dangerously-skip-permissions mode). This thing is supposed to be a middle ground between those two, and overall it’s actually been pretty neat! The main annoyance I’ve seen is that it can block perfectly valid commands, that is, when you really want the model to delete stuff (imagine a code refactoring or cleaning up something in your computer, like my uninstall here). In this case, I expected it to deny the request and make me switch to approval mode so I could allow it manually. But when I checked back, I saw Auto mode had in fact denied the file removal, and Opus still went ahead and called the Bash tool with the rm -rf command and dangerouslyDisableSandbox: true, deleting the files anyway. Later when I asked how did it do that, it told me that it’s done that because it would trigger a permission prompt for me, but it didn't, because in Auto mode no permission prompts come out (that’s the whole point of Auto mode!), so it literally believes it was requesting me for approval and I granted, when that never happened due to its own Auto model mechanism. Not sure what you guys think, but to me that's a big red flag! Not the Auto mode itself, but the fact that the model is able to call the Bash tool with sandboxing turned off, be on Auto mode or not. I'm curious if people are using Docker or another type of rig to reduce the blast radius of this thing. submitted by /u/somerussianbear [link] [comments]
View originalTrained Qwen 3.5 2B for pruning tool output in coding agents / Claude Code workflows
Agents can spend a lot of context on raw pytest, grep, git log, kubectl, pip install, file reads, stack traces, etc., even though usually only a small block is actually relevant. I built a benchmark for task-conditioned tool-output pruning and fine-tuned Qwen 3.5 2B for it with Unsloth. The benchmark combines real SWE-bench-derived tool observations with synthetic multi-ecosystem examples. Held-out test results: 86% recall 92% compression Beats other pruners and zero shot models (+11 recall over zero-shot Qwen 3.5 35B A3B) You can put squeez in front of tool output before the next reasoning step, or add it to something like CLAUDE md as a lightweight preprocessing step. You can serve it with vLLM or any other OpenAI-compatible inference stack. Everything is open source, check for details: - paper: https://arxiv.org/abs/2604.04979 - model: https://huggingface.co/KRLabsOrg/squeez-2b - dataset: https://huggingface.co/datasets/KRLabsOrg/tool-output-extraction-swebench - code: https://github.com/KRLabsOrg/squeez submitted by /u/henzy123 [link] [comments]
View originalSo, what exactly is going on with the Claude usage limits?
I'm extremely new to AI and am building a local agent for fun. I purchased a Claude Pro account because it helped me a lot in the past when coding different things for hobbies, but then the usage limits started getting really bad and making no sense. I had to quite literally stop my workflow because I hit my limit, so I came back when it said the limit was reset only for it to be pushed back again for another 5 hours. Today I did ask for a heavy prompt, I am making a local Doom coding assistant to make a Doom mod for fun and am using Unsloth Studio to train it with a custom dataset. I used my Claude Pro to "vibe code" (I'm sorry if this is blasphemy, but I do have a background in programming, so I am able to read and verify the code if that makes it less bad? I'm just lazy.) a simple version of the agent to get started, a Python scraper for the Zdoom wiki page to get all of the languages for Doom mods, a dataset from those pages turned into pdf, formating, and the modelfile for the local agent it would be based around along with a README (claudes recommendation, thought it was a good idea). It generated those files, I corrected it in some areas so it updated only two of the files that needed it, and I know this is a heavy prompt, but it literally used up 73% of my entire usage. Just those two prompts. To me, even though that is a super big request, that seems extremely limited. But maybe I'm wrong because I'm so fresh to the hobby and ignorant? I know it was going around the grapevine that Claude usage limits have gone crazy lately, but this seems more than just a minor issue if this isn't normal. For example, I have to purchase a digital visa card off amazon because I live in a country that's pretty strict with its banking, so the banks don't allow transactions to places like LLM's usually. I spend $28 on a $20 monthly subscription because of this, but if I'm so limited on my usage, why would I continue paying that? Or again, maybe I'm just ignorant. It's very bizarre because the free plan was so good and honestly did a lot of these types of requests frequently. It wasn't perfect, but doable and I liked it so much that I upgraded to the Pro version. Now I can barely use it. Kinda sucks. submitted by /u/New-Pressure-6932 [link] [comments]
View original[P] mlx-tune – Fine-tune LLMs on Apple Silicon with MLX (SFT, DPO, GRPO, VLM)
Sharing mlx-tune, a Python library for fine-tuning LLMs natively on Apple Silicon using Apple's MLX framework. It supports SFT, DPO, ORPO, GRPO, KTO, SimPO trainers with proper loss implementations, plus vision-language model fine-tuning (tested with Qwen3.5). The API mirrors Unsloth/TRL, so the same training script runs on Mac and CUDA — you only change the import line. Built on top of mlx-lm and mlx-vlm. LoRA/QLoRA, chat templates for 15 model families, GGUF export. Runs on 8GB+ unified RAM. Not a replacement for Unsloth on NVIDIA — this is for prototyping locally on Mac before scaling to cloud GPUs. GitHub: https://github.com/ARahim3/mlx-tune submitted by /u/A-Rahim [link] [comments]
View originalRepository Audit Available
Deep analysis of unslothai/unsloth — architecture, costs, security, dependencies & more
Unsloth uses a tiered pricing model. Visit their website for current pricing details.
Key features include: No-code web UI for easy model training and management, Support for running Google's Gemma 4 models, Ability to train and run Qwen3.5 Small and Medium LLMs, Support for NVIDIA's 4B and 120B models, MoE LLM training up to 12x faster with reduced VRAM usage, Local hardware utilization for enhanced performance and privacy, Customizable training parameters for tailored model performance, Multi-GPU support for scalable training solutions.
Unsloth is commonly used for: Training custom AI models for specific business needs, Fine-tuning pre-trained models for niche applications, Running large language models for natural language processing tasks, Developing AI-driven applications without extensive coding, Experimenting with different model architectures locally, Optimizing model performance for resource-constrained environments.
Unsloth integrates with: TensorFlow, PyTorch, Hugging Face Transformers, Kubernetes for orchestration, Docker for containerization, Google Cloud for additional resources, AWS for scalable storage and compute, MLflow for experiment tracking, Weights & Biases for performance monitoring, Jupyter Notebooks for interactive development.
LM Studio
Project at LM Studio
1 mention
Unsloth has a public GitHub repository with 63,241 stars.
Based on 11 social mentions analyzed, 9% of sentiment is positive, 91% neutral, and 0% negative.